How Connect Counts Unique Records
The count of unique records is the number of unique dataset members across all active files in a specific dataset. Unique records have been de-duped (if John Doe is in your file more than once, we only count him as one record) by means of the dataset key used for that dataset.
Unique records are complete (where John Doe has to have PII and segment data associated with him).
You can view your unique records in the Dashboard. Unique records are also used in calculating your monthly usage - see "Viewing Usage" for more information.
Note
In almost all cases, when we say "record" we mean a unique record.
Unique Records Calculation Example
Let's look at a hypothetical dataset with 5 rows of data, using email address as the dataset key:
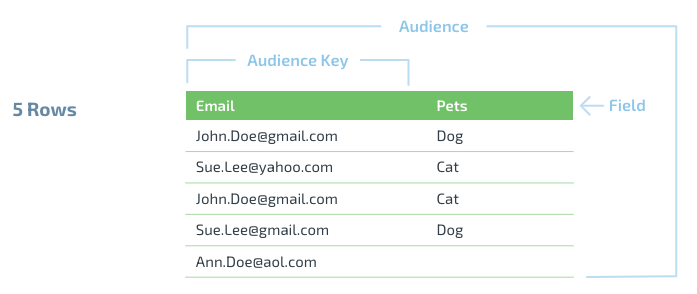
Both John Doe and Sue Lee have duplicate records. However, John Doe has the same email as the dataset key, whereas Sue Lee has different emails. Additionally, Ann Doe will not be registered as a record because she doesn’t have a field associated with her dataset key. Therefore, 5 rows end up as 4 records.

John Doe’s records are deduplicated, Sue Lee’s records are not, and Anne Doe’s are not counted. Therefore, 4 records end up as 3 unique records.
