Connect to Data in an Artifact Store (For Clean Compute Questions)
You can connect to your data in an artifact store (such as in AWS, Azure, or GCS) so that you can connect to your code in a wheel package for Clean Compute questions.
Clean Compute is the mechanism for executing your custom Python code against your own data and partner data from within a clean room while respecting the architectural integrity of the clean room. Clean Compute enables multi-node processing via customizable Spark jobs when you run a Clean Compute question.
Note
Clean Compute is only available for Hybrid Confidential Compute clean rooms and Hybrid clean rooms.
To request the Clean Compute feature, contact your LiveRamp representative.
Each code artifact must be its own independent package: This means that if you wish to run independent jobs, these should each be included in their own artifact store data connection and should respect the above requirements.
For more information on Clean Compute, see "Clean Compute on Apache Spark".
Overall Steps
After you've completed the prerequisites, perform the following overall steps to configure an artifact store data connection in LiveRamp Clean Room:
After you've done these steps, you'll be ready to provision the associated dataset to the appropriate clean rooms (for more information, see "Clean Compute on Apache Spark".
Prerequisites
Before starting the process of connecting to your artifact store, make sure to perform the following steps:
Prepare the WHL package.
Validate the code with the synthetic validator.
For more information on performing these steps, see "Clean Compute on Apache Spark".
Add the Credentials
Determine where you want to store the Clean Compute Wheel package and place it in the appropriate bucket. This will be your artifact store for the Clean Compute package:
Amazon Web Services Simple Storage Service (AWS S3)
Azure Data Lake Storage (ADLS)
Google Cloud Storage (GCS)
From the navigation menu, select Clean Room → Credentials to open the Credentials page.
Click .
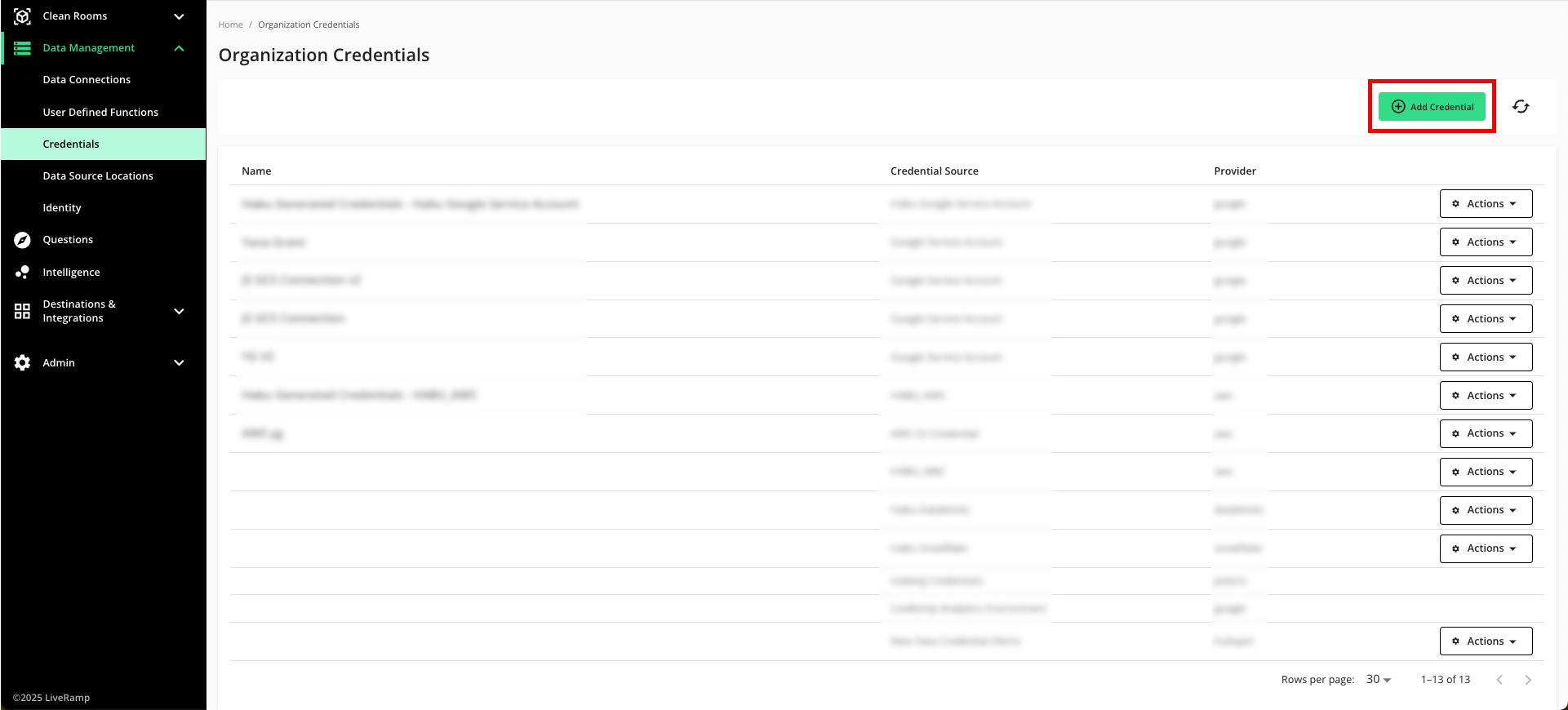
Enter a descriptive name for the credential.
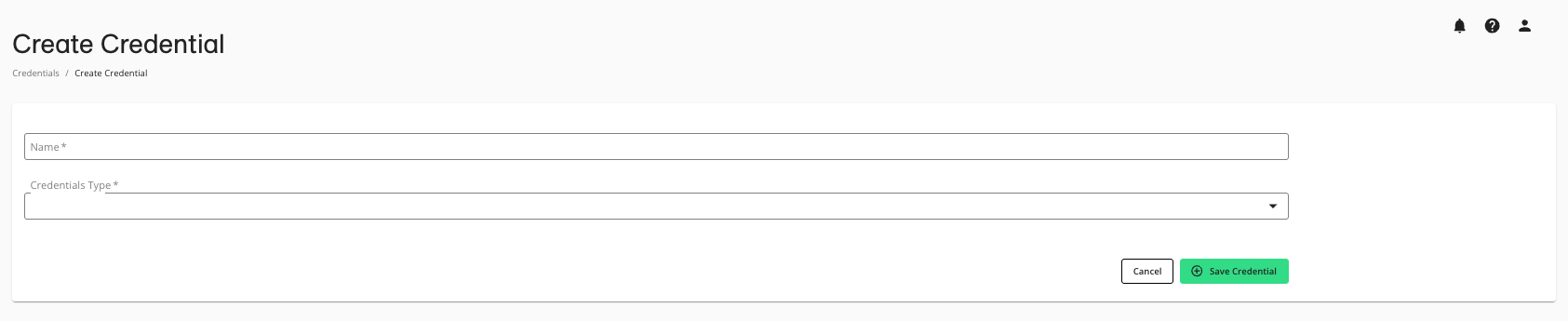
For the Credentials Type, select either GCS or S3 (depending on what you chose in step 1) for access to the artifact store.
Click .
Create the Data Connection
Note
You will need to create separate data connections for each Clean Compute wheel package that you want to use in questions.
From the navigation menu, select Clean Room → Data Connections to open the Data Connections page.
From the Data Connections page, click .
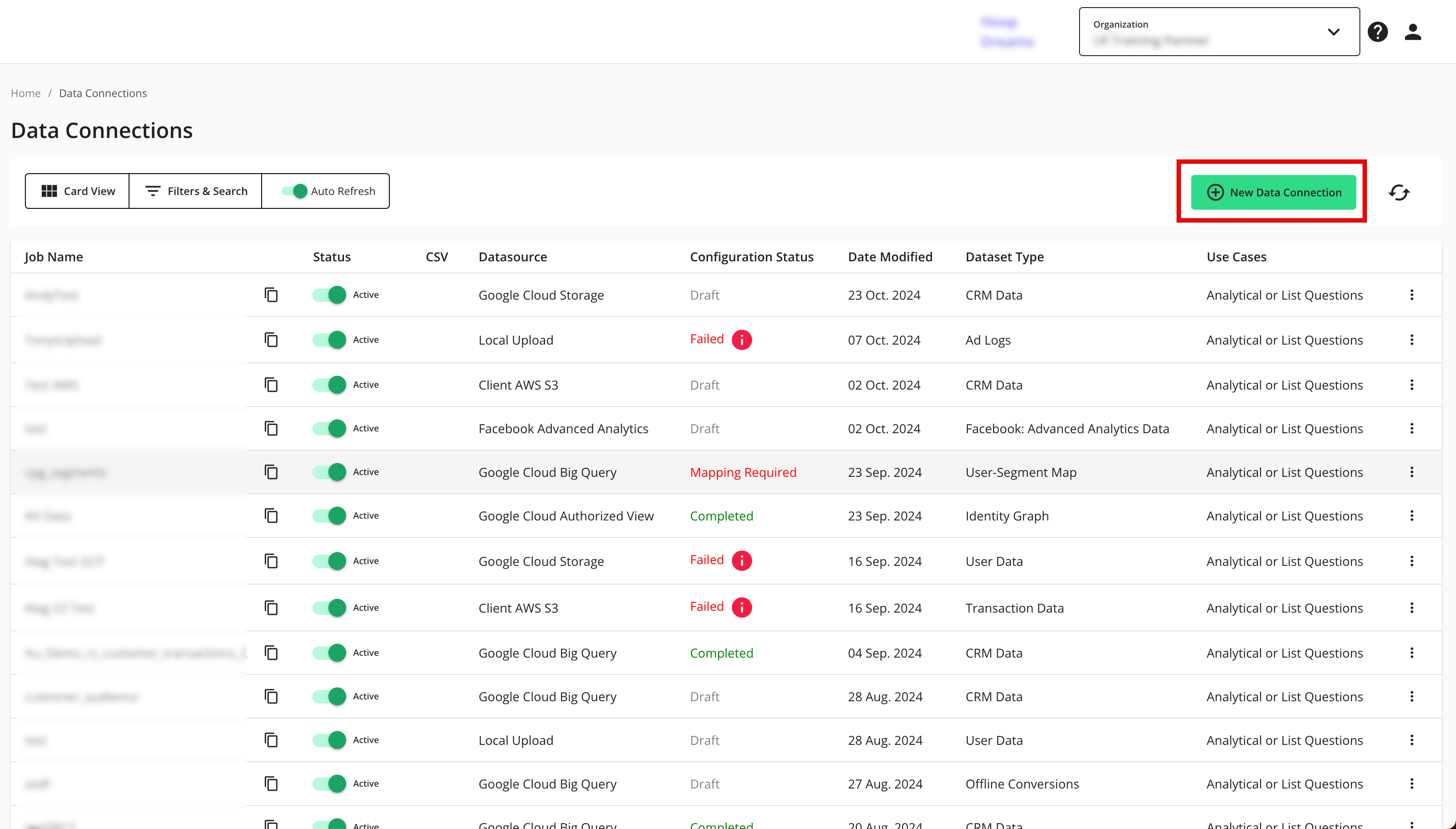
From the New Data Connection screen, select "Artifact Store".
Select the credentials you created in the "Add the Credentials" section above.
Complete the following fields in the Set up Data Connection section:
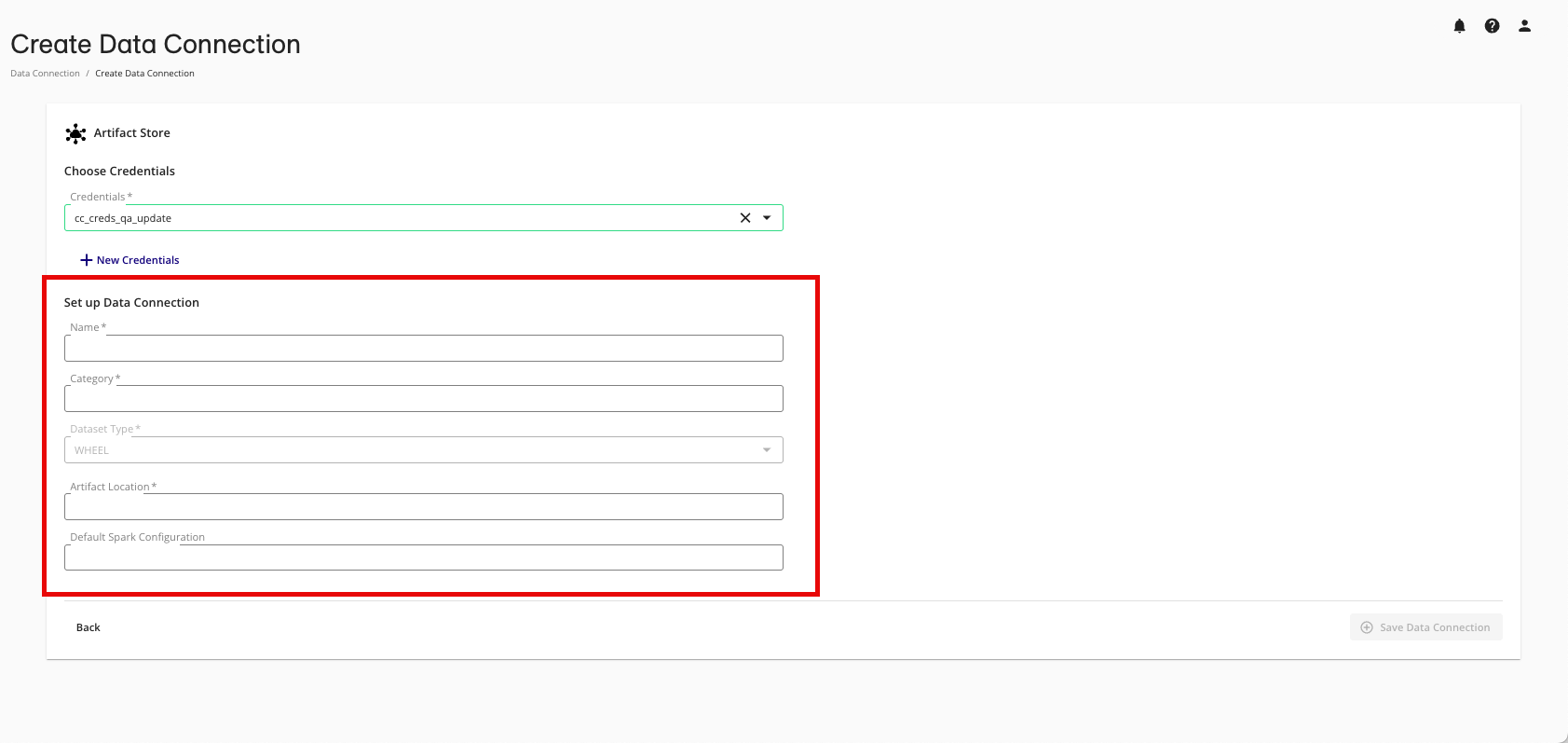
Name: Enter the name for the Clean Compute package when authoring questions.
Note
This name is displayed when assigning the "dataset" to the question.
Category: Enter a category of your choice.
Dataset Type: Select WHEEL.
Note
JAR files are not currently supported.
Artifact Location: Provide the bucket path for where the file will be stored.
Default Spark Configuration: If you would like to specify a default job configuration for questions using this data connection, this can optionally be included with comma-separated specifications. These are based on Spark configuration property documentation and can also be used to define environment variables.
An example format for this configuration is
spark.property_1=value;spark.property_2=value2.Note
The default configuration, if left blank, is a bare-bones configuration LiveRamp uses to execute the job.
Review the data connection details and click .
All configured data connections can be seen on the Data Connections page.
You're now ready to provision the associated dataset to the appropriate clean rooms.