Running LiveRamp's Local Encoder In a Docker-Run Environment
Local Encoder enables you to generate securely encoded RampIDs for your consumer data files within your own cloud environment and then use that data for activation or addressability use cases, depending on your needs. In this way, your consumer data is never exposed to an external network, while still enabling full use of the LiveRamp solutions. The encoded RampIDs produced by the application cannot be decoded back to the original consumer identifiers.
Local Encoder can be run on any infrastructure that supports running Docker images. The Local Encoder Docker image is currently distributed via the Amazon Elastic Container Registry (ECR).
For more information on Local Encoder, including information on security, use cases, data you can send, and output options, see "LiveRamp Local Encoder".
See the optional parameters below.
For information on running Local Encoder using Docker run, see the sections below.
Overall Steps
Running the Local Encoder in a Docker-run environment involves the following overall steps:
You provide LiveRamp with your PGP public key or Keybase username.
LiveRamp provides you with credentials.
You decrypt the AWS IAM Secret Access Key.
You use the credentials to configure AWS to access LiveRamp's Docker image in ECR.
You use Docker to access ECR and pull the Docker image for Local Encoder.
You test the installation.
You complete other configuration activities, as necessary:
If you want to save processed file names permanently, you configure how file names are stored.
If you want to use a different input or output location than the defaults, you mount folders.
You create and mount a configuration file that contains information used by the run command.
You run the Local Encoder.
You format your data files and then upload them to the appropriate input location.
You run the encoding operation within your VPC:
The data is normalized, and hygiene is performed.
The identifiers in the data are converted into derived RampIDs.
If appropriate, the derived RampIDs for each record are encoded into secure RampID packets or identity envelopes.
The input identifiers are removed and replaced with the appropriate RampID output type (RampIDs, RampID packets, or identity envelopes).
For activation use cases, the following steps are performed:
The output containing RampID packets is delivered to LiveRamp.
LiveRamp decodes the RampID packets into their individual derived RampIDs.
LiveRamp matches those derived RampIDs to their associated maintained RampIDs.
LiveRamp creates the appropriate fields and segments from the segment data in your LiveRamp platform (such as Connect or Safe Haven).
For addressability use cases, the following steps are performed:
The output containing RampIDs or identity envelopes is output to the destination of your choice.
You leverage the output to build a mapping table of your customer IDs to RampIDs or identity envelopes.
Prerequisites
Running the Local Encoder in a Docker-run environment requires that you have the following prerequisites:
A Docker installation
AWS Command Line Interface (CLI)
A PGP public key or Keybase username
Note
You will use the AWS command line tool to issue commands at your system's command line to perform Amazon ECR and other AWS tasks. We recommend that you have the latest version of the AWS CLI installed. For information about installing the AWS CLI or upgrading it to the latest version, see Installing the AWS Command Line Interface.
We need to maintain the same architecture, i.e., build the image to match the architecture used by the Runner.
Decrypt the AWS IAM Secret Access Key
In addition to providing the Local Encoder account ID and the AWS IAM Access Key ID, LiveRamp will provide the AWS IAM Secret Access Key in an encrypted format. The AWS IAM Secret Access Key must be decrypted for use in subsequent steps.
To decrypt the AWS IAM Secret Access Key:
Export your public and private key to files, name them "public.key" and "private.key", and save them in the "/tmp" directory.
Save the encrypted AWS IAM Secret Access Key to a file named "secret.txt" and save it in the "/tmp" directory.
Note
If the "/tmp" directory has not already been created, you will need to create it.
From Docker, run the following command:
docker run -it --rm alpine apk add --no-cache wget gnupg && export GPG_TTY=$(tty) && gpg --import /tmp/public.key && gpg --import /tmp/private.key && base64 -d -i /tmp/secret.txt | gpg --decrypt > /tmp/output.txt
Open the "output.txt" file to access the decrypted AWS IAM Secret Access Key.
Configure AWS to Access LiveRamp's Docker Image
To configure AWS to be able to access LiveRamp's Local Encoder Docker image in ECR, set your AWS IAM access key and secret access key in one of the following methods.
Run AWS Configure
From the command line, run the command "aws configure" with the following values:
AWS Access Key Id: [LR_VAULT_LR_AWS_ACCESS_KEY_ID] AWS Secret Access Key: [LR_VAULT_LR_AWS_SECRET_ACCESS_KEY] Default region name: eu-central-1 Default output format: json
Edit Files Manually
To set your keys by editing the files manually (MAC OS example):
From Finder, navigate to the Home directory.
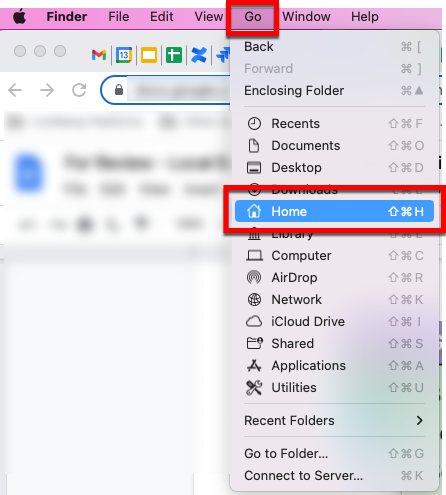
Press (command + shift + .) to reveal the hidden folders within the Home directory Note: If you don't see these files, you might not have the latest version of AWS CLI installed. Follow the instructions in this Amazon article to install the latest version.
From the .aws folder, open the "config" and "credentials" files and then enter your aws_access_key_id and aws_secret_access_key (2.2) values as shown below:

Pull the Docker Image
The Docker image you need to pull from ECR is "461694764112.dkr.ecr.eu-central-1.amazonaws.com/vault-app:latest".
Once you've configured AWS to access LiveRamp's Local Encoder Docker image in ECR, perform the following steps to pull the Docker image:
Make sure the Docker Engine is running
Execute the following commands in the CLI:
aws ecr get-login-password --region eu-central-1 | docker login --username AWS --password-stdin 461694764112.dkr.ecr.eu-central-1.amazonaws.com
Note
Make sure to run the command exactly as shown.
The command output should declare "Login Succeeded".
Note
If you get an error code, check that you have configured AWS correctly.
Run the following command to retrieve the image:
docker pull 461694764112.dkr.ecr.eu-central-1.amazonaws.com/vault-app:latest
The Docker image should be available on your local machine or VM to use.
To confirm access to the image, run the following command and make sure that the image shows up in the list of images:
docker images
Test the Installation
To confirm that the installation has been done properly, we recommend that you test the installation. The Local Encoder offers a test mode, which can let you run the app without the data being sent to LiveRamp. To run the app in test mode, run the following command in Docker:
docker run --cap-add IPC_LOCK \ --env LR_VAULT_ACCOUNT_ID=test \ --env LR_VAULT_ACCOUNT_TYPE=awsiam \ --env LR_VAULT_DRY_RUN=true \ --env LR_VAULT_INPUT=/tmp/input \ --env LR_VAULT_OUTPUT=/tmp/output \ --env LR_VAULT_LOCALE=au \ --name vault-app image-name
or
docker run --cap-add IPC_LOCK \ --env LR_VAULT_ACCOUNT_ID=test \ --env LR_VAULT_ACCOUNT_TYPE=awsiam \ --env LR_VAULT_DRY_RUN=true \ --env LR_VAULT_INPUT=/tmp/input \ --env LR_VAULT_OUTPUT=/tmp/output \ --env LR_VAULT_LOCALE=au \ image-name
LR_VAULT_ACCOUNT_ID: You can use any value for dry run mode
LR_VAULT_ACCOUNT_TYPE: You can use either "awsiam" or "aws"
LR_VAULT_DRY_RUN: Use "true" to enable test mode
LR_VAULT_INPUT: The location of the local folder containing input files to process
LR_VAULT_OUTPUT: The location of the local folder for output files
LR_VAULT_LOCALE: The two-digit country code
If you would like a file with test data, contact your LiveRamp representative. The output of that test file can be run against a truth set to ensure that the application has run as expected.
Complete Configuration Activities
See the sections below for information on completing any desired additional configuration activities. For more information on configuration parameters, see the "Configuration Parameters" section below.
Configure the Output Type
The Local Encoder application offers multiple output formats:
RampID packets: Used for Activation by brands and marketers, these RampID packets can be delivered to LiveRamp, where they can be transformed into RampIDs and used to generate fields and segments in your LiveRamp application. This is the default output type.
RampIDs: Used for addressability by publishers and platforms that want to create a RampID mapping.
Identity envelopes: Used for addressability by publishers and platforms that want to get RampIDs into the bidstream to safely engage with the programmatic advertising ecosystem.
Note
If you plan to receive RampIDs or identity envelopes, contact your LiveRamp representative for approval and account configuration changes.
Identity envelope output is only available with Local Encoder Version 1.6 or later.
After you are approved for RampID or identity envelope output, update your configuration to add an additional variable using one of the methods listed below:
Note
To receive RampID packets, you do not need to make any changes to the configuration.
Environmental Variable (when running the Local Encoder):
For RampID output, add the following line to the Environmental Variable:
--env LR_VAULT_PACKET_TYPE: unencoded
For identity envelope output, add the following line to the Environmental Variable:
--env LR_VAULT_ENVELOPES_FLOW=true
Config File (when implementing a configuration file):
For RampID output, add the following line to the Config File:
packet_type: unencoded
For identity envelope output, add the following line to the Config File:
envelopes_flow: true
Note
When editing the yml file, any formatting issues will prevent the configuration file from working properly. We recommend that you run the file through a YAML validator.
Utilize Encryption
Optional encryption is available with Local Encoder (version 1.5 and greater). This functionality encrypts each row of data before it is sent to LiveRamp for processing.
Note
Adding encryption increases the processing time by approximately 20%, depending on the size of the file and the number of records. LiveRamp recommends limiting file size to 15GB.
To utilize encryption, use one of the following methods, depending on your implementation:
Add the following variable to the code sample, just before the
namevariable:--env LR_VAULT_PUBLIC_KEY_ENCRYPTION=true(for more information, see the "Run the Local Encoder" section)Add the following line to the configuration file, just before the
country_code_columnparameter:public_key_encryption: true(for more information, see the "Implement a Configuration File" section)
Enable the Error Log File
You can configure Local Encoder to return an error log to your desired location that provides details on any errors that were encountered during processing, including the row number for the row where the error occurred. You can then correct the errors and re-process the corrected data.
The error log includes the following information (see the example below):

The date and time of the error
The type of error
The row number where the error occurred
The name of the file
To enable the error log file and set the file delivery location, see the sections below, depending on the method used.
The Local Configuration Method
When using the local configuration method, include the following parameters to enable the error log file and set the delivery location for the file:
“-v <localFolder>:/var/logs/vault-app”
“customer_logging_enabled=true”
See below for an example:
docker run --rm --cap-add IPC_LOCK \ -v ~/configurationFileFolder:/config \ -v <localFolder>:/var/logs/vault-app \ vault-app \ -config-file test-configuration.yml
The Command Line or configmaps.yaml Method
When using the command line or configmaps.yaml method, include the following lines to enable the error log file and set the delivery location for the file: :
“-v <localFolder>:/var/logs/vault-app”
“--env LR_VAULT_CUSTOMER_LOGGING_ENABLED=true”
See below for an example that sets the delivery location to “:/Documents/localencoder/log”:
docker run --rm --cap-add IPC_LOCK \ -v ~/Documents/localencoder/input:/tmp/input \ -v ~/Documents/localencoder/output:/tmp/output \ -v ~/Documents/localencoder/log:/var/logs/vault-app \ --env LR_VAULT_ACCOUNT_ID=[LR_VAULT_ACCOUNT_ID] \ --env LR_VAULT_ACCOUNT_TYPE=[LR_VAULT_ACCOUNT_TYPE] \ --env LR_VAULT_LR_AWS_ACCESS_KEY_ID=[AWS_ACCESS_KEY_ID] \ --env LR_VAULT_LR_AWS_SECRET_ACCESS_KEY=[AWS_SECRET_ACCESS_KEY] \ --env LR_VAULT_INPUT=/tmp/input \ --env LR_VAULT_OUTPUT=/tmp/output \ --env LR_VAULT_LOCALE=eu-central-1 \ --env LR_VAULT_CUSTOMER_LOGGING_ENABLED=true --name vault-app [Image Name]
Use Local Input and Output Sources
When using local folders for input and output sources, you have to mount the folder from our host machine:
docker run --rm --cap-add IPC_LOCK \ -v ~/configurationFileFolder:/config \ -v ~/inputFolderOnHostMachine:/LR_VAULT_INPUT \ -v ~/outputFolderOnHostMachine:/LR_VAULT_OUTPUT vault-app \ -config-file test-configuration.yml
In this example, we are mounting input and output folders from the host machine root directory to LR_VAULT_INPUT and LR_VAULT_OUTPUT directories inside LocalEncoder docker containers. LR_VAULT_INPUT and LR_VAULT_OUTPUT are local input and output values that we provided either in a configuration file or by passing env var LR_VAULT_INPUT and LR_VAULT_OUTPUT. Folder names on the host machine are optional. They always have to be mounted to LR_VAULT_INPUT and LR_VAULT_OUTPUT.
By default, the application will output to the LiveRamp S3. If you would like to point output to a different location, set the LR_Local Encoder_OUTPUT variable:
The application outputs the data to a destination of your choice. Use the LR_VAULT_OUTPUT variable to set your destination, as shown below. To onboard data to LiveRamp, set the output to the LiveRamp S3 bucket.
--env LR_VAULT_OUTPUT=[Your local directory, or S3 bucket]
Implement a Configuration File
A configuration file contains information that is used by the run command and allows for the use of run commands that are more streamlined.
When using a configuration file, you need to mount the folder of the configuration file on the host machine to the "/config" folder inside the Docker container.
docker run --rm --cap-add IPC_LOCK \ -v ~/configurationFileFolder:/config \ vault-app \ -config-file test-configuration.yml
In this example, the "test-configuration.yml" file is located in "~/configurationFileFolder" on the host machine, and we are mounting it to the "/config" folder inside the Docker container. Then passing "-config-file test-configuration.yml" as a command line argument to the Local Encoder app. Folder name on the host machine is optional, it always has to be mounted to "/config".
In order to use the configuration file, you need to mount a directory where the file is located to /config directory. Example: -v ~/Documents/localencoder:/config - the YAML config file should be located in the Local encoder folder. Then pass the file name as a command-line argument.
Docker Run example:
docker run --rm --cap-add IPC_LOCK \ -v ~/configurationFileFolder:/config \ [docker_image] \ -config-file [your_filename].yml
Create a YAML configuration file that follows this example:
Note
Any formatting issues will prevent the configuration file from working properly. We recommend that you run the file through a YAML validator.
liveramp:
local_encoder:
account_type: awsiam
account_id: [LR_VAULT_ACCOUNT_ID]
profile: PROD
locale: [COUNTRY_CODE]
output: [your_directory]
input: [your_directory]
filename_pattern: pattern
header_mapping: custom_header=email1,custom_header2=email2
country_code_column: [COUNTRY_CODE]
public_key_encryption: true
mode: default
dry_run: false
lr_aws:
lr_id: 461694764112
lr_access_key_id: [AWS_ACCESS_KEY_ID]
lr_secret_access_key: [AWS_SECRET_ACCESS_KEY]
lr_region: eu-central-1
metastore:
db:
url:
driver:
username:
password:
platform: Include the following information in the file parameters:
account_id: Use the Local Encoder account ID you received from LiveRamp in place of the "[LR_VAULT_ACCOUNT_ID]" variable.
locale: Use the two-digit country code for the country the data originated in.
lr_access_key_id: Use the AWS Access Key ID you received from LiveRamp in place of the "[AWS_ACCESS_KEY_ID]" variable.
lr_secret_access_key: Use the AWS Secret Access Key you received from LiveRamp and decrypted in place of the "[AWS_SECRET_ACCESS_KEY]" variable.
Header_mapping: Include this line if you are using headers for the identifier columns that are different from the standard headers. Map each custom header name to the corresponding standard header name in the format shown, separating each mapping with a comma. If you're using the standard headers, you can leave this line out.
country_code_column: Include this line if you'll be providing data from multiple countries. If you're not going to be providing data from multiple countries, you can leave this line out.
public_key_encryption: Include this line and set it to "true" if you want to have each row encrypted before being sent to LiveRamp for processing. For more information, see the "Utilize Encryption" section below.
Configure Parallel Processing
To improve the processing of large datasets, you can enable horizontal scaling, which processes files in parallel across multiple Local Encoder containers. For information, see "Enable Horizontal Scaling to Process Files in Parallel".
Adjust the Input Bucket Polling Interval
You can increase the polling interval for the input bucket to reduce AWS S3 or GCS Adjust the Input Bucket Polling IntervalListBucket API calls and their associated costs. For information, see "Managing Input Bucket File Discovery (Polling)".
Skip Previously-Processed Input Files
You can configure Local Encoder to automatically skip input files that have already been processed. When this feature is enabled and Local Encoder is started, Local Encoder automatically detects files that have already been processed by checking if corresponding output files exist. If the output for an input file already exists, the input file is skipped to avoid duplicate processing. Only files that have not been previously processed will be processed.
To enable the skip previously-processed files feature, use the appropriate method listed below (depending on your implementation type):
Enable via config (YAML):
skip_processed_files: trueEnable via environment variable:
LR_VAULT_SKIP_PROCESSED_FILES=true
For more information, see "Skip Previously-Processed Input Files".
Run the Local Encoder
To run the Local Encoder as a Docker image --cap-add IPC_LOCK flag needs to be passed. To start a Docker container, run the following command.
docker run --rm --cap-add IPC_LOCK \ --env LR_VAULT_ACCOUNT_ID=[LR_VAULT_ACCOUNT_ID] \ --env LR_VAULT_ACCOUNT_TYPE=[LR_VAULT_ACCOUNT_TYPE] \ --env LR_VAULT_LR_AWS_ACCESS_KEY_ID=[AWS_ACCESS_KEY_ID] \ --env LR_VAULT_LR_AWS_SECRET_ACCESS_KEY=[AWS_SECRET_ACCESS_KEY] \ --env LR_VAULT_INPUT=/tmp/input \ --env LR_VAULT_OUTPUT=/tmp/output \ --env LR_VAULT_LOCALE=eu-central-1 \ --env LR_VAULT_PUBLIC_KEY_ENCRYPTION=true --name vault-app [Image Name]
Note
Only include the row --env LR_VAULT_PUBLIC_KEY_ENCRYPTION=true if you want to have each row encrypted before being sent to LiveRamp for processing. For more information, see the "Utilize Encryption" section above.
Format the File
Input files must include identifier fields and (for activation use cases, where you're receiving RampID packets) can also include segment data fields if desired.
Before uploading a file to the input location, make sure to format the data according to these guidelines:
Include a header row in the first line of every file consistent with the contents of the file. Files cannot be processed without headers.
If you want to maintain the ability to sort the output file, or if you're utilizing one of the deconfliction options, you must include a column containing row IDs ("RID") as the first column of the file.
Note
The row identifier column is only required to maintain sort order and should not contain any customer personally-identifiable data.
Make sure that the only identifiers included are the allowed identifier touchpoints listed below.
If you're sending data for consumers in multiple countries or if you're including phone numbers, you must include the appropriate country code column (depending on the method used) to identify the country of each record. For more information, see the "Optional Configuration Parameters" section below.
Include a maximum of 500 segment data fields in a single file (for activation use cases where you're receiving RampID packets).
Segment data field types can be in the form of a string, a number, an enum, etc.
The application supports three file formats: CSV, PSV, and TSV.
Make sure to name your files in a format that includes info on the file part, such as "filename-part-0001-of-0200".
Note
You must make file names unique, as the application will not process a file that has the same name as a previous file (unless you restart the application to clear the memory).
Files must be rectangular (have the same number of columns for every row).
If any values contain the file's delimiter character (for example, a comma in a CSV file), make sure that your values are contained within quotes.
The recommended maximum file size is 20 GB.
Allowed Identifier Touchpoints
You can include any of the following allowed identifier touchpoints for translation to RampIDs in both Activation and Addressability use cases:
Plaintext email address (maximum of three per record)
SHA-256 hashed email address (maximum of three per record)
Plaintext mobile phone number (maximum of two per record)
Plaintext landline phone number (maximum of one per record)
Additional Allowed Touchpoints for Activation Use Cases
For Activation use cases (where you're receiving RampID packets, the following additional identifier touchpoints are also allowed for translation to RampIDs:
Name and postcode, which consists of first name, last name, and postcode (maximum of one per record) (European countries only)
AAID (maximum of one per record)
IDFA (maximum of one per record)
IMEI (maximum of one per record)
Example Header
See the header shown below for an example of what the header might look like when sending data in a pipe-separated value (PSV) file for an activation use case, where segment data fields are included:
RID|EMAIL1|EMAIL2|EMAIL3|SHA256EMAIL1|SHA256EMAIL2|SHA256EMAIL3|MOBILE1|MOBILE2|LANDLINE1|FIRSTNAME|LASTNAME|POSTCODE|AAID|IDFA|IMEI|ATTRIBUTE_1|...|ATTRIBUTE_N
Replace ATTRIBUTE_1 … N in the example header with the name of your CRM attributes.
Example Output Files
For more information on the output options and the format of the output files, see "Output Options and Examples".
Upload the File to the Input Bucket
Uploading a file to your Local Encoder services input bucket kicks off the encoding operation. To upload your file, run a command similar to the example below (this example shows using an AWS S3, but this could be any local directory):
aws s3 cp [your_file].csv s3://com-liveramp-vault-[your-vpc-id]-input
Once the file has been processed, you'll get a confirmation message that includes the number of records processed.
For RampID packet output, all consumer identifier data in a row is transformed into derived RampIDs, packaged into one data structure, and encrypted again, yielding a RampID packet.
For RampID output, all consumer identifier data in a row is transformed into derived RampIDs in the form of a JSON string in a RampID column.
For identity envelope output, all consumer identifier data is transformed into derived RampIDs. A selection logic is applied, then the RampID is additionally obfuscated and encrypted into an identity envelope. Only one identity envelope is returned per row of data. A timestamp column is appended to the end of each row. This column gives the expiration date and time for the identity envelope in Unix format (time zone UTC).
For more information on output options and the format of the output files, see "Output Options and Examples".
Configuration Parameters
See the sections below for information on the required and optional parameters to use, depending on the deployment method being used.
Required Configuration Parameters
Parameter Name | Parameter for Local Configuration | Parameter for Command Line or Configmaps.yaml | Example Value(s) | Notes |
|---|---|---|---|---|
AWS user ID | account_id | LR_VAULT_ACCOUNT_ID | AID.…. | Provided by LiveRamp |
Account type | account_type | LR_VAULT_ACCOUNT_TYPE | awsiam | |
LiveRamp AWS account ID | AWS_LR_ACCOUNT_ID | 461694764112 | Provided by LiveRamp | |
AWS IAM access key ID | lr_access_key_id | LR_VAULT_LR_AWS_ACCESS_KEY_ID | AKI...... | Provided by LiveRamp |
AWS IAM secret access key | lr_secret_access_key | LR_VAULT_LR_AWS_SECRET_ACCESS_KEY | LiveRamp provides the secret encrypted with the customer key | |
Input File Location | input | LR_VAULT_INPUT |
|
|
Output file Location | output | LR_VAULT_OUTPUT |
|
|
AWS region for LR resources | lr_region | LR_VAULT_LR_AWS_REGION | eu-central-1 | LiveRamp's AWS Region |
Origin of the data being processed | locale | LR_VAULT_LOCALE | us | Two-letter country code representing the origin of the data being processed (for example, Australia = au, Great Britain = GB). Not case sensitive. |
Optional Configuration Parameters
Parameter Name | Parameter for Local Configuration | Parameter for Command Line or Configmaps.yaml | Example Values | Notes |
|---|---|---|---|---|
Customer Profile | profile | LR_VAULT_PROFILE |
| Default is "prod" |
Filename | filename_pattern | LR_VAULT_FILENAME_PATTERN |
| The regex to use to determine which files in the input folder or bucket should be processed (for example, entering |
Country Header | country_code_column | LR_VAULT_COUNTRY_CODE_COLUMN |
|
|
Public Key Encryption | public_key_encryption | LR_VAULT_PUBLIC_KEY_ENCRYPTION | true | Include this parameter and set to |
Header Mapping | header_mapping | LR_VAULT_HEADER_MAPPING | {{customer determined}} newvalue=defaultvalue, | A list of key=value pairs which can be used to replace the default headers for the identifier columns in the file. For example, if the email columns have the headers |
Error Log | customer_logging_enabled | LR_VAULT_CUSTOMER_LOGGING_ENABLED | Include this parameter and set it to | |
Error Log Location | -v <localFolder>:/var/logs/vault-app | -v <localFolder>:/var/logs/vault-app | Include this parameter to set the delivery location for the error log file. | |
Mode | mode | LR_VAULT_MODE |
| The default value is Set to |
Multi-Instance | N/A | LR_VAULT_MULTI_INSTANCE |
| Enables horizontal scaling via multiple pods when set to When set to For more information, see "Enable Horizontal Scaling to Process Files in Parallel". |
Initialize Vault App | N/A | INITIALIZE_VAULT_APP |
| When set to For more information, see "Enable Horizontal Scaling to Process Files in Parallel". |
Instance Replicas | N/A | INSTANCE_REPLICAS |
| The number of Local Encoder pods (AKA "replicas"), which must match the StatefulSet's When Each pod uses multi-threading internally (threads = CPU cores), so one pod can already process multiple files in parallel. Add more replicas when you need to distribute I/O load or process very large datasets faster. For more information, see "Enable Horizontal Scaling to Process Files in Parallel". |
Pod Name | N/A | POD_NAME |
| An environment variable that Kubernetes sets to the name of the running pod via its For Local Encoder horizontal-scaling mode, this pod name (e.g., For more information, see "Enable Horizontal Scaling to Process Files in Parallel". |
Polling Period | N/A | LR_DEFAULT_POLLER_PERIOD | LR_DEFAULT_POLLER_PERIOD: "3600000" | The interval in milliseconds between polling to check for new files in the input bucket. The default value varies depending on whether your LR_VAULT_MODE parameter is configured for default mode (for long-running file processing) or task mode (used to enable single file processing). For more information, see "Adjust the Input Bucket Polling Interval". |
Polling Delay | N/A | LR_DEFAULT_POLLER_INITIAL_DELAY | LR_DEFAULT_POLLER_INITIAL_DELAY: "30000" | The initial delay in milliseconds before the first poll starts. For example, you could specify 30000 to delay the first poll by 30 seconds to ensure the application is fully initialized before file discovery begins. For more information, see "Adjust the Input Bucket Polling Interval". |
Skip Previously-Processed Input Files | skip_processed_files | LR_VAULT_SKIP_PROCESSED_FILES | true | Include this parameter and set to For more information, see “Skip Previously-Processed Input Files”. |
Packet Type | packet_type | LR_VAULT_PACKET_TYPE | unencoded | Include this parameter and set to |
Envelope Output | envelopes_flow | LR_VAULT_ENVELOPES_FLOW | true | Include this parameter and set to |
Test Mode | dry_run | LR_VAULT_DRY_RUN |
| The default value is |
Customer AWS Access Key ID | N/A | AWS_ACCESS_KEY_ID | The access key ID for your AWS S3 bucket. Only used if you are using an S3 bucket as the input source. | |
Customer AWS Secret Access Key | N/A | AWS_SECRET_ACCESS_KEY | Only for customers using S3 bucket as input source. Secret access key for client's AWS. | |
Customer AWS Region | N/A | AWS_REGION | Only for customers using S3 bucket as input source. AWS region in which the bucket is residing. | |
Customer AWS Region | N/A | AWS_DEFAULT_REGION | Only for customers using S3 bucket as input source. AWS region in which the bucket is residing. | |
Customer GCS Bucket Credentials | N/A | GOOGLE_APPLICATION_CREDENTIALS | Only for customers using GCS bucket as input/output source. Path to your Google Credentials JSON file. | |
Customer GCS Project | gcp_project_name | LR_VAULT_GCP_PROJECT_NAME | Only for customers using GCS bucket as input/output source. The name of your GCP project. Added if the default profile name can't be found. | |
Java Tool Options | N/A | JAVA_TOOL_OPTIONS | --env JAVA_TOOL_OPTIONS="-XX:+DisableAttachMechanism -Dcom.sun.management.jmxremote -XX:ActiveProcessorCount=3" |
|