Clean Compute on Apache Spark
Clean Compute is the mechanism for executing your custom Python code against your own data and partner data from within a clean room while respecting the architectural integrity of the clean room. Clean Compute enables multi-node processing via customizable Spark jobs when you run a Clean Compute question.
Note
Clean Compute is only available for Hybrid Confidential Compute clean rooms and Hybrid clean rooms.
To request the Clean Compute feature, contact your LiveRamp representative.
To avoid retaining your data and your partners' data, LiveRamp Clean Room processes data in-memory via distributed computing on the Apache Spark query execution engine. If your queries don't consider this approach, it can lead to errors, such as the following:
Memory timeouts can occur due to excessive shuffling in Spark's distributed processing.
Specific SQL constructs, if not carefully managed on large datasets, can cause failures. For example, cross joins on large datasets can be memory-intensive in a distributed environment.
Excessive or inefficient use of common table expressions (CTEs) can also contribute to memory issues and failures.
Overall Steps
Perform the following overall steps to create a Python-based Spark job as a Clean Compute question in a clean room:
For information on performing these steps, see the sections below.
For information on limitations, see the "Limitations" section.
Prepare the WHL Package
To create Python-based Spark jobs as questions in your clean rooms, follow the guidelines listed below when preparing your code:
Wheel package format is required: To maintain the integrity and security of the clean room, the code must be available to the clean room in a Wheel package format.
Template format required: The code must follow the format of the included files in the template.zip package provided by your LiveRamp representative. This includes:
requirements.txt is a requirements file that lists packages required to run your custom code for reference while running the job.
setup.py file
transformation.py: This file is referred to by the setup.py file, so it must use the transformation.py filename.
custom_job directory with an optional custom_code.py file: Either include your business logic in the transformation.py script directly or invoke the custom_code.py file in the transformation.py script.
__init__.py files
data_handler.py: Enables clean rooms to create dataframes from configured datasets.
Follow the template structure: The code must follow the templatized structure we've provided in the
template.zippackage, including:Leave the
data_handler.pyfile as-is.For the
transformation.pyfile:Include the
Transformationclass based on the provided template.def transform ()function to wrap around the core business logic.${dataset}definitions of dataframes to account for datasets. These represent macros in the question definition to provide placeholders for assigned datasets. Define them as you expect the macros to appear during the dataset assignment.In the example package, these are referred to as the
partnerandownervariables.
resultdefines the desired output of the job. This can be done directly or via the custom_code.py script as illustrated in the template.Core business logic should then be included in the
def transform()function acting on the defined dataset dataframes or referenced via thecustom_codeoption.If you would like to include accompanying metrics on model performance as an output file for downstream consumption or consumption from the View Reports screen, refer to the example template’s use of the
has_multiple_outputsBoolean and includeself.data_handler.save_outputin your transformation.py file. You will also need to indicate the code results in an output file when configuring outputs in the Question Builder.Ending in
self.data_handler.write(result)to ensure the output of the job is written to memory in the Spark session.
Write output to storage: If you wish to generate both a results dataframe and additional file-based outputs, such as model metrics in JSON format, you must write the output object to clean room storage using
self.data_handler.save_output(output_file_path). An example of this is outlined in the template's README.Dynamic runtime parameters: To leverage dynamic runtime parameters for clean compute questions, you must leverage the
run_paramsfunction of theDataHandlerclass and then get them at runtime as part of yourTransformationclass. See below for more details on configuring runtime parameters for Clean Compute questions.Dynamic transcoding: To enable transcoding of RampIDs for performing joins on the RampID columns of multiple datasets, use the
BaseTablePyandJoinTablePyclasses in theDataHandlerclass. You can call thetranscode_rampid_joinmethod, which retrieves a resulting dataframe after transcoding the RampID joins.Note
Transcoding can only be applied to a field that was labeled RampID in the data connection mapping.
Transcoding RampIDs requires the latest version of the Clean Compute Spark template package: version 1.2 or later. To upgrade your template package, contact your LiveRamp representative.
Each code artifact must be its own independent package: This means that if you wish to run independent jobs, these should each be included in their own artifact store data connection and should respect the above requirements.
Don't change the filename: Do not update the name of the .whl file after it is generated. If you would like to make changes, do that in the setup.py file and then re-generate the .whl file.
Note
If you must specify the name of the .whl file, you can do that before generating the .whl by specifying that using the setup.py
nameandversionparameters, as shown below: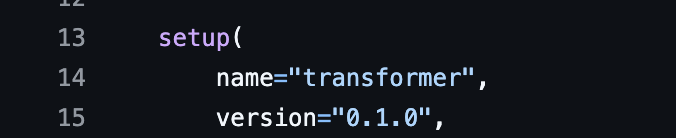
Plan dataset and field macros: Determine how your code will be translated to dataset and field macros within the clean room before configuring the package. For your first version, it may be easier to configure the datasets and fields in Question Builder before authoring the code in order to better understand your expected input and output schema. A good rule of thumb is that the dataframes used will correspond to datasets or dataset macros, and columns will correspond to field macros.
Validate the Code with the Synthetic Validator
One of the challenges you might face when adapting your code to the required WHL package format is ensuring your code will run properly in the clean room. To help you avoid lengthy iteration cycles due to code incompatibility, LiveRamp includes a synthetic validator script in the sample WHL package. This synthetic validator can be executed on your local machine to:
Validate that your use of dataset and field macros matches your expected question configuration for input and output schemas.
Validate that your code is compatible with PySpark.
Check for any typos or misconfigurations that might cause question run failures.
To use the synthetic validator to test your custom code:
Open the tests folder in the clean compute template in your code editor and locate the test_data_config.yaml file.
Navigate to the datasets section.
Define the macro names you will use for your datasets and fields if using field macros. The datasets section is used to define the schemas for known datasets you will invoke in the code. If you are writing a multi-use question and will use dataset and field macros, use the dataset_types section and include the mapping between the columns you use in the custom_code for the stand-in dataset and the macros you will configure for the question.
For example, if you have one dataset you will call
transaction, and your partner is bringing an exposure dataset for which you do not yet know the header names, your configuration may look something like the following:datasets: transaction: schema: ["basket_amt", "txn_date","#lylty_id","RampID"] types: ["LONG","DATE","STRING","STRING"] num_rows: 100 dataset_types: exposures: schema: ["view_date","RampID","creative_id"] types: ["DATE","STRING","STRING"] column_macro_mapping: exposure_date: "view_date" unique_id: "RampID" creative_id: "creative_id" num_rows: 100The
num_rowsfield indicates the number of rows the synthetic validator generates of fake data.If your question produces multiple outputs, define
has_extra_outputsas true. If not, define it as false.Include runtime parameters and values to use for the synthetic validator test. For example, in the above example, one might include an
attribution_windowruntime parameter, which would be configured as:run_parameters: attribution_window: value: "14" type: "INTEGER"Save your updated YAML configuration file.
From the tests folder, execute the script with synthetic_validator.py
The synthetic validator will generate a virtual environment with the default Spark configuration for clean compute, an installation of all of your requirements.txt packages, and synthetic data for validation testing. If there are any compatibility issues or code errors, these will show as exceptions and provide feedback on where in your code the issue may be. If the test passes, you will receive a test passed message. Once your test passes, you can proceed with confidence that your code will run in the clean room.
Add the Credentials
Determine where you want to store the Clean Compute Wheel package and place it in the appropriate bucket. This will be your artifact store for the Clean Compute package:
Amazon Web Services Simple Storage Service (AWS S3)
Azure Data Lake Storage (ADLS)
Google Cloud Storage (GCS)
From the navigation menu, select Clean Room → Credentials to open the Credentials page.
Click .
Enter a descriptive name for the credential.
For the Credentials Type, select either GCS or S3 (depending on what you chose in step 1) for access to the artifact store.
Click .
Create the Data Connection
Note
You will need to create separate data connections for each Clean Compute wheel package that you want to use in questions.
From the navigation menu, select Clean Room → Data Connections to open the Data Connections page.
From the Data Connections page, click .
From the New Data Connection screen, select "Artifact Store".
Select the credentials you created in the "Add the Credentials" section above.
Complete the following fields in the Set up Data Connection section:
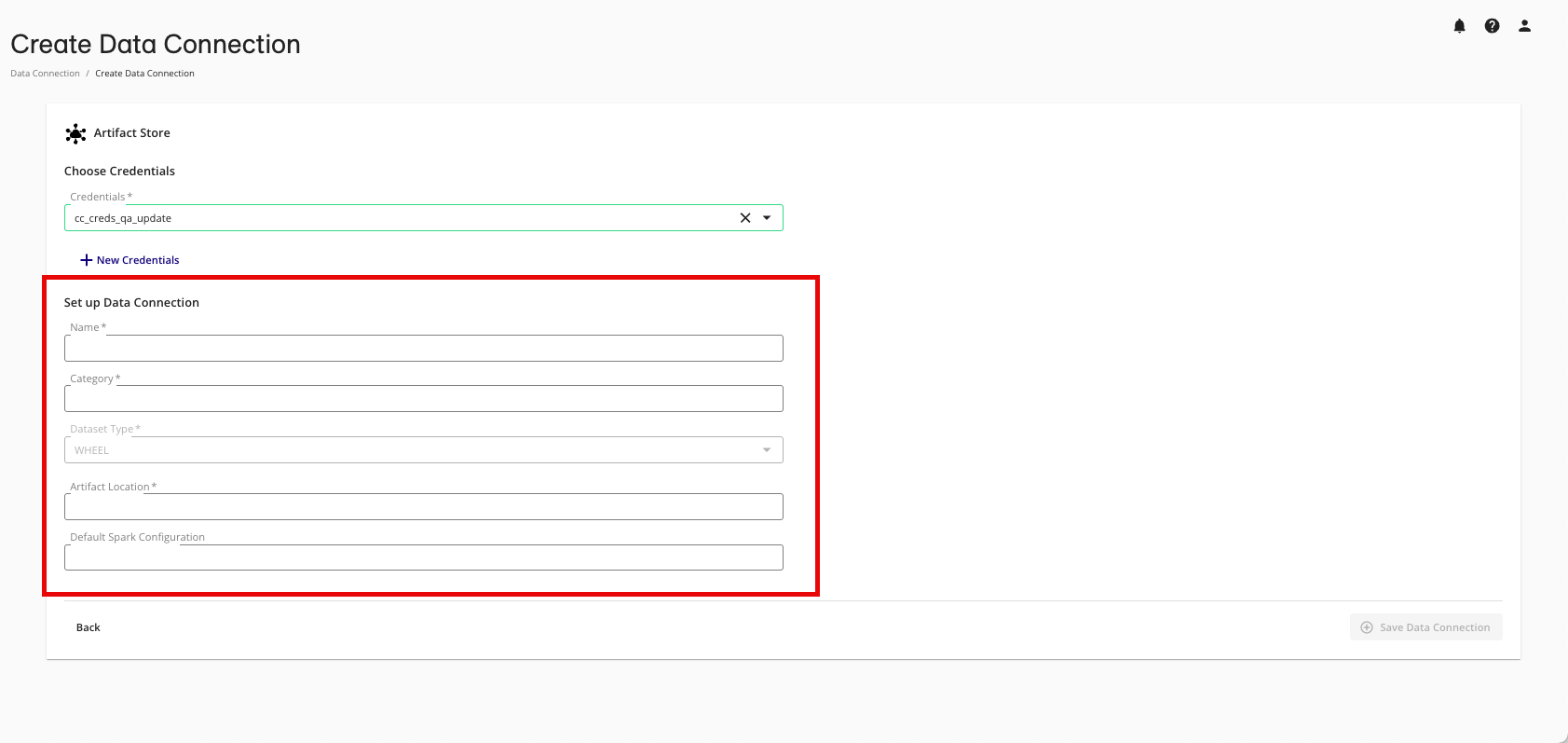
Name: Enter the name for the Clean Compute package when authoring questions.
Note
This name is displayed when assigning the "dataset" to the question.
Category: Enter a category of your choice.
Dataset Type: Select WHEEL.
Note
JAR files are not currently supported.
Artifact Location: Provide the bucket path for where the file will be stored.
Default Spark Configuration: If you would like to specify a default job configuration for questions using this data connection, this can optionally be included with comma-separated specifications. These are based on Spark configuration property documentation and can also be used to define environment variables.
An example format for this configuration is
spark.property_1=value;spark.property_2=value2.Note
The default configuration, if left blank, is a bare-bones configuration LiveRamp uses to execute the job.
Review the data connection details and click .
All configured data connections can be seen on the Data Connections page.
You're now ready to provision the associated dataset to the appropriate clean rooms.
Configure Datasets for Clean Compute Questions
Make sure all parties have configured the datasets required to complete your Spark job in the specified clean room.
Make sure to configure the Artifact Store-based data connection you configured in the step above as a dataset within the clean room.
Create a Clean Compute Spark Question
From your organization or from within the clean room in which you are creating the Clean Compute question, go to Questions.
On the Questions page, click .
Enter values for the following metadata fields:
Question Name: Enter a descriptive name that will make it easy for internal and external users to quickly understand the context of the question.
Category: Consider a naming convention for ease of search.
Description (optional): You can create descriptions for different audiences, including business, data science, and technical users. Descriptions explain how the report should be read, provide insights derived from the report, and can be tailored for different user profiles.
Tags (optional): Add a tag to help with question categorization and filtering of questions. To add a tag, type the desired value and press Enter.
Question Type: Select User List or Analytical Question. Once you save a question, you cannot change its question type.
Select the check box for "Clean Compute on Spark Question".
For Question Type, select Analytical Question.
Click .
Create the appropriate macros:
If the question supports specifying datasets, create macros for the relevant datasets.
If you're using an organization-level templated question, create macros for the WHL file and the expected datasets.
Create dataset-type macros for expected partner dataset inputs.
Note
These macros must match those created in the
def transform()function you specified in the transformation.py file. Include field macros where appropriate.(Optional): Include runtime parameters below the dataset and field macros. Runtime parameters are used to insert values for dynamic variables in your code at runtime. If using runtime parameters, label the parameters in the UI with the same names and data types your code indicates.
For Output Format, select the desired format:
Report: Appears in the UI based on the dimensions and measures you configure (typically related to a dataframe's contents).
Data Location: This writes the output to a location managed by LiveRamp and is typically used for binary outputs. This option operates similarly to list questions in that the output can then be set up for export via an export channel and picked up for use elsewhere in your systems as desired.
Note
If you included extra outputs, such as model metrics, in your code, toggle Enable Multiple Outputs on the right-hand menu. Supported output formats include JSON, PDF, and PNG.
Click .
Once you save the question, be sure to check whether the clean room question permissions meet your requirements by clicking the more options menu (...) next to the question and Permissions Override. You can indicate here whether your partners can perform certain actions. If View Query/Code is selected, your partners will be able to download your WHL package for inspection before opting into your code. If you do not want partners to be able to view your code, do not select this permission.
Assign Datasets to a Clean Compute Spark Question
This follows the same process as required for other question types. Make sure to assign your wheel file data connection as part of the process.
When you assign datasets, you can override the default Spark configuration from the Artifact Store data connection. This is done at the dataset level if you have additional knowledge about the scale of the dataset, which would alter requirements from the default configuration. Once saved, the specified Spark configuration will be used for all runs of the corresponding question.
Go to Manage Datasets for the relevant question.
In the Assign Datasets step, for the Wheel dataset type, click the pencil icon to edit the default Spark configuration.
Edit as necessary and save.
Note
Editing is only required if necessary, and is not typically required.
Run the Clean Compute Spark Question
Request a report as you would for any other question type.
Limitations
LiveRamp must maintain the principles of clean room architecture, regardless of the code run on data. This means we cannot allow the ability to enable all possible Spark job configurations or desired code inputs. We limit the types of configurations that can be run as follows:
To mitigate risks associated with data extraction, logging initiated by the Clean Compute code is not permitted.
The ability to enforce crowd size (k-min) on arbitrary code cannot be enforced or verified. If partners have a crowd-size requirement, the code author must enforce this in their code. However, you can view configured k-min values on the Configuration tab of the Question Details page (see "View Question Details").
Clean Compute does not support the
listTables()function.SHOW_TABLESis supported and is a comparable alternative approach.Clean Compute does not yet support JAR files.
Clean Compute FAQs
Q. Which clean room types support Clean Compute on Spark?
A. Clean Compute on Apache Spark is only available for Hybrid and Hybrid Confidential Computing (HCC) clean rooms. It isn’t supported in other clean room types.
Q. Do multiple outputs for Clean Compute questions allow for more than one output type in a single question?
A. Yes, Clean Compute on Spark supports multiple outputs per single CRQ run if your WHL package is configured to generate them. You then download each named file individually via the run's download endpoint. This means one run can provide both a PDF and a JSON output, provided your WHL writes both artifacts and exposes them as outputs. The same pattern applies to flow nodes as well.
Q. How do I package my code for a Clean Compute question?
A. Your code must be packaged as a Python wheel (.whl) file that follows the LiveRamp template structure (including setup.py, transformation.py, data_handler.py, and related files) to run as a Clean Compute job.
Q. Can I use the same WHL package for multiple questions or flows?
A. Yes, you typically create one artifact-store data connection per WHL package, then reuse that connection across multiple Clean Compute questions and flows, as long as the code and macros are compatible.
Q. How do I validate my Clean Compute code before running it in a clean room?
A. Use the synthetic validator that ships with the Clean Compute template to generate synthetic data, confirm macro usage, and check PySpark compatibility locally before uploading the WHL.
Q. What storage locations can I use for my Clean Compute WHL package?
A. Clean Compute artifact stores can live in AWS S3, Azure Data Lake Storage, or Google Cloud Storage, configured via a credential and artifact-store data connection in LiveRamp Clean Room.
Q. How do runtime parameters work for Clean Compute questions?
A. You define runtime parameters in Question Builder, and your code reads them via the run_params support in the DataHandler/Transformation classes, so the same WHL can run with different parameter values (like attribution windows) per run.
Q. How is Spark configured for Clean Compute, and can I override defaults?
A. You can set a default Spark configuration on the artifact-store data connection, and optionally override it per dataset when assigning datasets to a Clean Compute question, which then applies to all runs of that question.