Partition a Dataset in LiveRamp Clean Rooms
LiveRamp Clean Room enables you to optimize query performance by indicating partition columns for the datasets associated with your data connections. Data partitioning is the process of dividing a large dataset into smaller, more manageable subsets based on the values of one or more columns. In LiveRamp Clean Room, this process is done when you're creating the data connection and mapping the dataset's fields.
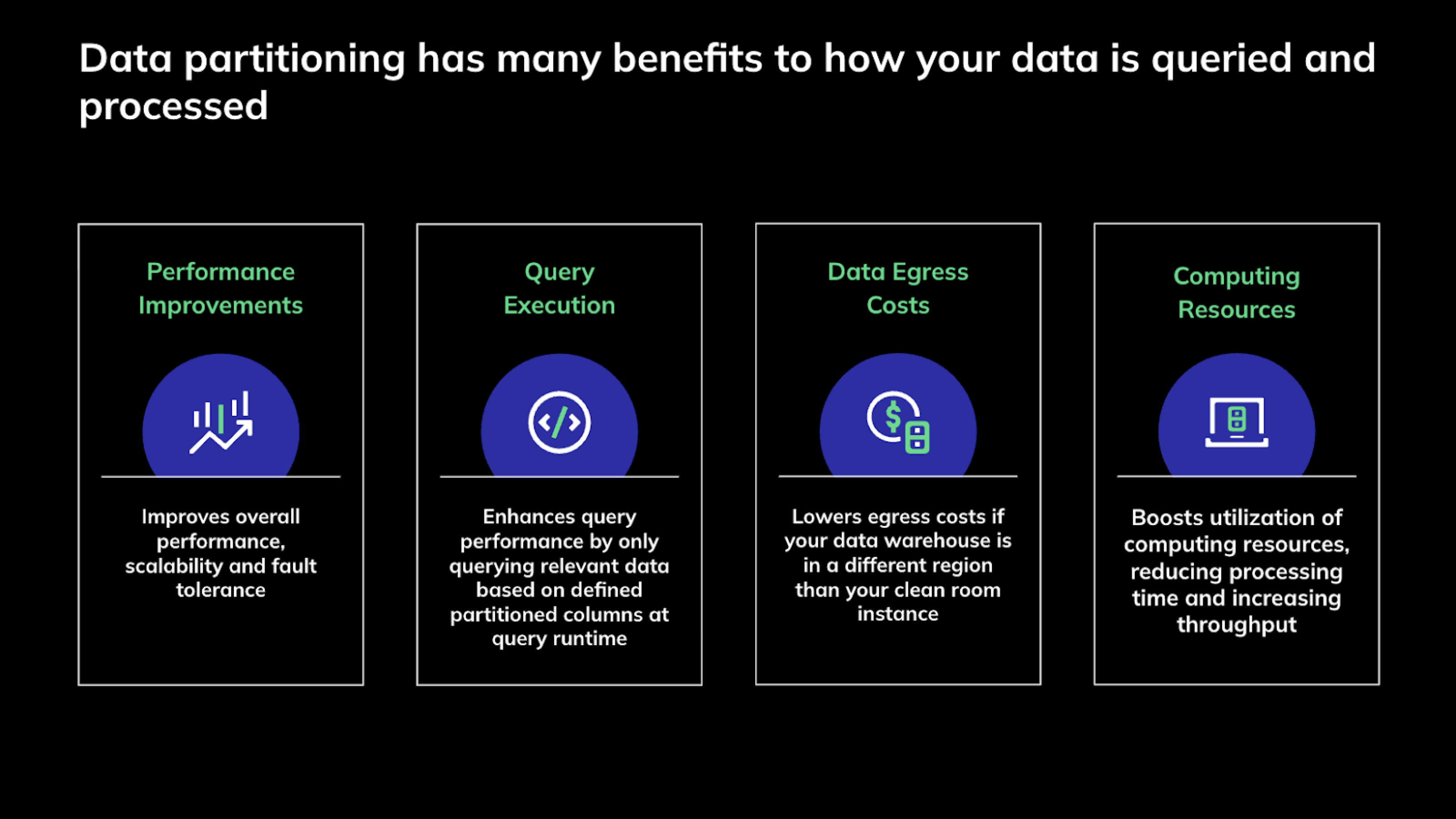
For partitioned data connections, data processing occurs only on relevant data during question runs, rather than processing the entire dataset. This means that instead of accessing the entire dataset, the system only accesses the specific partitions relevant to the query, leading to the following benefits:
Significantly faster processing times
Improved query performance
Enhanced scalability
This approach also results in cost savings by lowering data egress costs (as less data is moved) and boosting the utilization of computing resources, thereby reducing processing time and increasing throughput.
Supported Data Connections and Field Types
LiveRamp Clean Room currently supports the configuration of partition columns for data from the following data connection types:
Cloud storage data connections:
Amazon Web Services S3 (including Iceberg Catalog)
Google Cloud Storage
Databricks
Cloud warehouse data connections:
Google BigQuery
Snowflake (Hybrid clean rooms only)
LiveRamp Clean Room currently supports the configuration of partition columns for the following field types:
Date
String
Integer
Timestamp
Note
For more information on the field types supported by LiveRamp Clean Room, see "Field Types for Data Connections".
Overview of Enabling Dataset Partitioning
In general, enabling partitioning for a dataset in LiveRamp Clean Room involves the following overall steps:
Enable partitioning on the dataset in your cloud warehouse or cloud storage:
For cloud storage data connections (AWS S3, GCS, Azure, Databricks, and Iceberg Catalog). see the "Partition Datasets for Cloud Storage Data Connections" section below
For cloud warehouse data connections (Google BigQuery and Snowflake), see the "Partition Datasets for Cloud Warehouse Data Connections" section below.
During the creation of the data connection, enable the Use Partitioning toggle and enter the additional required information (for more information, see the "Configure Partition Columns in LiveRamp Clean Room" section below).
During field mapping, enable the Allow Partitions toggle for each column you want to partition.
Best Practices and Additional Considerations for Partitioning
Keep the following best practices and considerations in mind when partitioning a dataset:
Granularity of partitions: When choosing partition columns, consider the typical query patterns and data volume. For date-based data, daily partitions (YYYY-MM-DD) are often recommended for high-volume, frequently queried data, as they offer fine-grained control and efficient data scanning. Monthly or yearly partitions might be suitable for less frequently accessed historical data.
Typical partition fields for exposure data: For exposure data, the following fields should typically be partitioned:
Conversion_Date, exposure_date, timestamp
Campaign ID, Campaign Group
Advertiser, Account, or Brand ID
Typical partition fields for conversions data: For conversions data, the following fields should typically be partitioned:
SKU, product category, product type, etc.
conversion_date
Partitioning vs. data access control: It's crucial to understand that partitioning does not inherently filter data such that a partner can only access data relevant to them. For instance, if you partition by brand, a user could still input a brand that is not theirs in the parameter field when running a query and potentially get results. If your goal is to restrict what's accessible to partners in a given clean room, you should perform value filtering on a dataset level when provisioning the dataset for use in the clean room (for more information, see "Provision a Dataset to a Clean Room").
Note
You can use both the partitioning feature and value filtering together to restrict access while also gaining the performance benefits of partitioning.
Consistency is key: Ensure that your data ingestion processes consistently apply the chosen partitioning scheme. Inconsistent partitioning can lead to data being missed by queries or inefficient scans.
Prerequisites for Partitioning
Before partitioning a dataset, first perform the following prerequisites:
Understand your collaboration context: Defining partition columns at a data connection level means you or your partners will always be asked to define the partition value to use to filter the dataset when executing a question run using the associated dataset. Because of this, you should make sure to only enable partitioning for the columns that make logical sense for the questions to which the dataset is likely to be assigned.
Note
Examples:
Publishers defining question logic and operating multiple clean rooms with the same questions are likely to be able to assign partition columns to their data connections without incident.
Advertisers working in multiple clean rooms may wish to assign partition columns only if they know filtering on those columns will always work for the types of questions to which the dataset will likely be assigned.
Ensure proper partitioning before creating the data connection: Make sure your data is partitioned in the cloud storage or cloud warehouse before configuring the connection to LiveRamp Clean Room. For BigQuery and Snowflake, make sure columns are indicated as partition keys. For S3, GCS, and Azure, make sure your buckets/file paths are structured in a partitioning format based on the partition column.
Partitioning best practices differ based on your data source, whether it's cloud storage (such as AWS S3, GCS, or Azure) or a cloud warehouse (such as Snowflake or Google BigQuery). For more information, see the sections below.
Partition Datasets for Cloud Storage Data Connections
For cloud storage data connections (AWS S3, GCS, Azure, Databricks, and Iceberg Catalog), you need to organize your data into folders that reflect the partition columns. LiveRamp encourages users to use Hive-style partitioning, typically by date (such as s3://bucket/path/date=YYYY-MM-DD/). With Hive-style partitioning, partition column values are encoded in the folder path using the format: <partition_column>=<value>.
Note
While Hive-style partitioning is recommended, it's not strictly required. If you're not using Hive-style partitioning, you can still specify a partition column when configuring the data connection in LiveRamp. In this case, LiveRamp will treat the specified column as a partition column even if the data isn’t physically partitioned at the source—though you may see fewer performance benefits.
You can choose to partition on multiple columns. For example: s3://path/to/bucket/advertiser=abc/date=2025-05-01/file.csv.
Note
Partition columns are not required to be part of the dataset's actual fields. For example, if you use Hive-style partitioning by date, but date isn't a field in your dataset, you must add a date field when performing field mapping. This way, questions that use the dataset can use "date" as a runtime parameter.
When setting up the connection in LiveRamp:
Provide the main bucket path.
Note
The data location path should not include trailing partition values (e.g., use
s3://path/to/bucket/ not s3://path/to/bucket/date=2025-05-01/).Provide the full file path for a "data schema reference file", where the headers in the file show LiveRamp how your folders are structured with the partition values. This helps LiveRamp understand your partitioning and infer the correct schema for the data connection.
The header row of the data schema reference file should include the complete partition folder structure so LiveRamp Clean Room can infer the schema and properly recognize partitioning for query filters.
The file should also contain a few rows of sample data so that LiveRamp can understand the field type for each column.
If you're partitioning by date using the file path, only the "YYYY-MM-DD" date format is supported.
Note
Examples:
Partition column is on brand-id:
s3://transactions/brand-id=<id_number>Partition column is on date:
gs://cloudbucket/transaction_date={yyyy-MM-dd}/Example of data location and sample file path with partitioning:
Data Location:
s3://liveramp-dev-us-east-1-dcr/shared/dev/testing/exposure_events/Sample File Path:
s3://liveramp-dev-us-east-1-dcr/shared/dev/testing/exposure_events/day=2025-05-20/part-00
Finally, during field mapping, you enable the Allow Partitions toggles for each field you want to partition on.
Partition Datasets for Cloud Warehouse Data Connections
For cloud warehouse data connections (Google BigQuery and Snowflake), partitioning is handled within the warehouse itself:
For Google BigQuery, you would first typically define partition keys directly on your tables.
For Snowflake, the process within the cloud warehouse would handle partitioning automatically.
Note
For instructions on partitioning tables in BigQuery, see this Google article.
Partitioning should be applied to FACT tables in particular. You must partition on date and can then cluster on any subsequent columns for additional granularity.
Then, when creating the data connection, you enable the Use Partitioning toggle.
Finally, during field mapping, you enable the Allow Partitions toggles for each field you want to partition on.
Configure Partition Columns in LiveRamp Clean Room
When configuring a new data connection, you first indicate that the dataset should use partitioning. During field mapping, you indicate which columns you would like to use for partitioning.
The process is similar to the basic data connection creation and field mapping steps:
Select the appropriate data source from the list of options.
Fill in the configuration fields appropriate to the data connection.
In the Data Location and Schema area, slide the Use Partitioning toggle to the right.
For file-based cloud storage data connections, you must include the full path information for a "data schema reference file" to ensure successful partitioning. This sample file should show the complete partition folder structure and several rows of sample data so LiveRamp can infer the schema and properly recognize partitioning for query filters.
If a data schema reference file is not provided, queries will fail at runtime.
The data location path should not include trailing partition values (e.g., use
s3://path/to/bucket/ not s3://path/to/bucket/date=2025-05-01/).Multiple partitions can be present. Example:
s3://path/to/bucket/advertiser=abc/date=2025-05-01/file.csv.If the data is partitioned by a column (such as "advertiser") but this is not reflected in the data schema reference file, partitioning will not work correctly.
If you're partitioning by date using the file path, only the "YYYY-MM-DD" date format is supported.
For cloud warehouse data connections, you must specify a temporary dataset. This should be an empty dataset in your cloud data warehouse, which is used by LiveRamp as a temporary place to store the partitioned view of the data during query execution.
Once the data connection is saved, verified, and moves to the "Mapping Required" status, configure the schema fields, their data types, and indicate their PII or unique identifier status.
During this step, you will also be prompted to configure which columns should be used as partition columns by sliding the "Allow Partitions" toggle to the right for the relevant field. Any columns you select will be used to filter data for question runs in questions where the associated dataset is assigned.
Be sure to “Add” any fields used for Hive-style partitioning that are not in the actual dataset and “Allow Partitions” on them.
Note
Partition columns are not required to be part of the dataset's actual fields. For example, if you use Hive-style partitioning by date, but date isn't a field in your dataset, you must add a date field when performing field mapping. This way, questions that use the dataset can use "date" as a runtime parameter.
Specify Partition Values During Question Runs
Once you have enabled partitioning for a particular data connection, you and your partners will be prompted to indicate partition filter values when requesting question runs using the associated dataset. This means that any dataset with partitioned columns required for a question to run will have those columns as required fields when triggering a question run in a clean room.
For example:
If partitioning on date, start date and end date parameters must be entered when triggering a run, and only data for the specified dates will be processed.
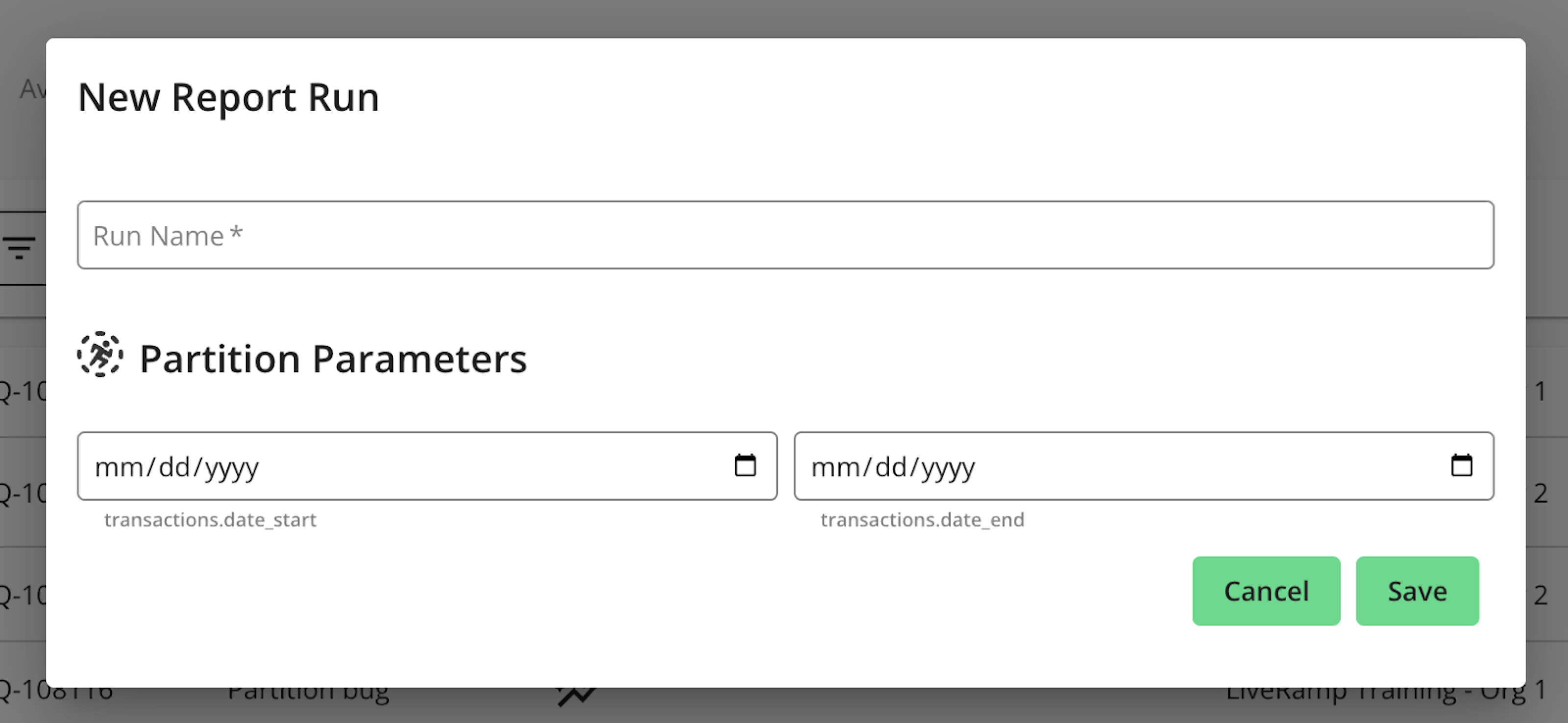
If partitioning on brand, a brand parameter must be entered when triggering a run, and only the relevant brand data will be processed.