Create a Dataset from a View of Data Connections
You can create a dataset from a view of one or more of your existing data connections. This allows you to use Spark SQL to create a new dataset by selecting only the fields you want from existing data connections, as well as being able to perform other more complex transformations during the process. This can be useful when a specific collaboration has different requirements for field names, field types, or formats (plaintext vs. hashed) than your data possesses at source.
Note
Creating a dataset from a view of data connections is in limited availability. To see whether you can have this workflow enabled, contact your LiveRamp account team.
For example, you may have multiple transaction data pipelines across different product lines which your partner’s questions expect to be combined as one transaction dataset for measurement use cases. Creating a dataset from a view of these data connections allows you to join these transaction datasets together within LiveRamp Clean Room to create a single dataset for use in your partner’s clean room.. Connecting your datasets as they exist in your systems already removes potential friction (IT approvals, resource asks, legal reviews, etc.) from the process of getting up and running with your partners.
Other common examples include re-formatting particular fields from your data dictionary to match the format expected by your partners’ questions. For example, you may have transaction timestamps in “YYYY-MM-DD hh:mm:ss” format, when your partner expects “DD-MM-YYYY hh:mm:ss”. Rather than creating a whole new data feed for this partner, you can apply this transformation to your data connection by creating a view of the data connections using SQL and assigning the resulting dataset to your partner’s question.
Note
Datasets from views can only be used in Hybrid and Confidential Computing clean rooms.
All data connection types are supported except for Iceberg Catalog and CSV Catalog.
Datasets that contain RampIDs cannot currently be used to create a dataset from a view.
When selecting multiple data connections to be used to create the view, all data connections must be of the same data connection type (such as Snowflake Table, Client AWS S3, or Google Cloud Storage(with SA)).
Once you’ve created a view from a data connection, you can provision the resulting dataset to your desired Hybrid or Confidential Computing clean rooms and use that dataset in questions.
To create a dataset from a view of data connections:
From the navigation menu, select Clean Room → Data Connections to open the Data Connections page.
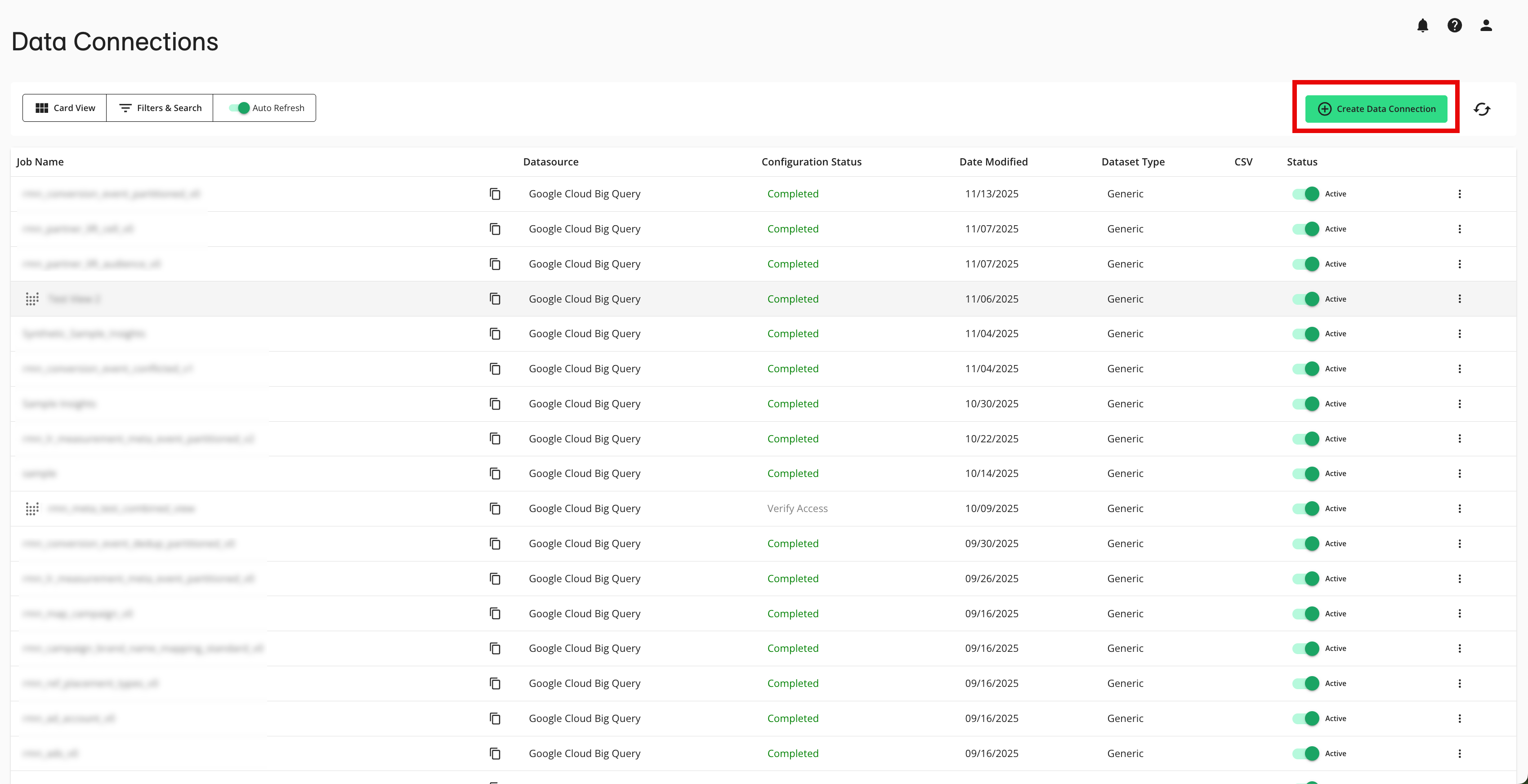
From the Data Connections page, click .
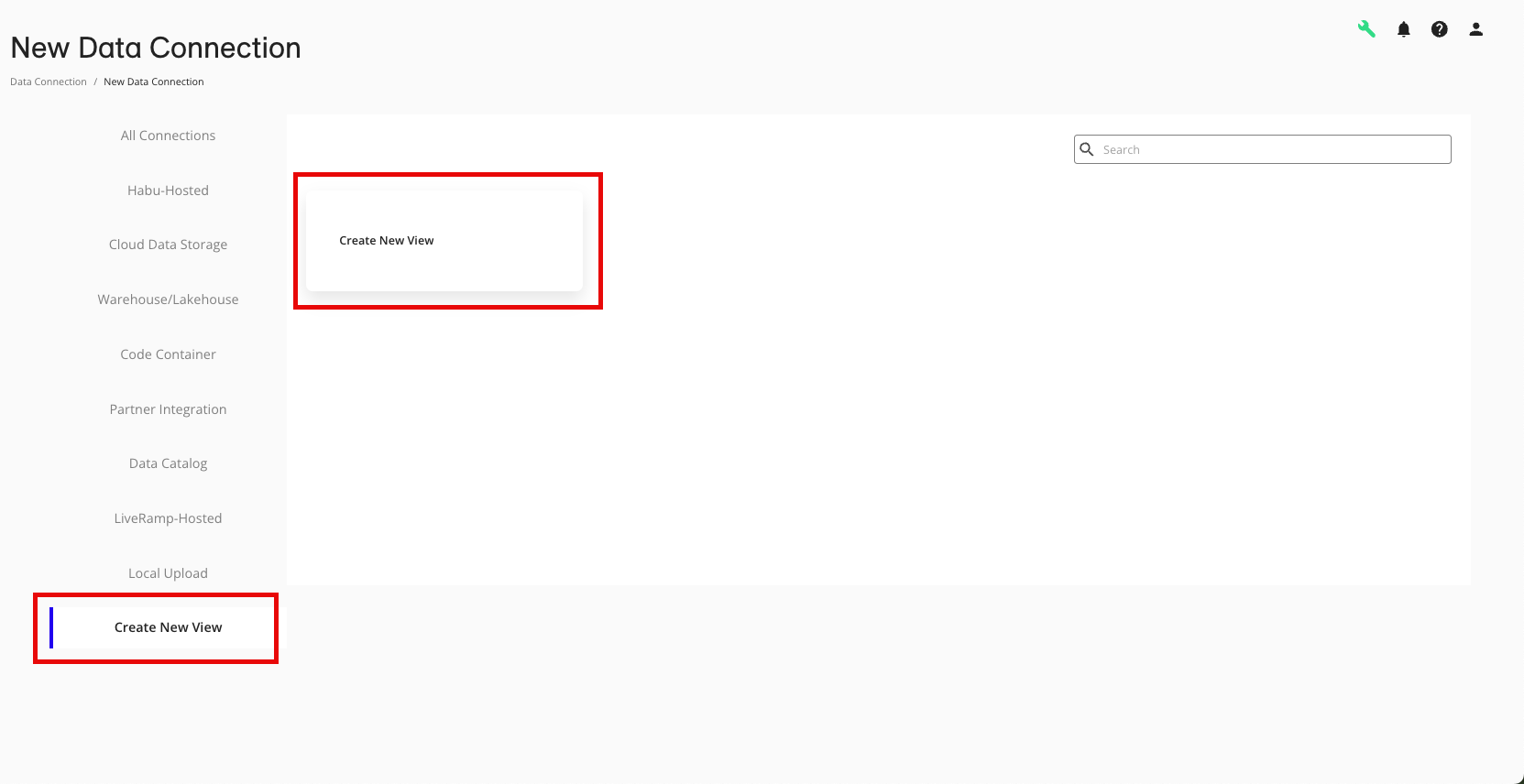
From the New Data Connection page, select the Create New View tab and then select the “Create New View” tile.
From the Create Dataset From View screen, make the appropriate selections and then click :
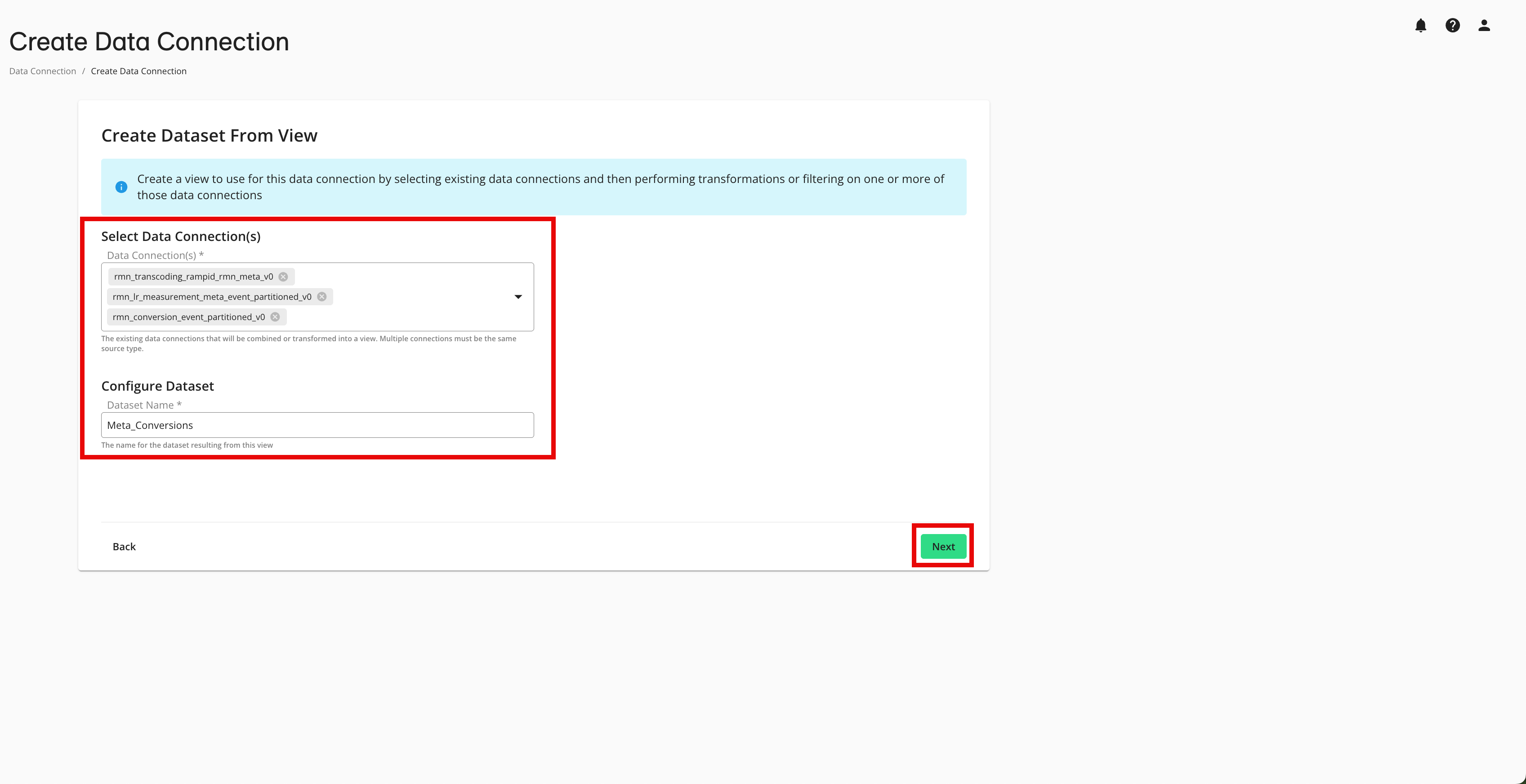
Select the existing data connections that you want to use to create the view.
Note
If you select multiple data connections, all data connections must be of the same type (such as Snowflake Table, Client AWS S3, or Google Cloud Storage(with SA)).
Enter a name for the dataset to be created from this view (names must start with a letter and can only contain letters, numbers, and underscores).
The SQL editor page opens. The data connections now appear under “Selected Data Connections” and the SQL editor is prepopulated with the code to create the view using the view name entered in the previous step.
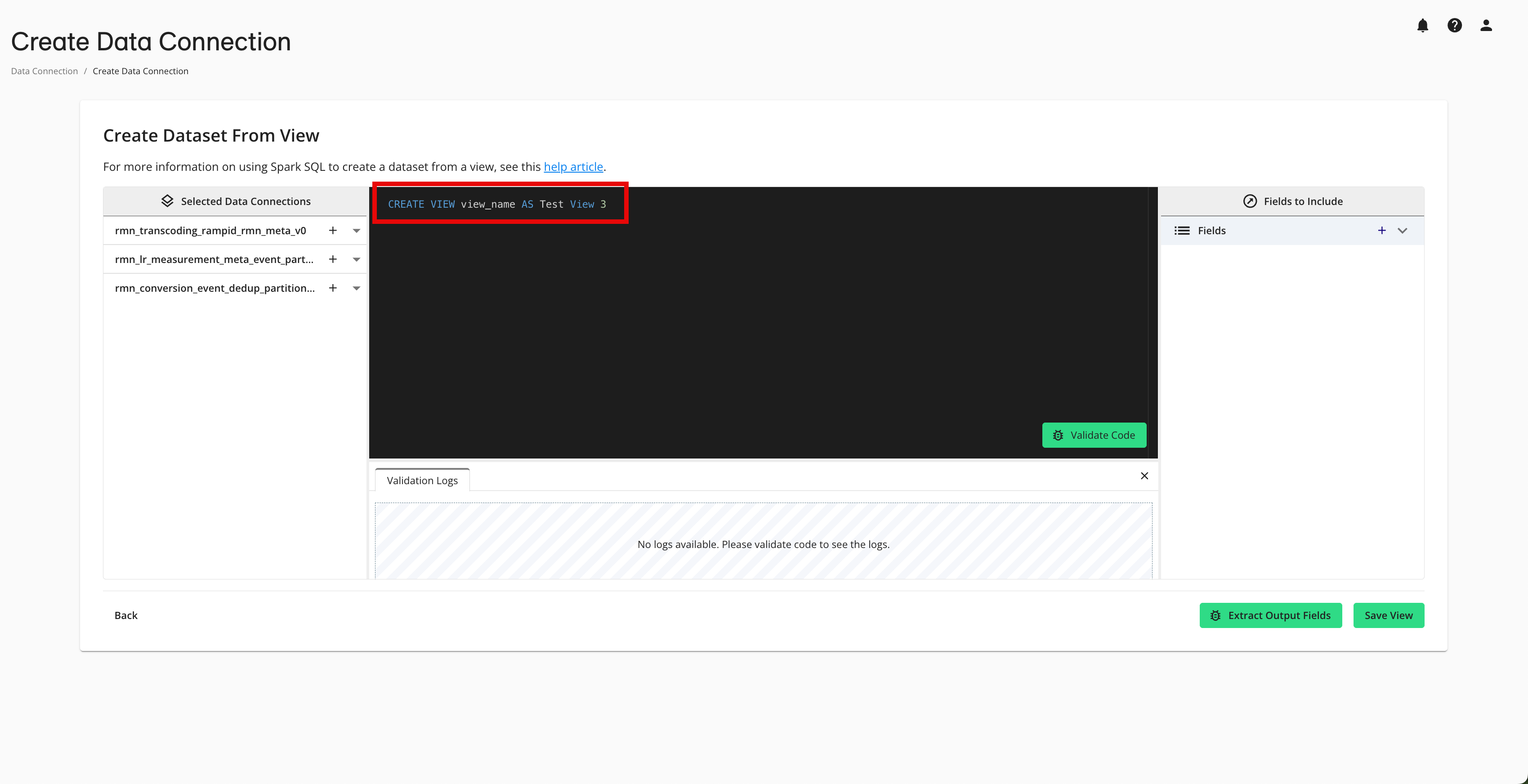
Note
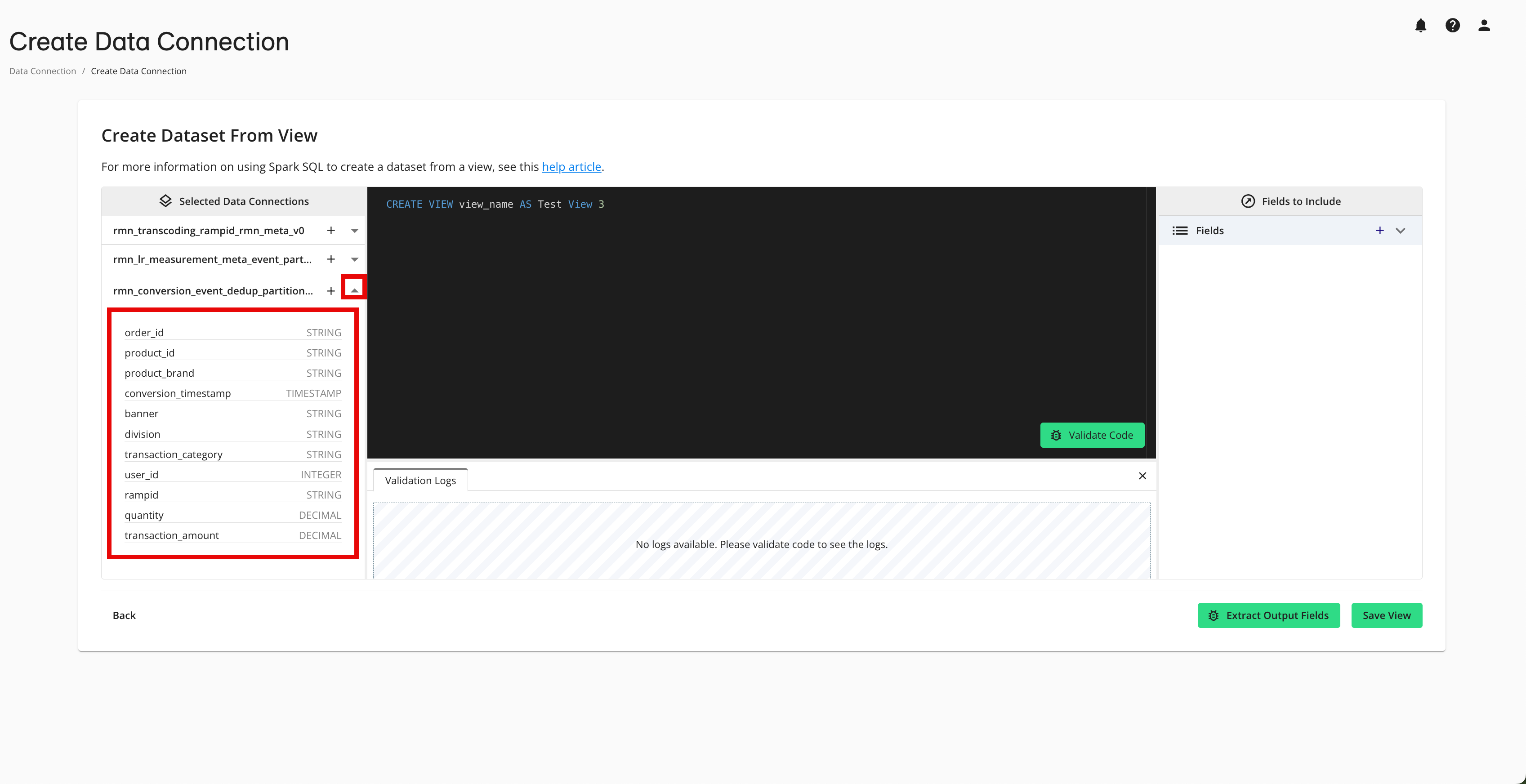
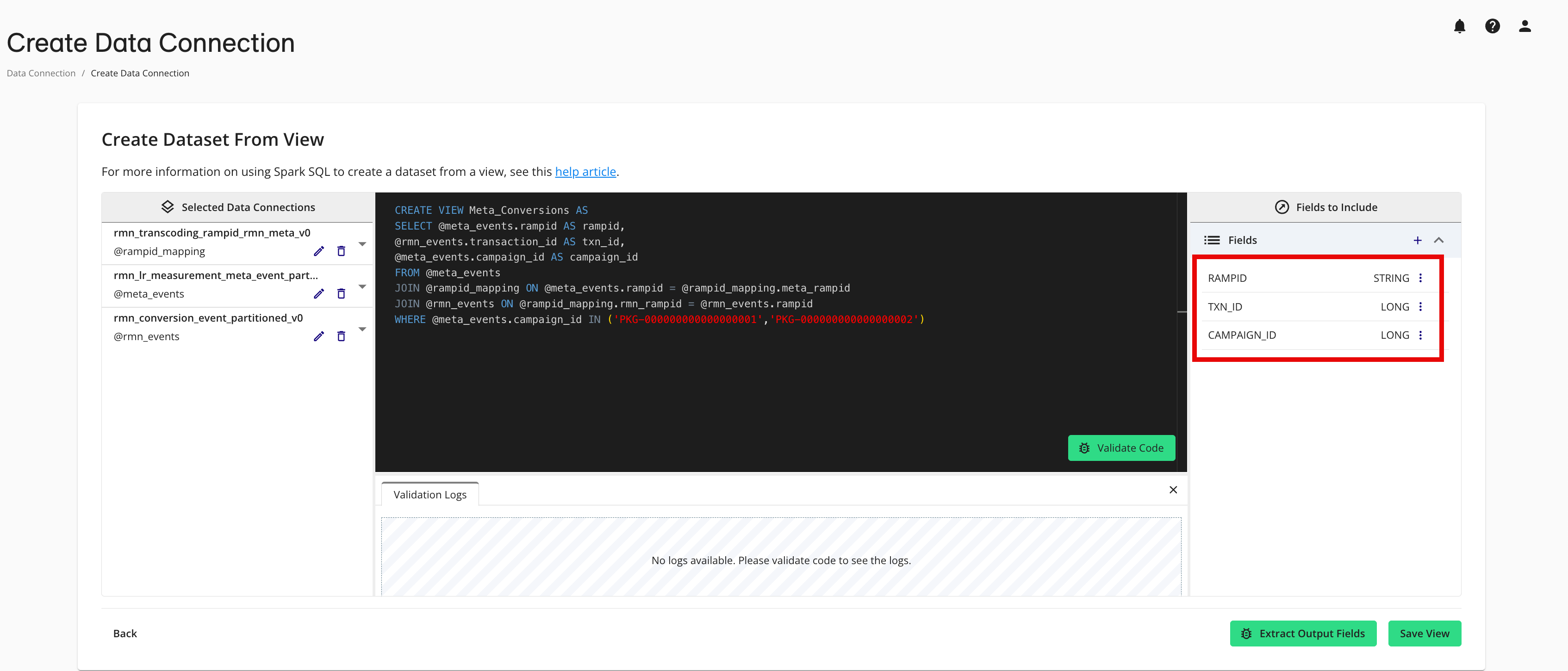
You can click the caret to the right of the data connection name to display a list of the dataset fields and their field types.
Add the appropriate macro for each data connection:
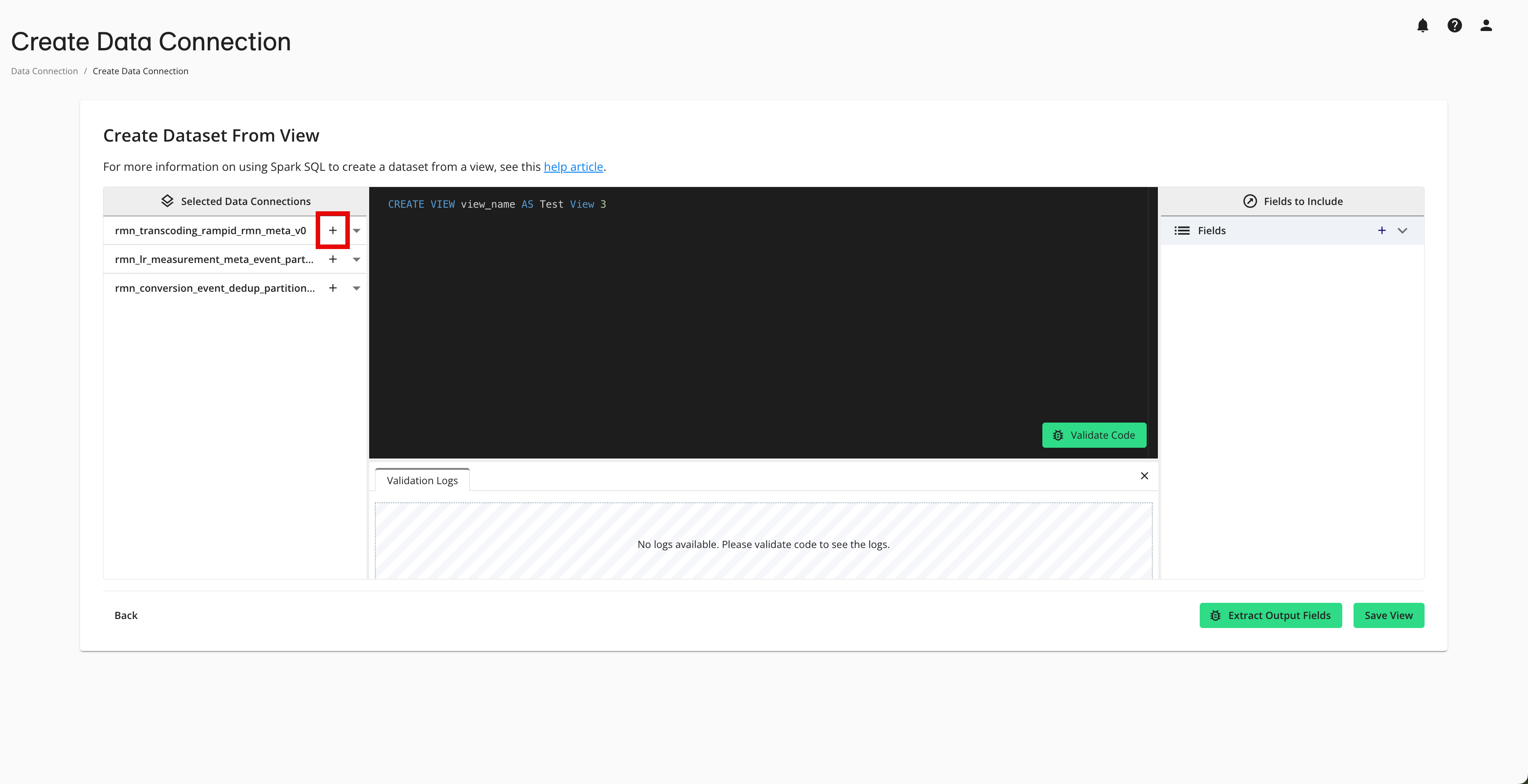
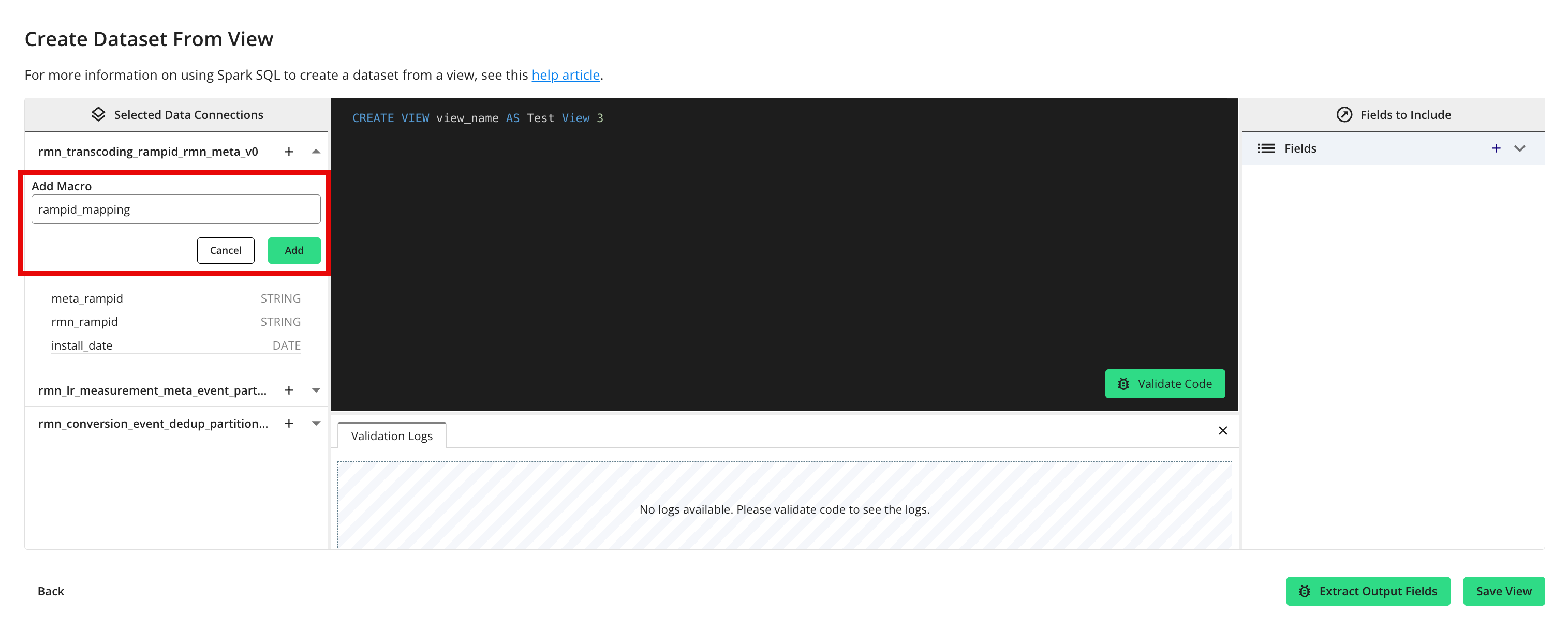
Click the plus sign (“+”) next to the data connection name.
Enter the appropriate dataset macro in the “Add Macro” field.
Click .
Paste or enter the rest of your Spark SQL into the code editor.
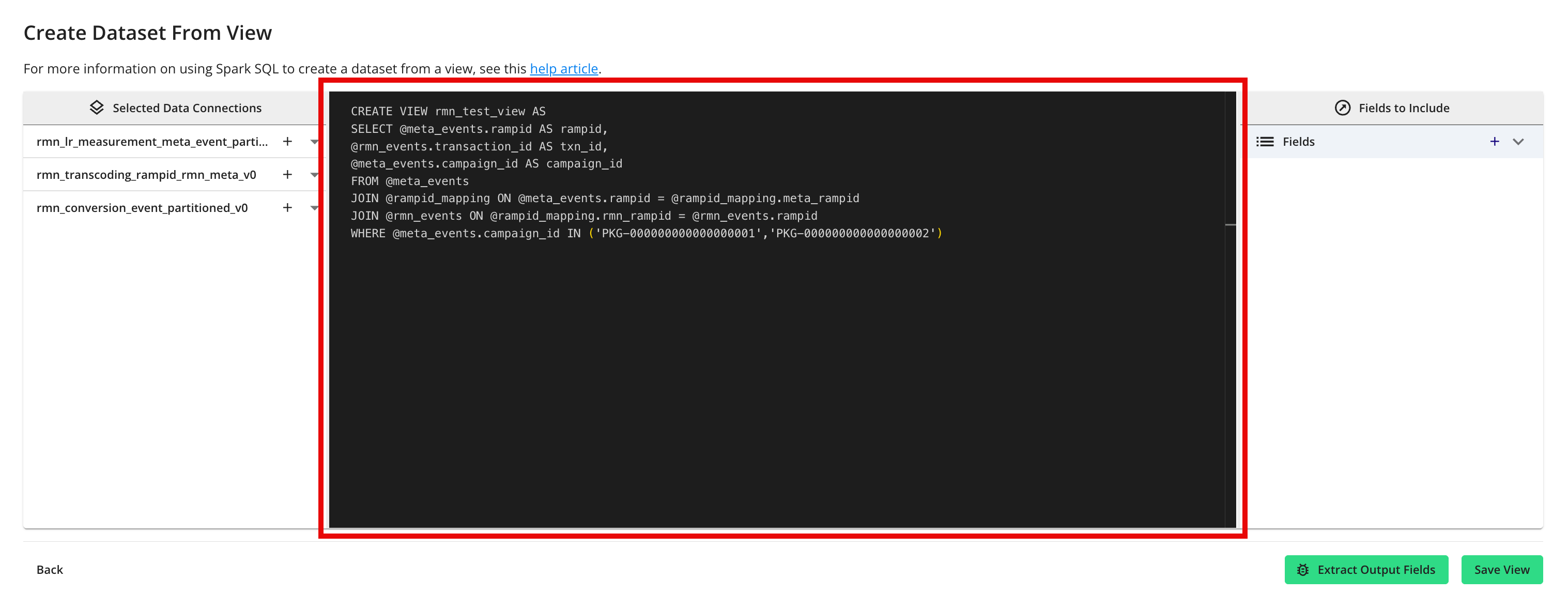
Note
The first line of the query must start with “CREATE VIEW {dataset name} AS”.
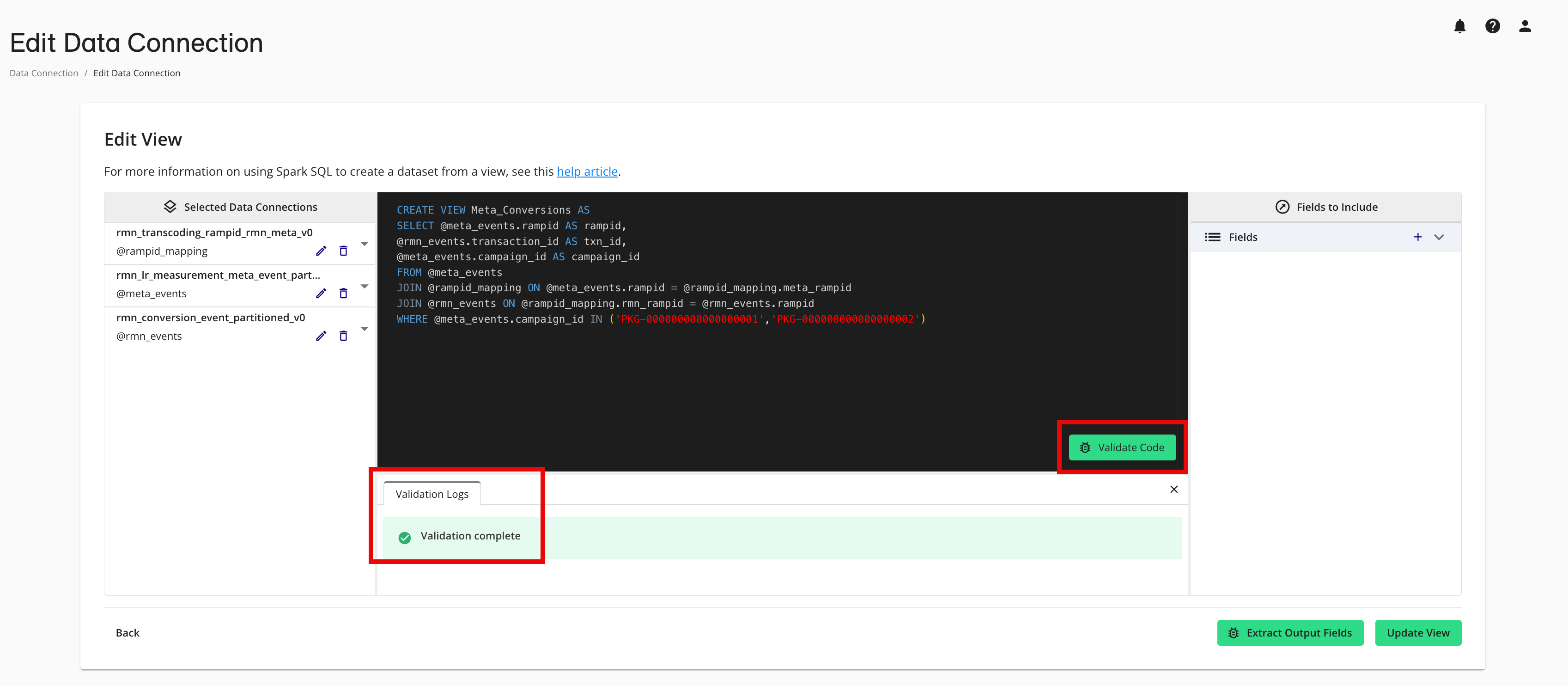
If desired, perform validation on the SQL code by clicking to ensure your view creation will succeed downstream.
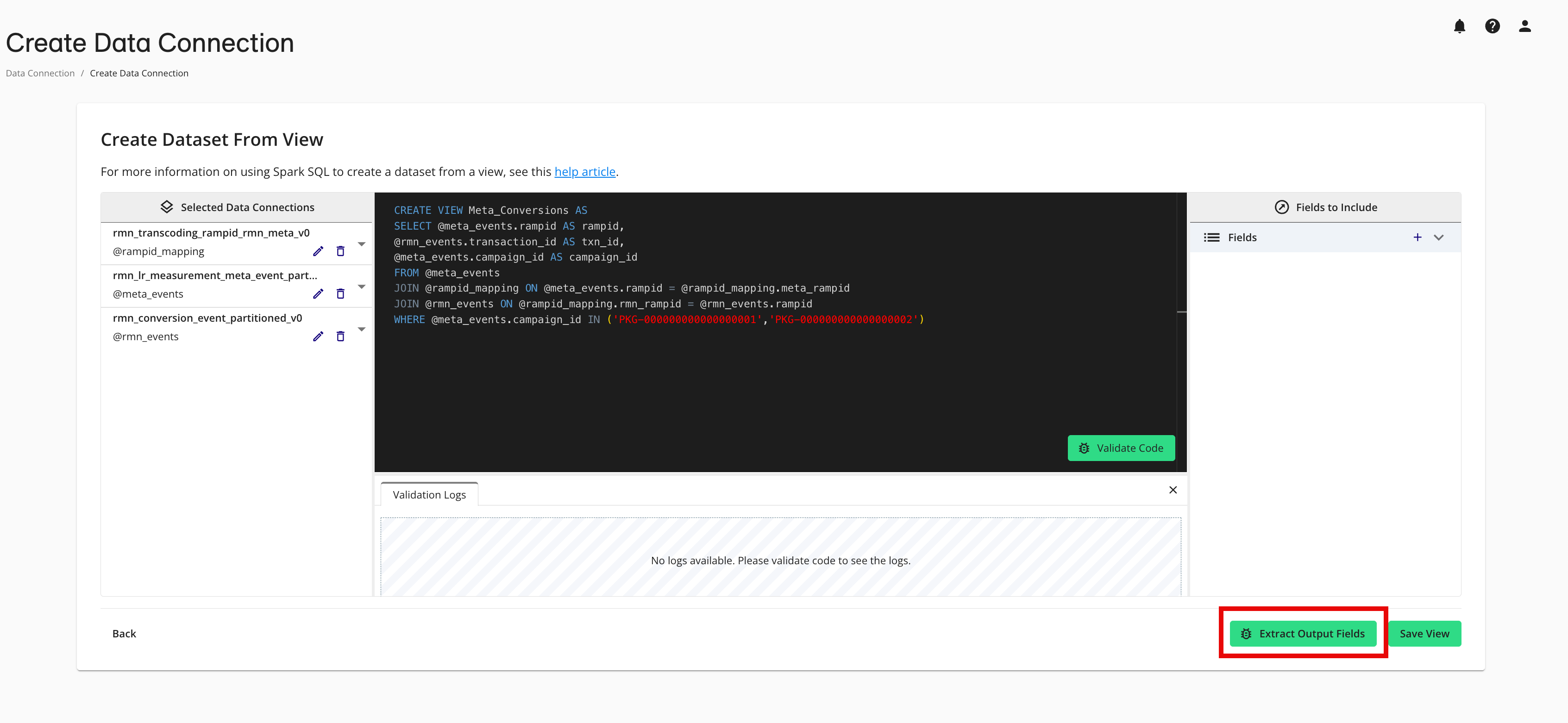
Click to extract the fields that will be included in the dataset.
Click .
The dataset now appears on the Data Connections page with a View icon (
 ) next to the name and a configuration status of “Mapping Required”.
) next to the name and a configuration status of “Mapping Required”.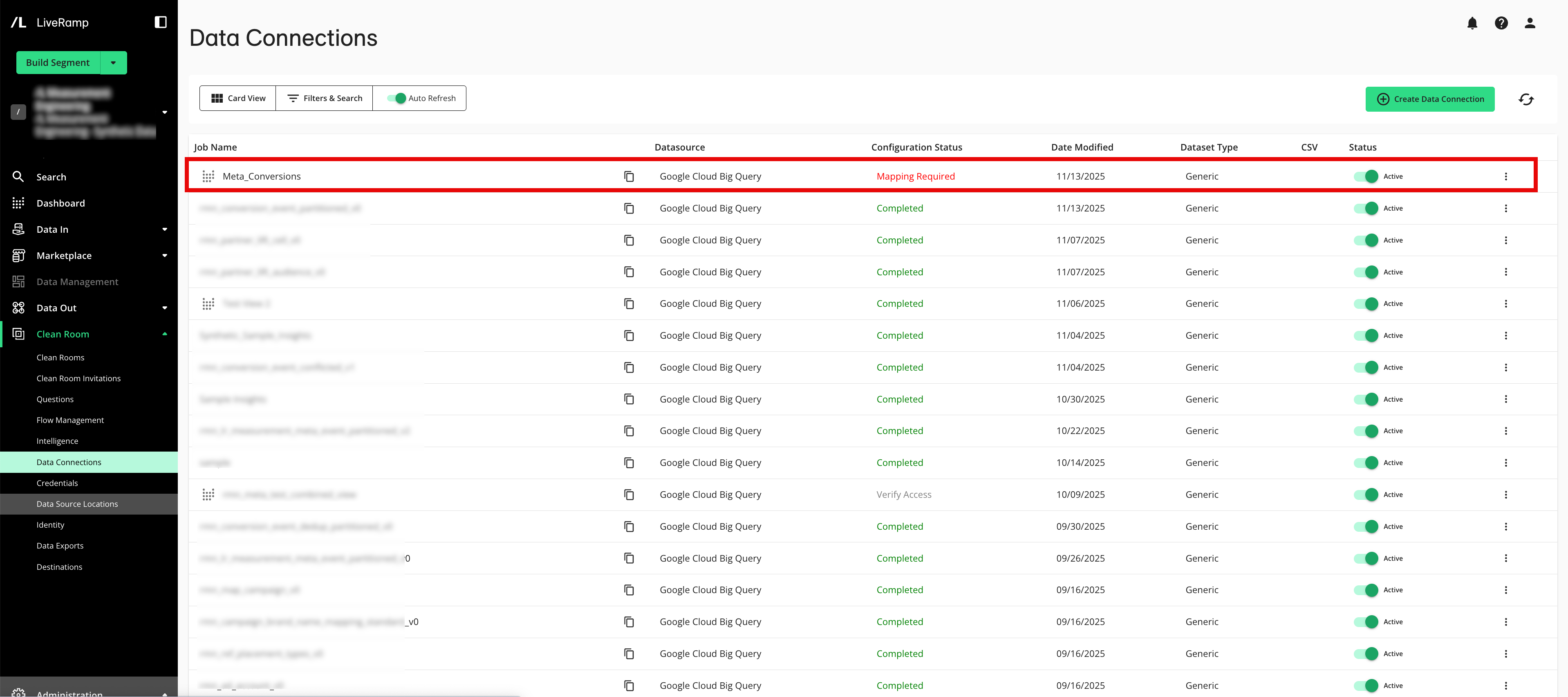
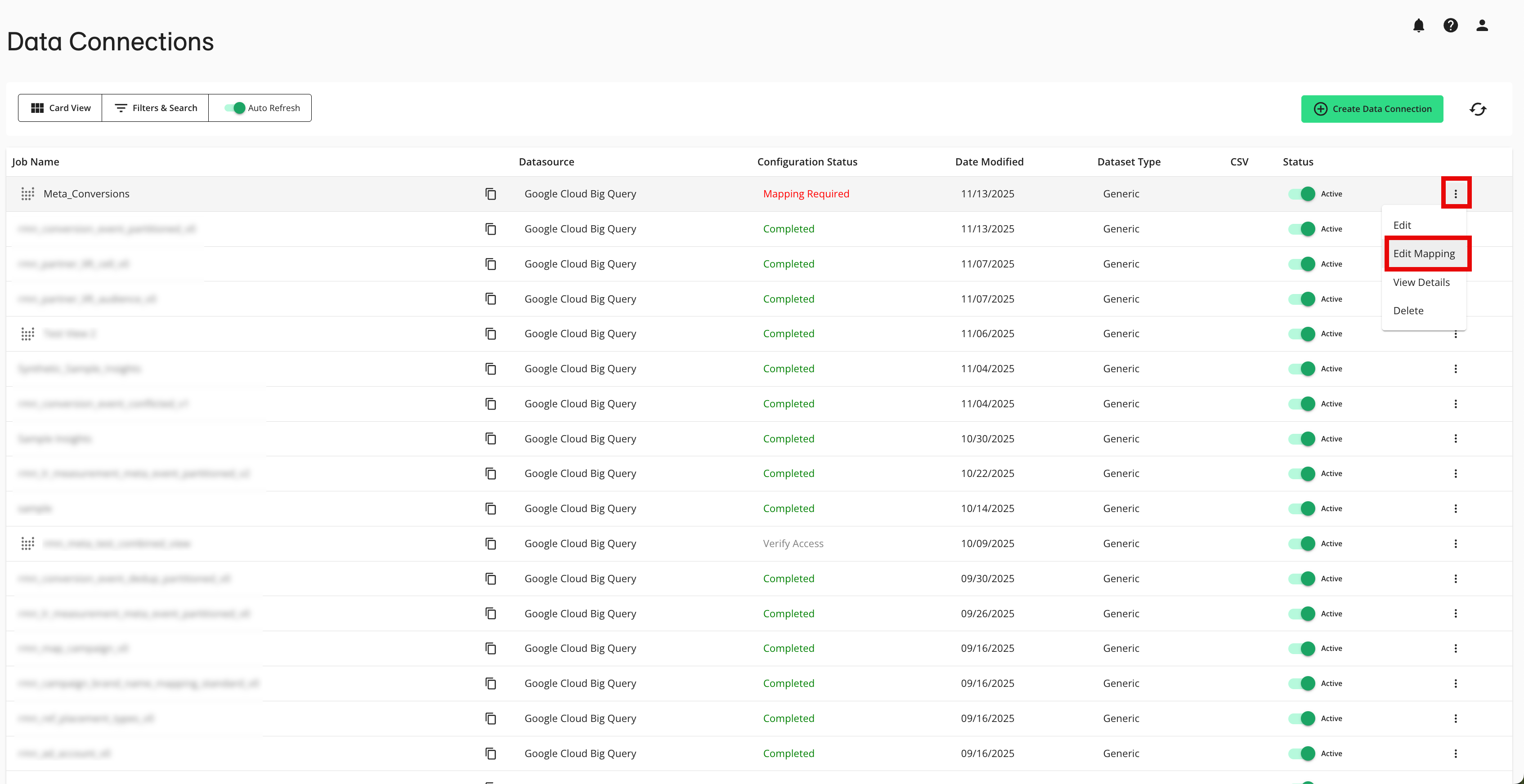
From the Data Connections page, click the More Options menu in the row for the new data connection and select .
From the Add Metadata screen, make the appropriate settings and then click :
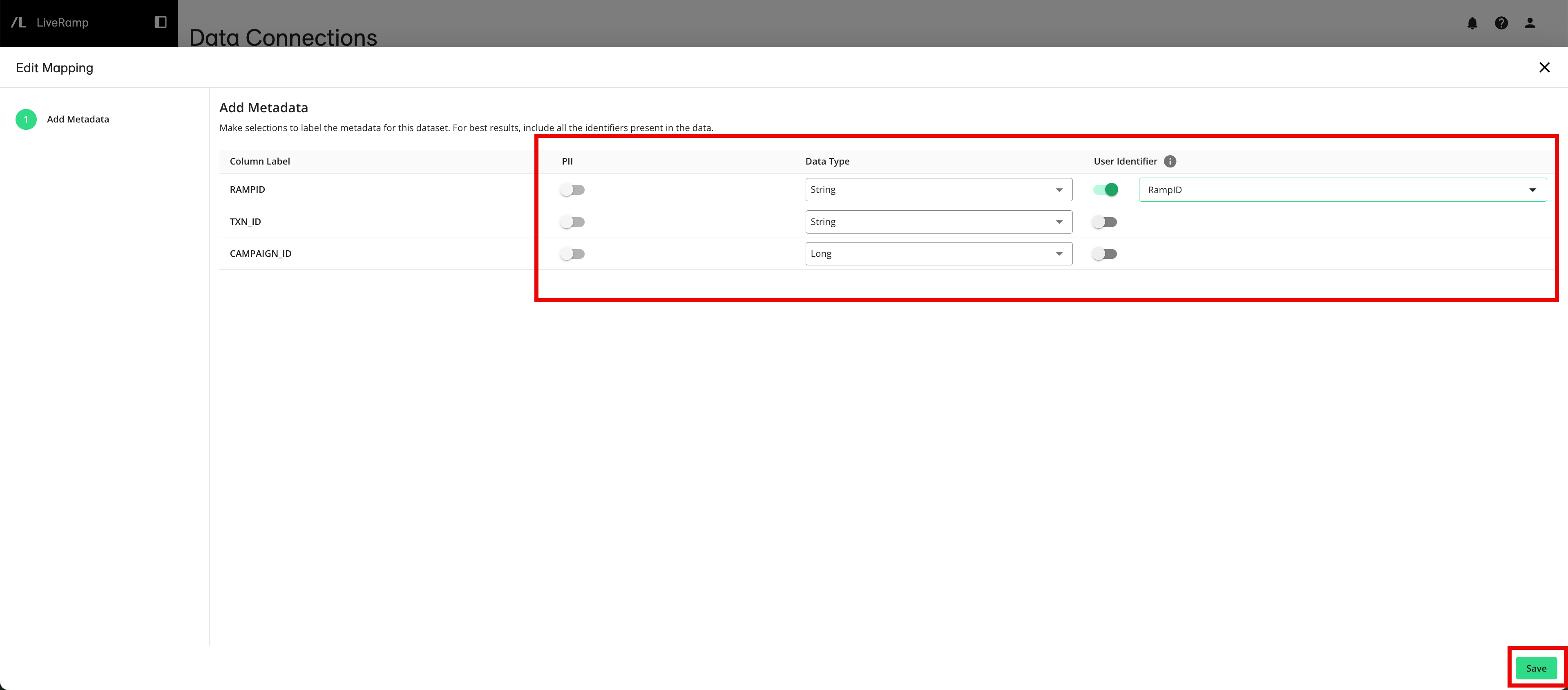
For any column that contains PII data, slide the PII toggle to the right.
Make any needed adjustments to the field type for each column.
Specify at least one user identifier by sliding the User Identifiers toggle to the right.and then selecting the appropriate user identifier type.
The configuration status changes to “Completed”.
You can now provision this dataset to any of the Hybrid or Confidential Computing clean rooms you want to use it in and then use this dataset in questions in those clean rooms.