File Output Options for File-Based Recognition Workflows
When you upload a file into our File-Based Recognition (FBR) workflow for measurement use cases, LiveRamp replaces the input identifiers (such as PII, cookies, mobile device IDs, and CIDs) with their associated RampIDs and returns the file to the location you specify. Unlike files that go through our Onboarding workflow, LiveRamp does not ingest any identifiers or segment data and does not create segments in an FBR workflow. For this reason, you can think of the FBR workflow as “file in, file out”.
Note
FBR output files are often (but not solely) used for measurement and analytics, and are usually delivered back to you or to a measurement partner.
There are two output options available for FBR files:
One RampID per record
All available RampIDs per record
Note
The output option you choose is applied at the LiveRamp audience level, so that all files going through a given audience will have the same type of output (one RampID or all RampIDs).
In many situations, receiving all RampIDs is preferable. However, there are some situations where you might prefer to receive one RampID per record.
RampID Versions You Might Receive in Files
Whether you choose to receive one or all RampIDs per record, there are two versions of RampIDs you might receive: maintained RampIDs and derived RampIDs.
Maintained RampIDs
If we have a maintained record for the input data in our Identity Graph, we'll return a maintained RampID. A maintained RampID represents a person that LiveRamp can fully recognize. Multiple devices can usually be associated with a given maintained RampID. Maintained RampIDs are 49 characters long and start with "XY."
Derived RampIDs
If we do not yet have a maintained record for the input data in our Identity Graph, we'll generate derived RampIDs for each PII touchpoint (name and postal address, email address, phone number) for that input record. In addition, even for records where we have a maintained RampID there might be certain PII touchpoints that we haven’t yet confidently tied to that record, so we’ll generate derived RampIDs for those touchpoints as well.
Why Records Might Have Multiple RampIDs
In an ideal marketing world, LiveRamp would always have all PII touchpoints merged to a single individual. In reality, LiveRamp often manages multiple RampIDs for an individual.
This is because people are dynamic: they move houses, change jobs, switch phones, share computers, and upgrade their tech. In the U.S., in 2018 alone, there were 36 M residential moves, 4 M births, 2.2 M marriages, and almost 800 K divorces. Each of these events might create a new PII touchpoint. When we observe a new piece of PII, we create a RampID for that touchpoint.
Over time, each of these events builds a more complete picture of that person’s identity. But until we are able to confidently recognize and prove that these new PII touchpoints are tied to that one individual, we might associate multiple RampIDs with that individual’s data. Once we have a high degree of confidence that the new touchpoints are tied to that individual, we merge those RampIDs into a single maintained RampID.
Thanks to our massive online and offline footprint, we are able to successfully do this more accurately and faster than any alternative.
Multiple RampID Example
For example, say you’re targeting men in Boulder, CO with an email campaign. Email addresses for Bill Jenkins, Billy Jenkins, and William Jenkins appear separately in your targeting file.
Within our graph, each email address has its own RampID (example: XY123, XY456, Xi789). As we observe some common linkages across the three RampIDs (e.g., name and postal address, phone), over time, LiveRamp will learn that Bill, Billy, and William are the same person.
Receiving One RampID Per Record
In some cases, like attribution, where accuracy and precision are the biggest concerns, it might be preferable to choose to receive one RampID per record.
For this option, LiveRamp auto-selects one consistent RampID per individual from our Identity Graph. When available, the maintained RampID is selected.
When there are multiple maintained RampIDs associated with the record, one is selected at random and used consistently.
If there are no maintained RampIDs associated with the record, the derived RampID is selected. When no maintained RampID is available and there are multiple derived RampIDs associated with the record, we select one of them in a consistent and repeatable way.
Receiving All RampIDs Per Record
Having multiple RampIDs per record creates a more accurate view of the digital world and the consumer. This is because devices can be shared, and many people have multiple email addresses, home addresses, and workplace addresses. Today, clients need to link multiple data sets across the offline and online worlds, and receiving multiple RampIDs Increases overlap rates across data sets.
Reach is a critical marketing metric - brands, agencies, publishers, and platforms need to be able to measure and prove reach delivery. Multiple RampIDs help clients meet their reach and frequency measurement requirements without a major degradation in accuracy.
Note
Work with your LiveRamp technical support team to ensure smooth delivery of multiple RampID files.
Discuss pricing implications with your LiveRamp Account Executive/Account Director.
Choosing a Grouping Indicator for Multiple RampID Files
Once we match your records to all the RampIDs we associate with each particular record in your file, we create one row per associated RampID and randomize the row order. To enable you or your measurement partner to tie together all the RampIDs associated with each input record, you need a way to group those associated rows.
Our preferred method to accomplish this is through a LiveRamp grouping indicator that we generate and add to the file. The LiveRamp grouping indicator is a hashed number that corresponds to an input row. For privacy reasons, it cannot be tied back to the actual input row number, but it allows you or your measurement partner to be able to group the RampIDs by input row. Here’s an example of what the output file would look like when using a LiveRamp grouping indicator.
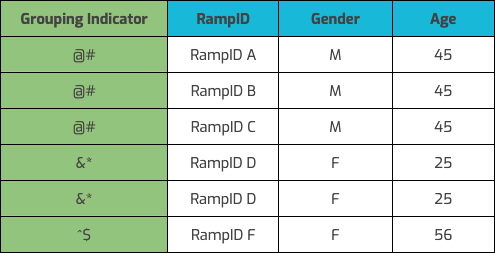
Note
It is not recommended, but if you prefer, you can also provide your own unique input column (for instance a client ID or transaction ID) in the input file, which we will use as a grouping indicator and then hash before returning. Talk to your LiveRamp representative if you want to provide your own grouping indicator.
Tying Multiple Files Together
In order to tie disparate datasets together, use the RampIDs column.
Note
If you opted for the LiveRamp-provided grouping indicator column, we cannot guarantee that the order of the grouping indicator will be the same across different files even if the input identifier is the same. This is because we randomly shuffle the output row order for privacy reasons.
Also, to comply with privacy and data ethics requirements, a different hash will be used for every file.
FAQs
Due to the complexity of the ecosystem and the multiplicity of touchpoints for a single person, it is often hard to resolve all person-level and device-level touchpoints to a single RampID with certainty. Therefore, the Identity Graph contains more than one RampID for a person until such time as we can consolidate with a high degree of confidence.
When we observe a new piece of PII, we create a RampID for that touchpoint.
LiveRamp’s foundational system for resolving offline Identities, AbiliTec, performs the role of determining which pieces of personally identifiable information (PII) represent a “person.” Thus there are times when a client’s CRM data considers multiple pieces of PII to be the same when AbiliTec does not yet see sufficient evidence to merge them. This will allow us to maintain our verification standards, while delivering higher match rates within a client’s CRM data, maximizing reach.
In addition, our Online Identity Graph might contain several derived RampIDs for a given email touchpoint because we typically have a different derived RampID for each of the three email address hash types in our graph.
One offline identifier (i.e., an email address) can be tied to more than one RampID because email addresses can be shared and therefore could be associated with several names and postal addresses (NAP). For instance, a family email address could be associated with the NAP of the parents and the NAP of the son who moved out to go to college.
One online identifier (i.e., a cookie) can be tied to more than one RampID because we have shared devices. For instance, if a computer is shared by multiple people and they use different emails and PII but might still keep sessions open, cookies can be associated with more than one piece of an identifier and therefore more than one RampID.
People are dynamic: They move houses, they change jobs, they switch phones, they share computers, they upgrade their tech, and they are exposed to marketing on the move across multiple channels.
The marketing ecosystem is dynamic: The multiplicity of marketing touchpoints - creatives/ impressions/channels/media - across multiple devices for every single person is complicated to disentangle and connect back to individuals.
It takes time to build a consolidated, complete view of an individual as LiveRamp/AbiliTec starts to recognize and prove the different PII touchpoints are accurately tied to one person. This is not instantaneous.
Merging (reducing the number of RampIDs per individual) happens only when there is a high degree of confidence that separate identifiers are tied to one person.
When AbiliTec sees the necessary validation to confidently tie new information to an existing offline profile, this information is updated and merged to the existing individual’s LiveRamp RampID.
Receive all RampIDs associated with a given touchpoint, such as a unique creative, message, email, call center contact, sales transaction.
Increased overlap rates across data sets
Better visibility across the customer journey
Alignment with activation/onboarding process, which already outputs multiple RampIDs
Greater consistency across LiveRamp use cases
...while maintaining confidence and accuracy within each RampID
In some cases, like attribution, it makes sense to choose a single ID. For instance, Google (through the Google Store Transaction product) requires a single ID to be returned to them.
Another reason is that some clients use RampIDs as database keys and do not necessarily need identity resolution.
Also migration to multiple RampIDs may be difficult or impossible for some clients to switch to, so we are maintaining both options.
When you run files through FBR and receive one RampID per record, you received a file with the same number of rows as the input rows, and one RampID per row. If you choose the option to have all RampIDs returned, you will receive an output file that still has one RampID per row, but where rows are duplicated if more than one RampID was found. You can optionally add a column to indicate how RampIDs should be grouped together. This grouping is based on which row the RampIDs came from. For privacy reasons, you will however not be able to tell which of the input row each grouping of RampIDs corresponds to, as we shuffle the row order.
In order to tie disparate datasets together, use the RampID column.
If you opted for the LiveRamp-provided grouping indicator column, we cannot guarantee that the order of the grouping indicator will be the same across different files even if the input identifier is the same. This is because we randomly shuffle the output row order for privacy reasons.
Also to comply with privacy requirements and data ethics considerations, a different hash will be used for every file
Upon completion of LiveRamp processing, the final step of data aggregation, joining RampIDs to individuals, will need to be performed