Configure a Resolution Process
Each time a resolution process runs, Identity Engine generates pairs of records and compares them using the rules you configure. It also evaluates whether existing pairs should remain tied to a persistent Enterprise ID, split, or merged into a new ID cluster. The outcome is your first-party graph.
Once you configure one or more data preparation processes, you can start configuring a resolution process for the workflow.
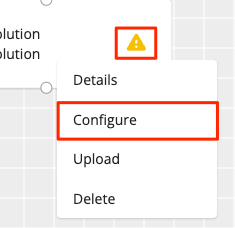
Once you drag and drop a resolution process onto your workflow canvas, a yellow warning icon
 indicates that it is not yet configured.
indicates that it is not yet configured.Click the icon and select . If this option is grayed out, it indicates that your data preparation process has not yet been configured. For information, see "Configure a Data Preparation Process".
Tip
You can reuse the saved configuration for other processes by downloading it as a JSON file. From the Workflow Editor, select from the process' More Options menu.
On your new process, select from the More Options menu, browse for the JSON file with the desired configuration you just downloaded, select it, and click Open to upload it to the new process.
The Configure Resolution Process wizard displays the Process Details step. If you've uploaded a JSON file, all the fields and options will be predefined, which you can modify or leave as is.
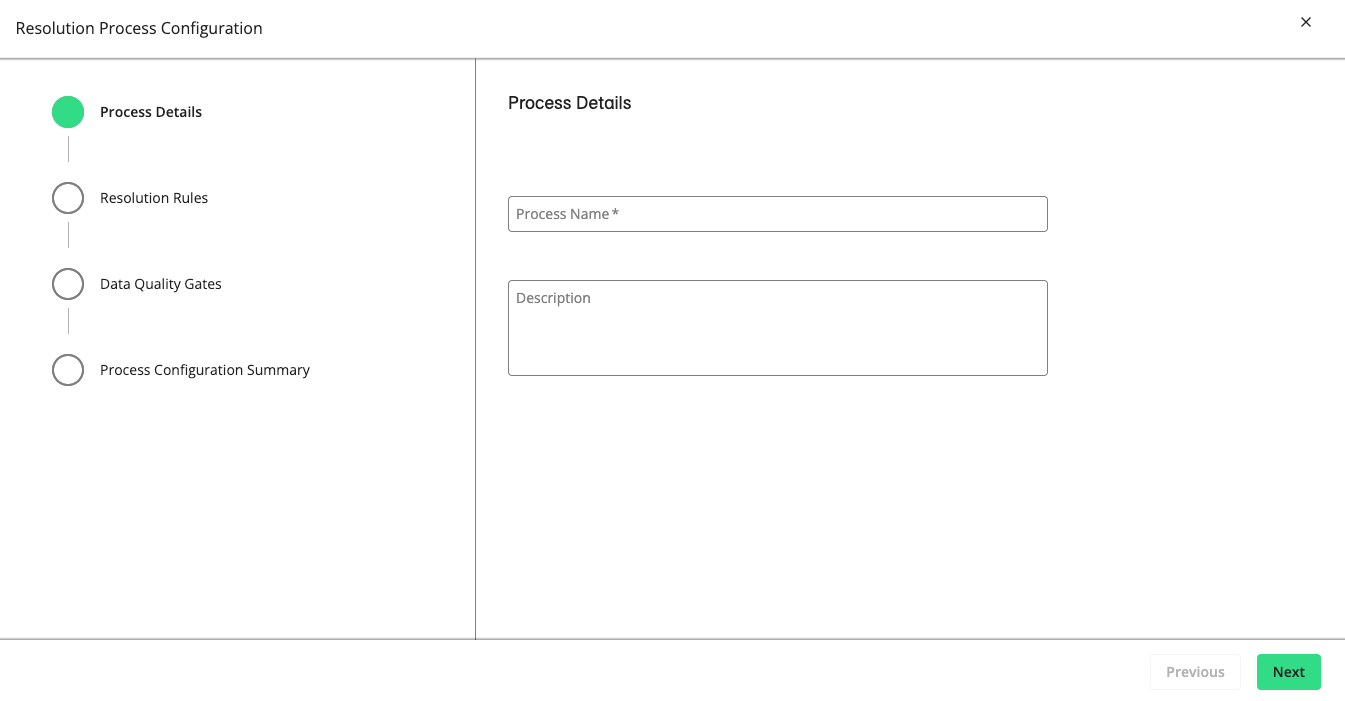
In the Process Name box, enter a name for this resolution process.
To use the LiveRamp Known Identity Graph to determine the best PII-based attributes or AbiliTec link information per Enterprise ID, select Determine best available attributes based on LiveRamp Graph.
For more information, see "Determining Best Available Attributes".
To use the LiveRamp Known Identity Graph to create household IDs, select Determine household based on LiveRamp Graph. Household IDs represent adults living together at the same location with a persistent relationship based on PII.
In the Description box, enter any important details about this resolution process so that other users understand this configuration.
Click .
Click . A new blank rule is added to the Resolution Rules step.
To configure the new rule, click to expand its entry, then give it a name, a group limit, match conditions, and filter conditions. Each rule must have at least one strict match condition. For information, see "Resolution Rules".
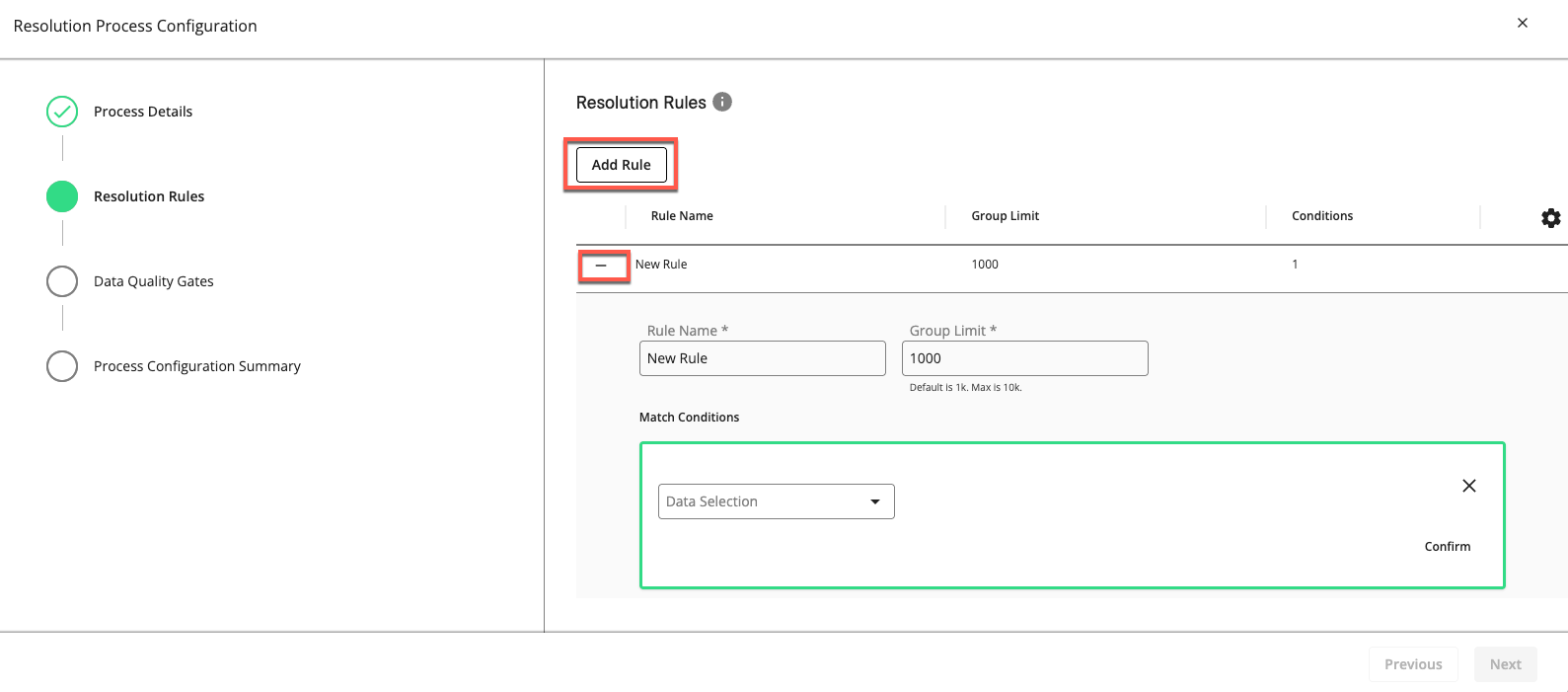
If you want to add another rule, click and configure it.
Tip
If you configure multiple rules, they are run in parallel (OR logic), so the order in which they appear in the configuration wizard does not impact the outcome.
Click . The "Data Quality Gates" step displays the data fields and metrics you can monitor in the process.
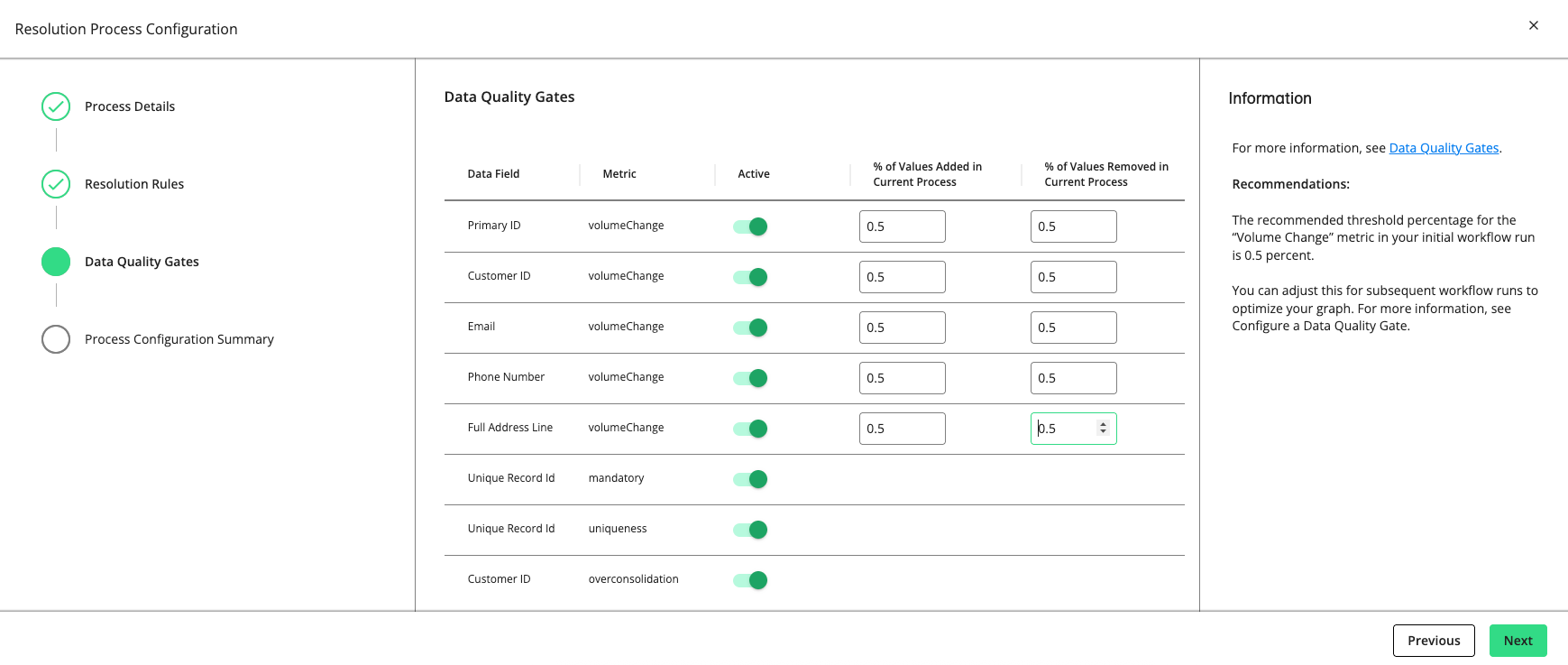
Set a gate to “Active” to have the gate monitor the quality of your data in this process by the metric listed (e.g., “volumeChange”, “mandatory”, “uniqueness”, “uniquenessByGroup”, etc.).
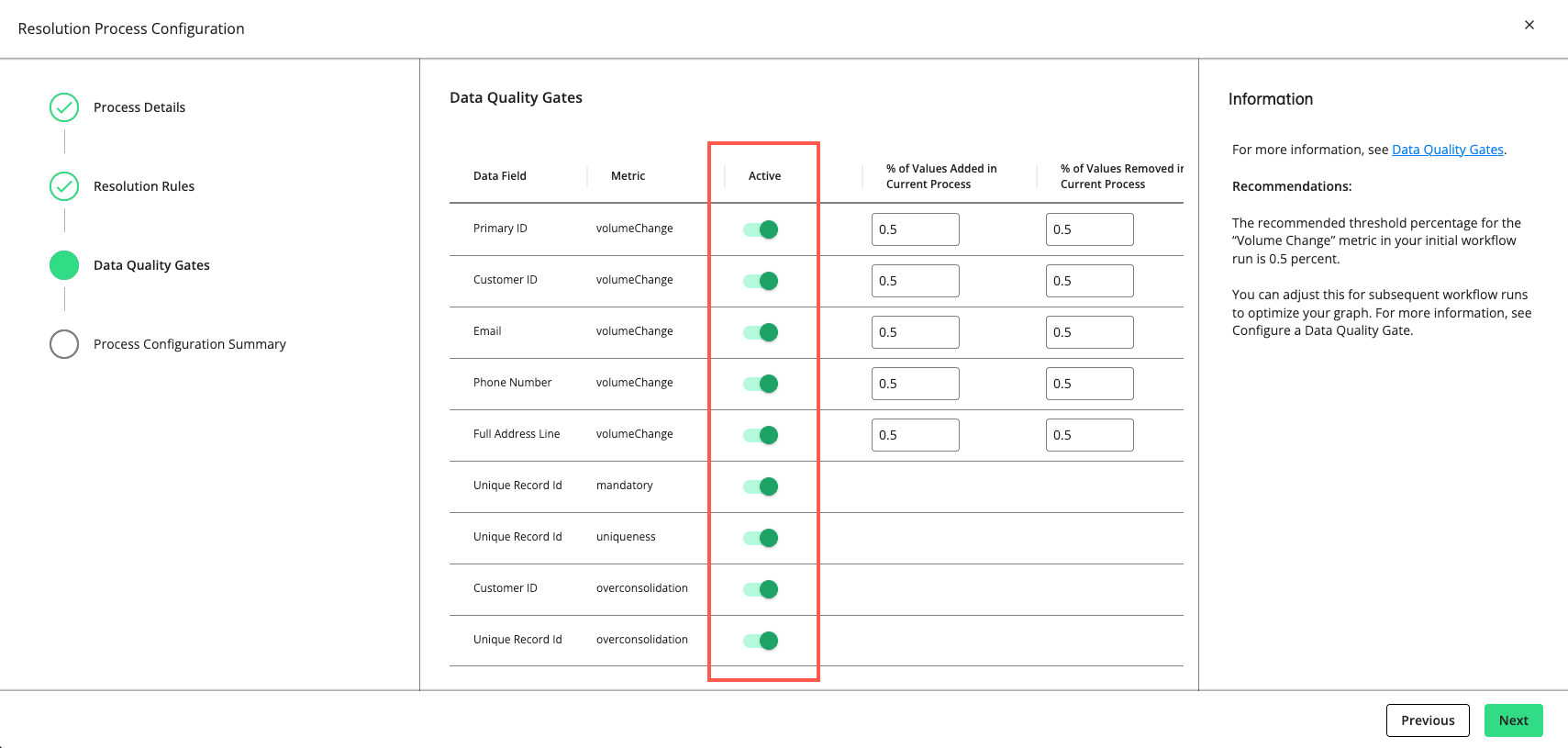
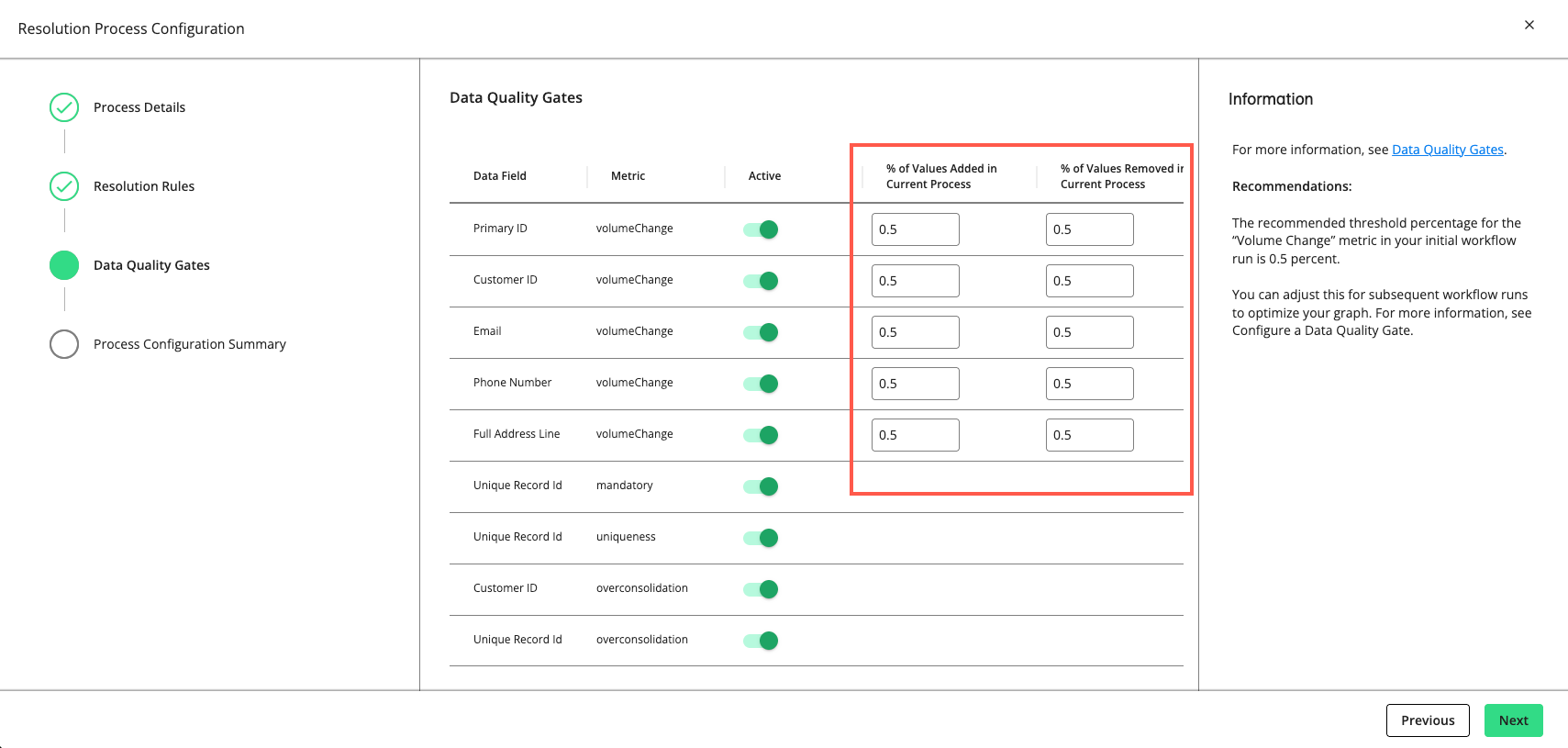
For rows with a "volumeChange" metric, you can adjust the allowable percentage of values added or removed compared to the total volume of the previous run. The default threshold is 0.5 percent. If the percentage of change exceeds the allowed percentage, the gate will cause the process to fail.
Note
The recommended threshold percentage for the “volumeChange" metric in your initial workflow run is 0.5 percent. You can adjust this for subsequent workflow runs to optimize your graph.
Click . The Process Configuration Summary step displays your rules, group limits and the number of conditions associated with each rule.
Click .
Note
You can only create one resolution process per workflow.
Resolution Rules
You can configure resolution rules that Identity Engine will use to group and compare pairs of records from your source files. Identity Engine applies an Enterprise ID to the resulting cluster of records that represent a person or a household. The outcome of the resolution process is your first-party graph.
These rules are reapplied each time the resolution process is run to evaluate whether pairs should remain together, be split, or be merged into a new ID cluster.
If you configure multiple rules, they are run in parallel (OR logic), so the order in which they appear in the configuration wizard does not impact the outcome.
When configuring a resolution process for an Identity Engine workflow, the Resolution Rules step provides the following set of options:
Rule Name: Enter a descriptive name to be used as a label in this wizard.
Group Limit: This automatically populated value specifies the maximum number of records to be grouped into pairs that share values specified by the resolution rules. This grouping improves performance and reduces the time needed to match records by evaluating fewer candidate key-value pairs.
For example, if the group limit for a Person Name + Email rule is set at 1000, then records that match name and email strictly are limited to components of size 1000. Components that exceed this size are filtered out as suspect data. Records that are filtered out are only excluded during pair generation and are not removed from the dataset.
You can enter a value from 1 through 10,000. High group limits are useful only for highly trusted data and well distributed in strict fields, such as name + email.
Group limit does not apply to non-strict fields, such as nullable fields and fuzzy matches. For a fuzzy name + strict email and a group limit of 1000, each email can have a maximum of 1000 records and the fuzzy name matching will be conducted within each email group.
Match Conditions: Add a match condition to specify how different data attributes should be compared and matched during the identity resolution process. Match conditions help define the criteria for matching records, ensuring that the resolution process is accurate and efficient. You must include at least one strict match method per rule. For more information, see "Identity Engine FAQs".
Match Condition Groups: You can specify two or more match conditions and additional logic as a group. For example, you could specify how many of the conditions need to match using the At Least option. Or you could show or hide certain fields using the Data Selection option and a method.
Filter Conditions: Add a filter condition to narrow down the fields considered for matching. This allows for more precise and relevant data matching. For example, you could specify that only the mobile phone type should be considered to refine the matching process by excluding less reliable data.
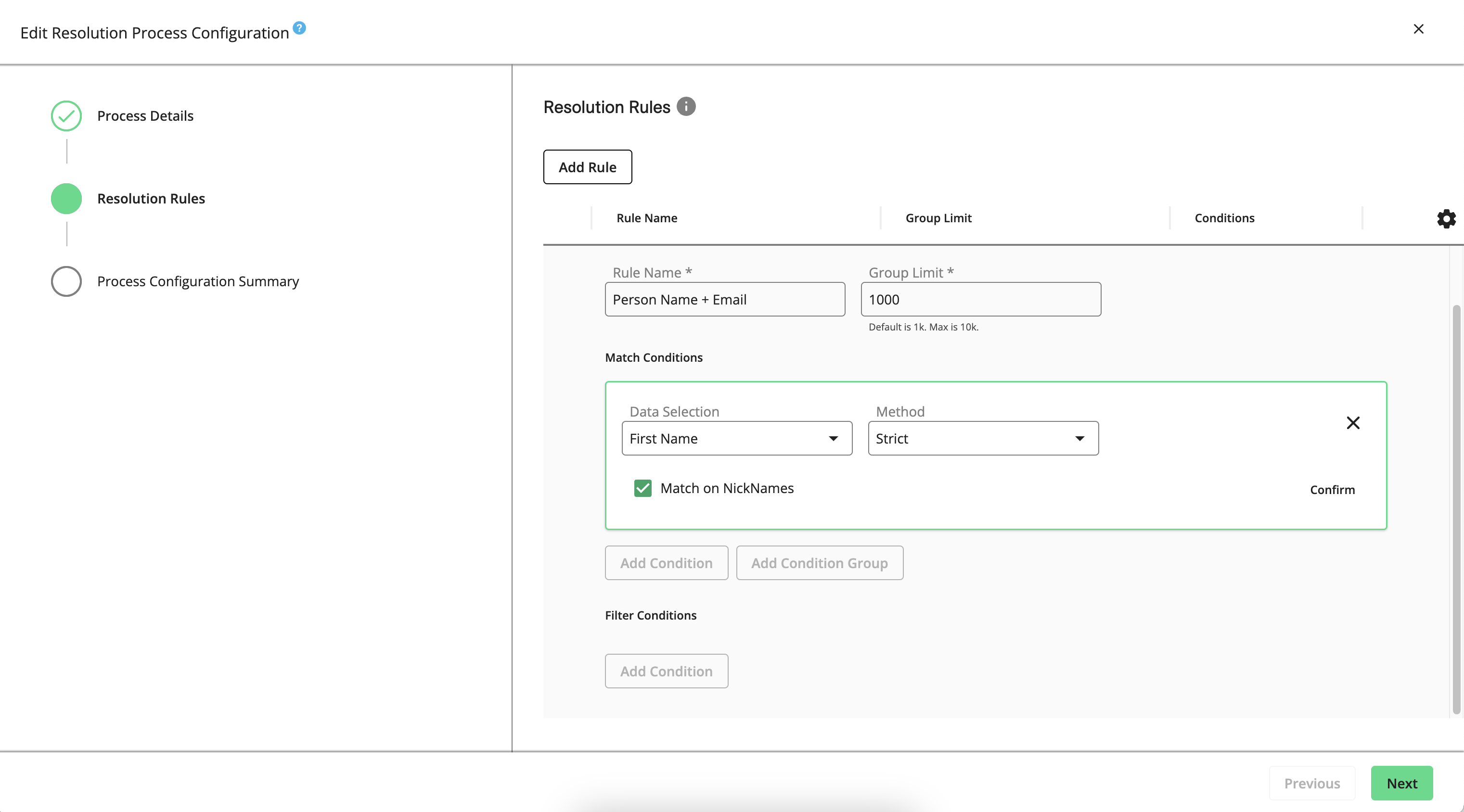
A set of rules is prepopulated in the Resolution Process Configuration wizard based on the entity mapping configuration of your data preparation process. You can modify and add to these rules as needed.
For example, if your source data contains attributes like firstName, lastName, email, and phones (along with other attributes), and during data preparation, you mapped the names, emails, and phones, the following resolution rules might be suggested:
Person Name + Email
Person Name + Phone
In both rules, the email or phone and the last name are set to the strict method. However, the first name will be set to fuzzy matching with the "Match on Nick Names" option.
Match Methods Per Entity
Within a rule, there must be at least one strict match condition. For example, if your rule specifies the Fuzzy Score method for First Name and Last Name, you must also specify the Strict match method for at least one entity, such as Email.
Entity | Available Match Methods | Options |
|---|---|---|
AddressLink | Strict | |
ConsumerLink | Strict | |
Custom Fields |
| |
Customer ID | Strict | |
Date Of Birth |
| |
Strict | Match on Gmail Isotopes (i.e., remove ".") | |
First Name |
| Match on nickname |
HouseholdLink | Strict | |
Last Name |
| |
Name (Address) |
| |
Name (Email) |
| |
Name (Phone) |
| |
Phone Number | Strict | |
Postal Code | Strict |
* Requires additional configuration parameters to define the precision of the method
Resolution Logic
Logic | Description |
|---|---|
First N Char | Match on the first N characters of the field. For example, "Robert" and "Rupert" match on the first 1 characters. |
Fuzzy Score | Use fuzzy matching on a similarity score between strings and consider various transformations and substitutions. For more information, see "approximate string matching". |
Jaccard | Calculate the similarity of two strings based on the number of common characters divided by the total number of unique characters. The closer to 1, the more similar the two strings. For example, "Robert" and "Rupert" yield a Jaccard similarity of 0.5. For more information, see "Jaccard index". |
Jaro | Measure the similarity between two strings on a scale from 0 (no match) to 1 (identical), with an emphasis on matching prefixes and adjusting for common typos or variations. For example, "Robert" and "Rupert" yield a Jaro similarity of 0.778. For more information, see "Jaro–Winkler distance". |
Levenshtein | Calculate the minimum number of single-character edits (insertions, deletions, or substitutions) needed to change one word to another. For example, "Robert" and "Rupert" yield a Levenshtein distance of 2 (substitute "u" for "o" and "p" for "b"). For more information, see "Levenshtein distance". |
Soundex | Index names by sound, retain the first letter of the name and calculate a 3-digit numerical code for the remaining letters. For example, "Robert" and "Rupert" yield a Soundex code of R163. For more information, see "Soundex". |
Strict | Requires an exact match. |
Sample Resolution Rules
Sample Rule | Description |
|---|---|
cLink + matchConfidence ≤3 | ConsumerLink matches with a match confidence of 1, 2, or 3. For more information, see "Using ConsumerLinks" and "Match Metadata". |
Email + source=ecommerce + (Soundex of FirstName OR LastName OR StreetAddress OR Phone Match) | Email matches, the source is from the "ecommerce" database, and any of the additional matches. |
Fuzzy First Name + Strict Last Name + Email | Use fuzzy matching of the First Name, an exact match of the Last Name, and a normalized email match. |
Fuzzy First Name + Strict Last Name + Phone | Use fuzzy matching of the First Name, an exact match of the Last Name, and match one of the provided phone numbers (home, mobile, or work). |
Strict Name + AddressLink | Require an exact match of the First Name and Last Name, and the AddressLink for the physical address. For more information about AddressLink, see "AbiliTec Link Types". |