Question Builder Best Practices
LiveRamp Clean Room's Question Builder provides a UI for building questions using SQL queries, runtime parameters, and report configuration.
To ensure that your query is valid and properly configured, consider the following data, SQL, and report configuration guidelines.
Data Validation
To improve the performance of your question runs and the validity of your analytics, perform data validation before connecting your data source to LiveRamp Clean Room. This can significantly reduce processing time once the data is connected.
When validating your data in your own environment, capture certain metrics so that you can verify success once it is connected to your clean room. For example, you might collect the following metrics depending on your use case:
Number of rows
Earliest and most recent dates in the table
Number of unique conversions
Number of unique custom IDs (CIDs)
Number of unique invalid CIDs (an invalid value is typically preceded by a "-" character)
Number of unique valid CIDs
Number of unique RampIDs
Count of valid CIDs with a RampID
Count of valid CIDs without a RampID
Fill rate (the percentage of rows within a dataset that have a valid, non-null value in the field) for various columns, such as:
Conversion_Date
Gross_amt (this might be your "order_value", "transaction_amt", etc.)
RampID or other identifier (each row must contain an identifier)
Transaction_ID
For more information, see "Data Connection Best Practices".
Schema Considerations
Use cases: Follow the recommended data schemas for your clean room collaboration use cases.
Same schema: All tables within a single data connection job must have the same schema. If you have multiple types of schemas, create a new data connection for each one.
Column order: The order of the columns should match the schema.
Column header assignment: Verify the accuracy of your field labels and avoid ambiguous field names. Work with your LiveRamp representative to align your dataset's column headers, use standardized field names where possible, and discuss field mapping. If LiveRamp provides Clean Room templates or reference schemas, adopt these names when feasible to speed onboarding and avoid ongoing confusion.
Data types: Ensure that data types align with your expected schemas. LiveRamp Clean Room supports the following data types:
array
Boolean
date
decimal
double
integer
long
string
timestamp
Note
LiveRamp Clean Room does not currently support MapType or StructType field types.
ArrayType is only supported for AWS, GCS, and Iceberg connections.
Boolean may not be selectable for output schema, but it is supported at the data connector or field mapping level.
For more information, see "Field Types Supported in LiveRamp Clean Room".
Identically Named Dataset Types
When two dataset types (tables) are named identically, as shown in the following screenshot, LiveRamp Clean Room maps the table that is first referenced in the SQL code. The two or more originally identically named tables can be referenced in the SQL code as UserData1, UserData2, and so on.
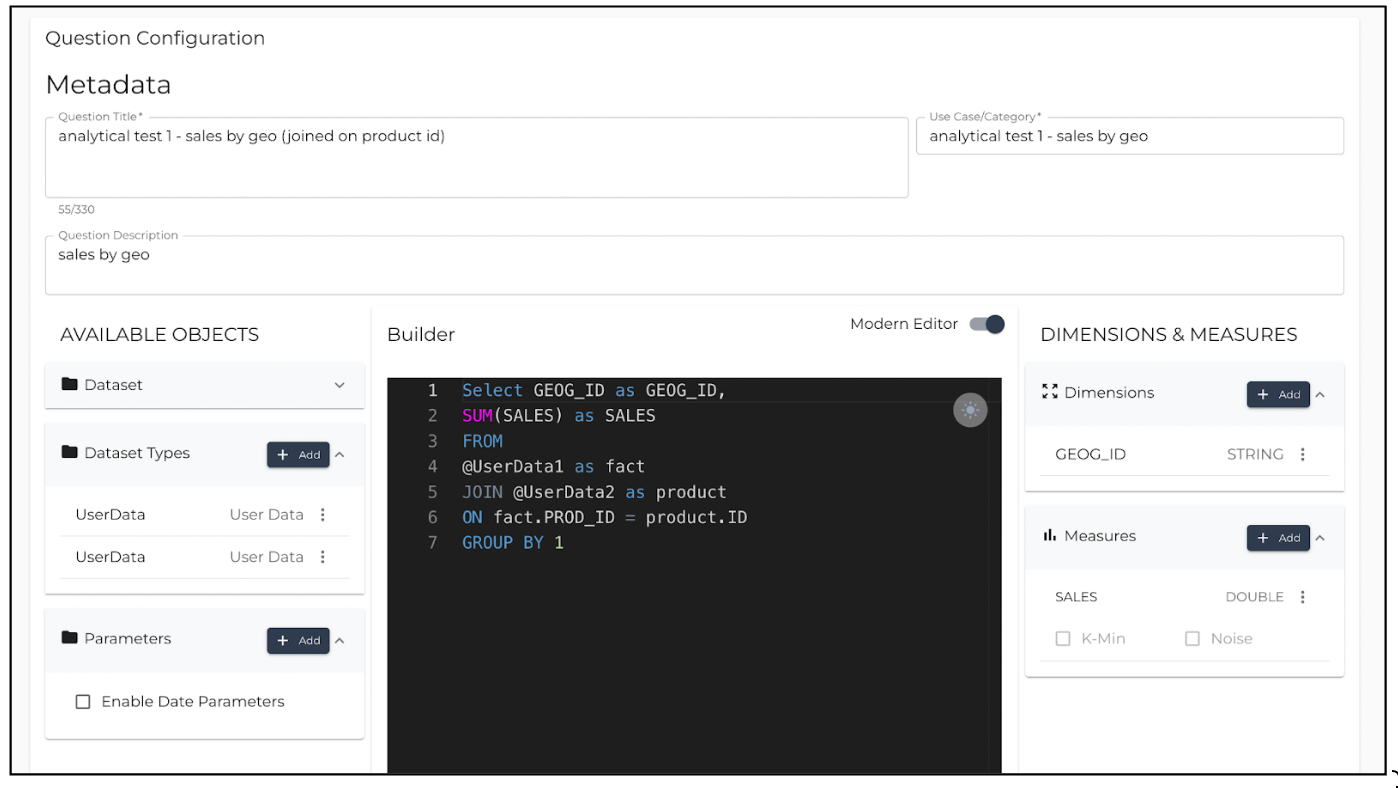 |
Table Names Are Case-Sensitive
For example, @AdLogs is correct and @adlogs will return a runtime error. To avoid this, copy the table names with @ aliases from the left-side pane where the dataset types are displayed and paste them into Query Builder.
Correct Version:
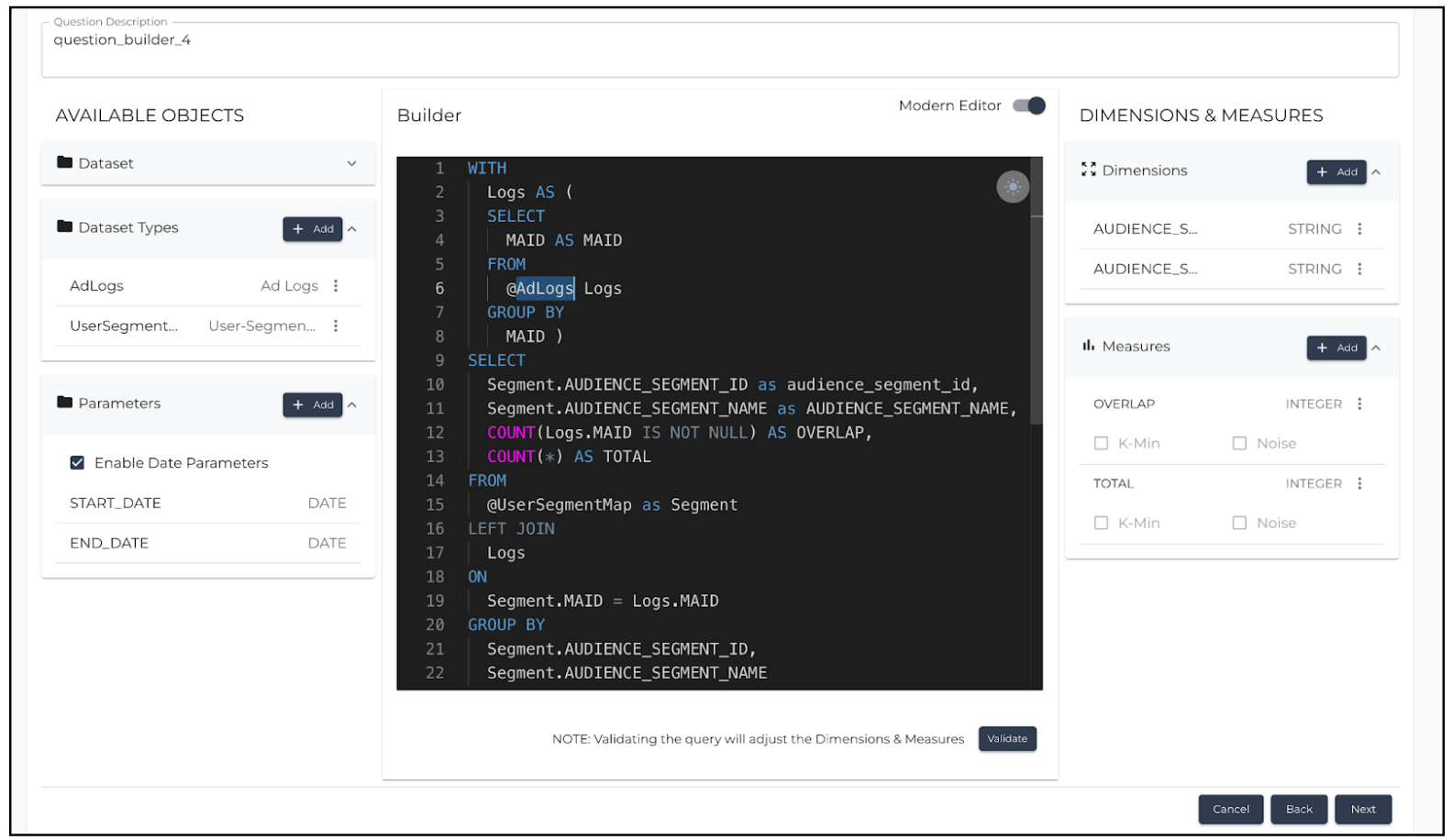 |
Incorrect Version:
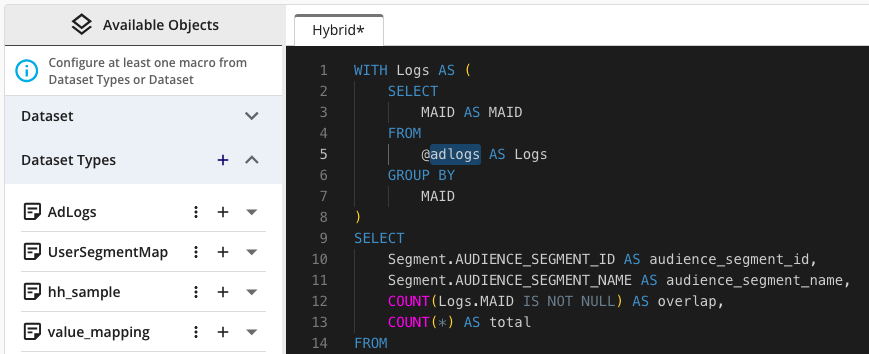 |
When the dataset type is not written in a case-sensitive manner, you will see a "Failed" error message at runtime that indicates the line number.
Question Name and Category Are Mandatory Fields
Question Name and Category are mandatory fields for saving the query and moving to the next screen.
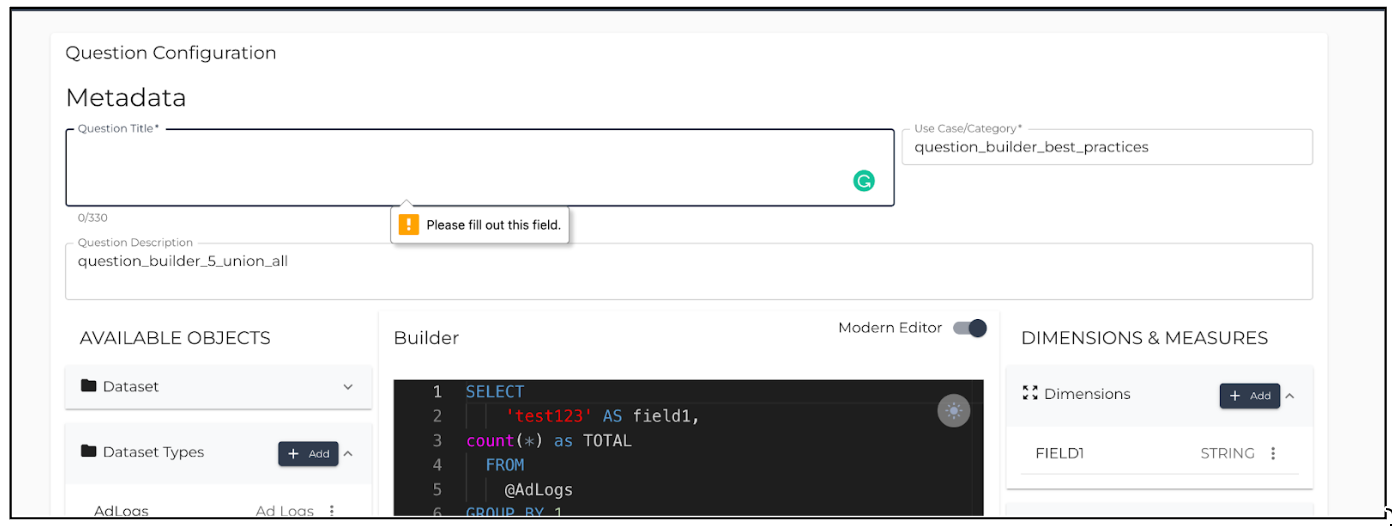 |
Unique Question Names
Each question is assigned a unique ID, but it is possible to have duplicate question names. To avoid duplication and confusion, create unique question names and enter a description to help your team identify and understand each question.
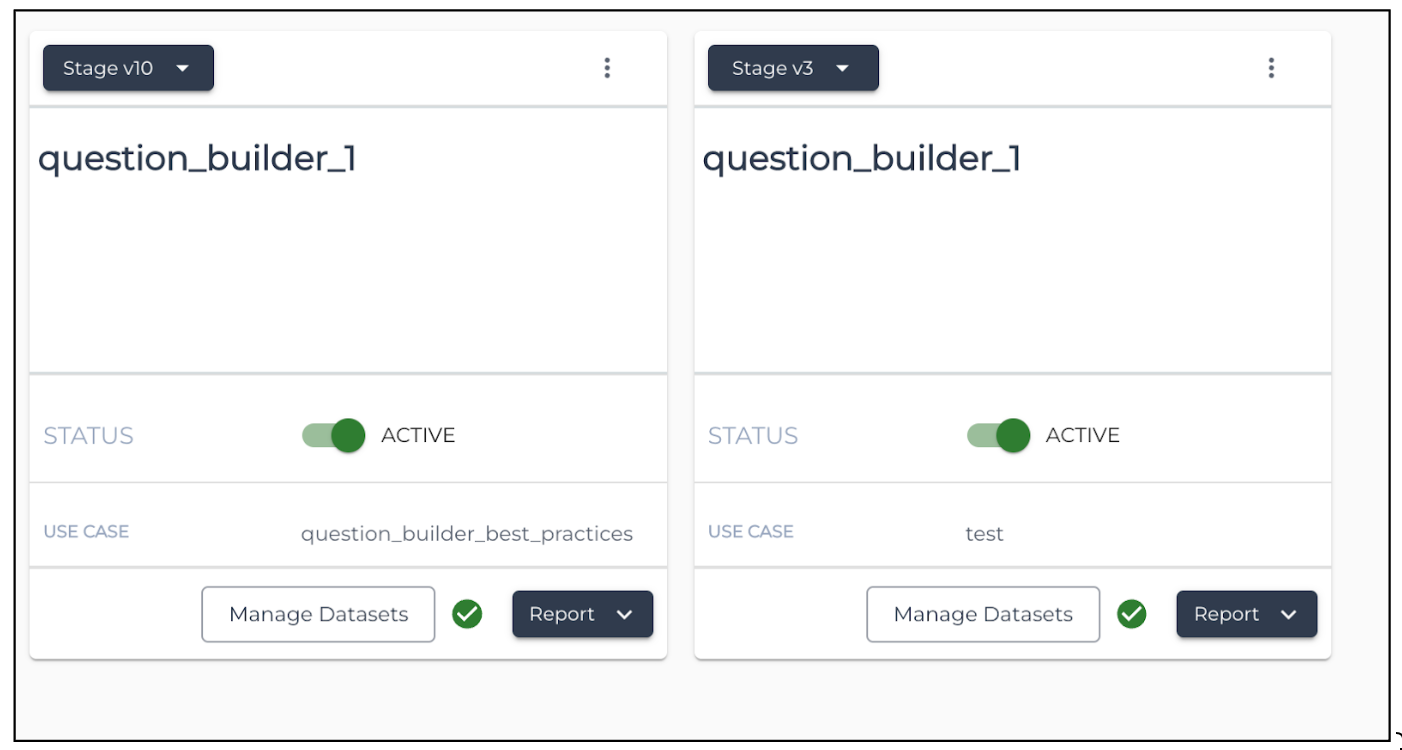 |
Using Runtime Parameters
You can add runtime parameters that act as dynamic variables within your code.
Click in the Parameters section to add a parameter.
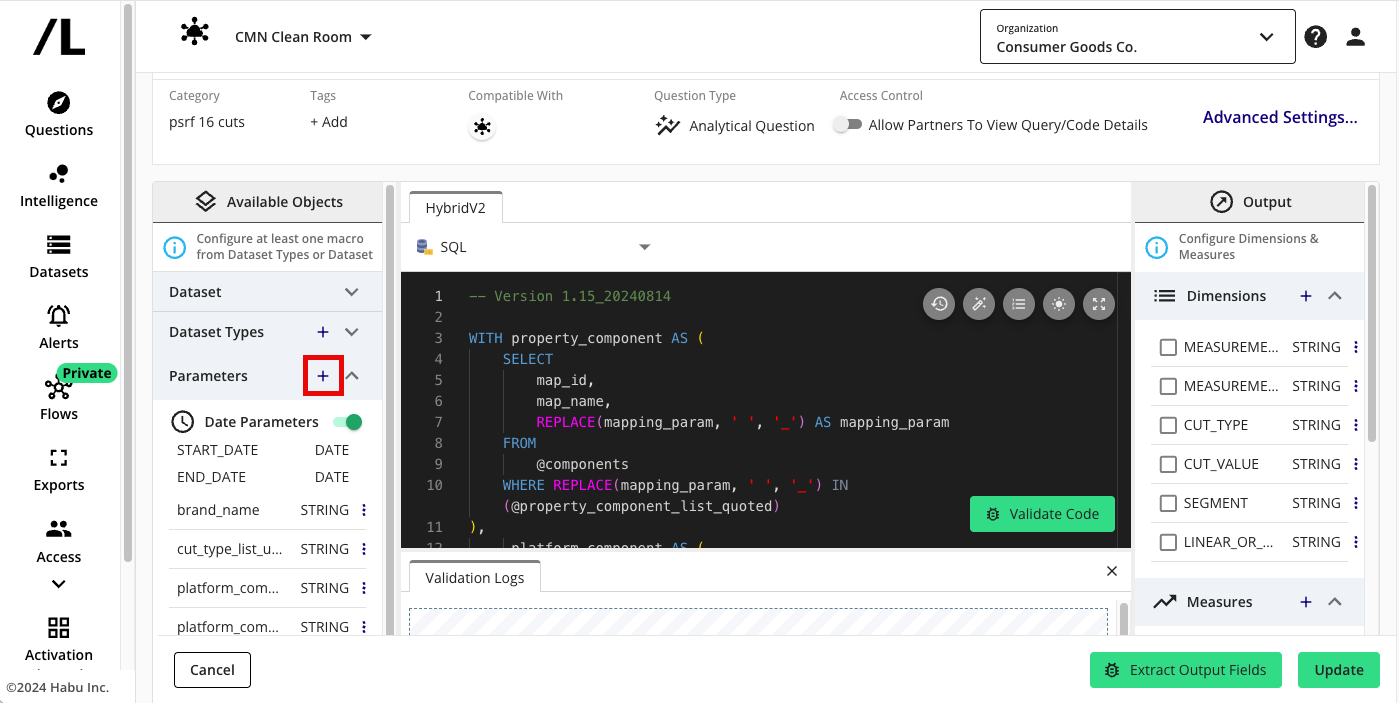
For example, to get results for different cuts of data, your partner can specify a runtime parameter value to use for a specific question run. To enable your partner to run the same query on multiple campaigns, you could provide a @campaign_id runtime parameter. Your partner would be asked to specify the ID or set of IDs they want the question to use to filter the data.
Space in a Parameter Name
Question Builder does not accept space characters in parameter names. Errors will be displayed if spaces are included and will indicate the row number in your query.
Validating a Query
When you click in Query Builder, a range of important things are checked, including:
Macro formatting: The dataset macros must be properly populated in your SQL query.
SQL dialect: Your query must be compatible with the SQL dialect used by the type of clean room. For information, see "SQL Guidelines" below.
SQL errors: Indicates an issue with the SQL that requires review and repair of the code. Issues may relate to missing SELECT statements, commas, unknown commands, and so on.
Data type: The data types of your inputs and outputs must be aligned with the data types used in your query.
Adding an incorrect or unexpected data type for a dimension or a measure in the right-side pane in Question Builder will result in a runtime error.
You can confirm the data types of various dimensions and measures for the valid datasets (or tables) that are available in the left-side pane under Dataset.
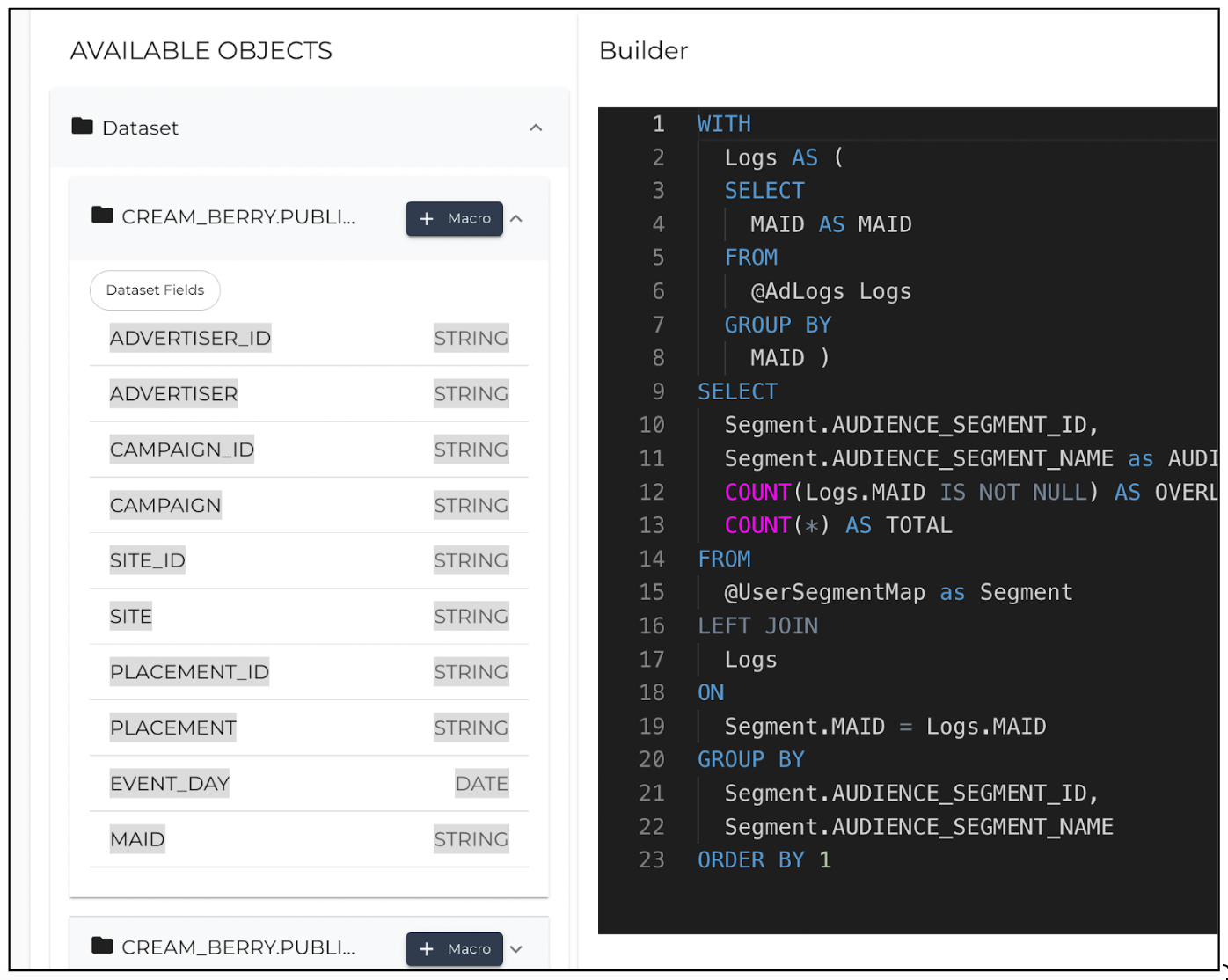
Misaligned dimensions and measures: Sometimes, validating a query will adjust the dimensions and measures, so it is important to confirm the dimensions and measures by removing and re-adding them in the right-side pane.
In the following example, there are two dimensions and two measures. When clicking Validate Code below the Query Editor, the engine running in the background automatically aligns all the fields. If the SQL validator doesn't align the metrics, manually remove the measures from the dimensions list and add them to the measures list.
Permission issues: If your SQL and Question Builder settings are correct and you continue to receive static or runtime errors when you click Validate, contact your LiveRamp representative.
Availability of Dimensions and Measures in the Right-Hand Pane
The Dimensions and Measures associated with the main Select statement must be present in the Question Builder screen's right pane.
A dimension is a field in your data that can be used to aggregate the data, such as campaign name or device type. A measure is a fact that represents the count or sum of a field, such as the count of impressions or the sum of sales.
You must specify dimensions and measures. Otherwise, the Report Configuration step will not make those fields available in charts and tables. The Question Configuration screen will not indicate that you are missing dimensions or measures.
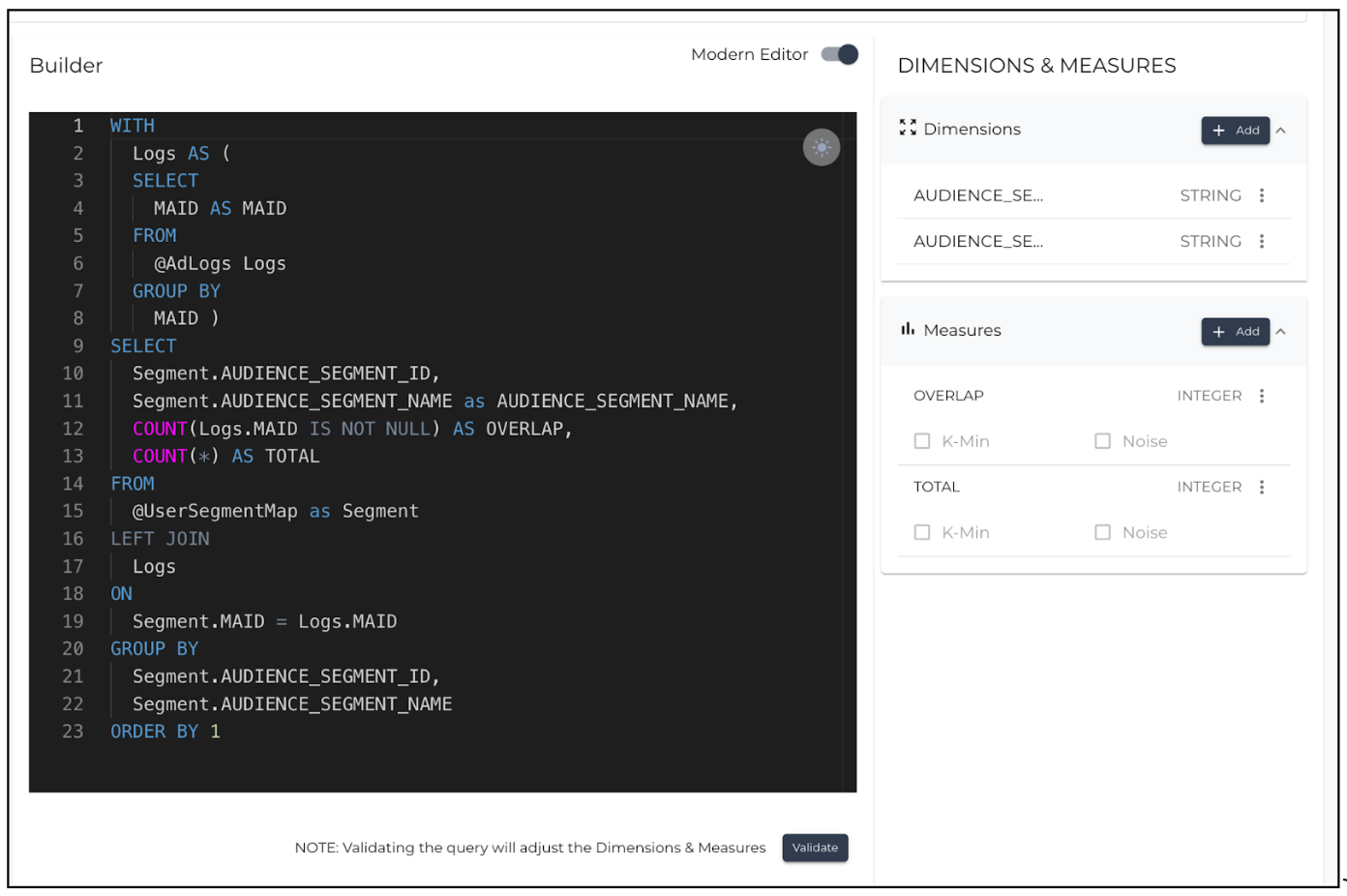
The button and the right-hand pane won't stop you from continuing unless the right pane is empty. For example, consider a main Select statement where there are two dimensions (audience_segment_id and AUDIENCE_SEGMENT_NAME) and two measures (OVERLAP and TOTAL). In the right-side pane, only one dimension and two measures will be displayed. This will not be highlighted as an error on the Question Configuration screen, and the missing field (in this case, the audience_segment_id) won't appear on the Report Configuration screen.
To automatically populate the dimensions and measures in the right-hand pane, click . For information, see "Validate Dimensions and Measures".
At least one measure and one dimension are mandatory for the query to be valid, and you will receive an error message if either is empty. Keep both dimensions and measures in the main Select statement so they are available for Report Configuration.
When using field aliases in the main SELECT statement, all the measures must have an alias so that they get picked up by the Report Configuration layer. The following screenshot shows how measures are aliased in the main Select statement.
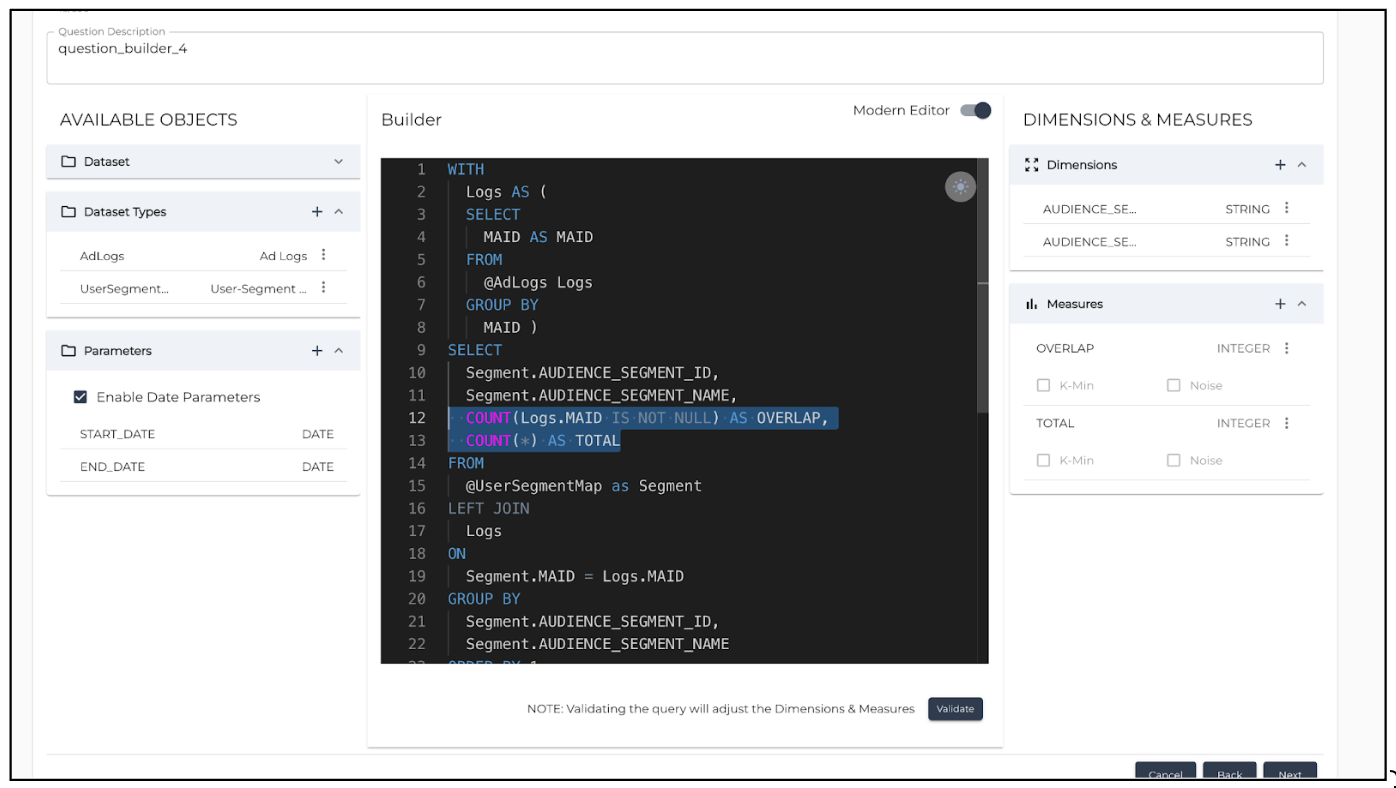 |
Adding Dimensions and Measures in the Right-Hand Pane
If you want a field to represent a dimension instead of a measure, add it to the list of dimensions. You can also move dimensions to the measures list.
If the dimensions and measures are not placed correctly in the respective groups, query results will impact the chart or the format of the fields. For example, if a campaign ID is saved as an integer, then campaign ID 1234 will appear as 1.23k.
Adding incorrect values can also create conflicts if dataset analysis rules are configured for the assigned datasets. For information, see "Set Dataset Analysis Rules".
Field‑Level Encryption for List Exports
If enabled for your organization and supported by the cloud to which you want to export your list question results, you can mark fields to be encrypted in Question Builder.
Field‑level encryption is generally supported for list exports to S3, GCS, and Azure. For more information about cloud support for list exports, see "Export Results to a Cloud".
For example, you might want to encrypt user identifier fields for extra protection during data transfer.
Open the list question with the fields that you want to be encrypted.
In the Output section, select Edit for a field. The field is displayed in Edit mode.
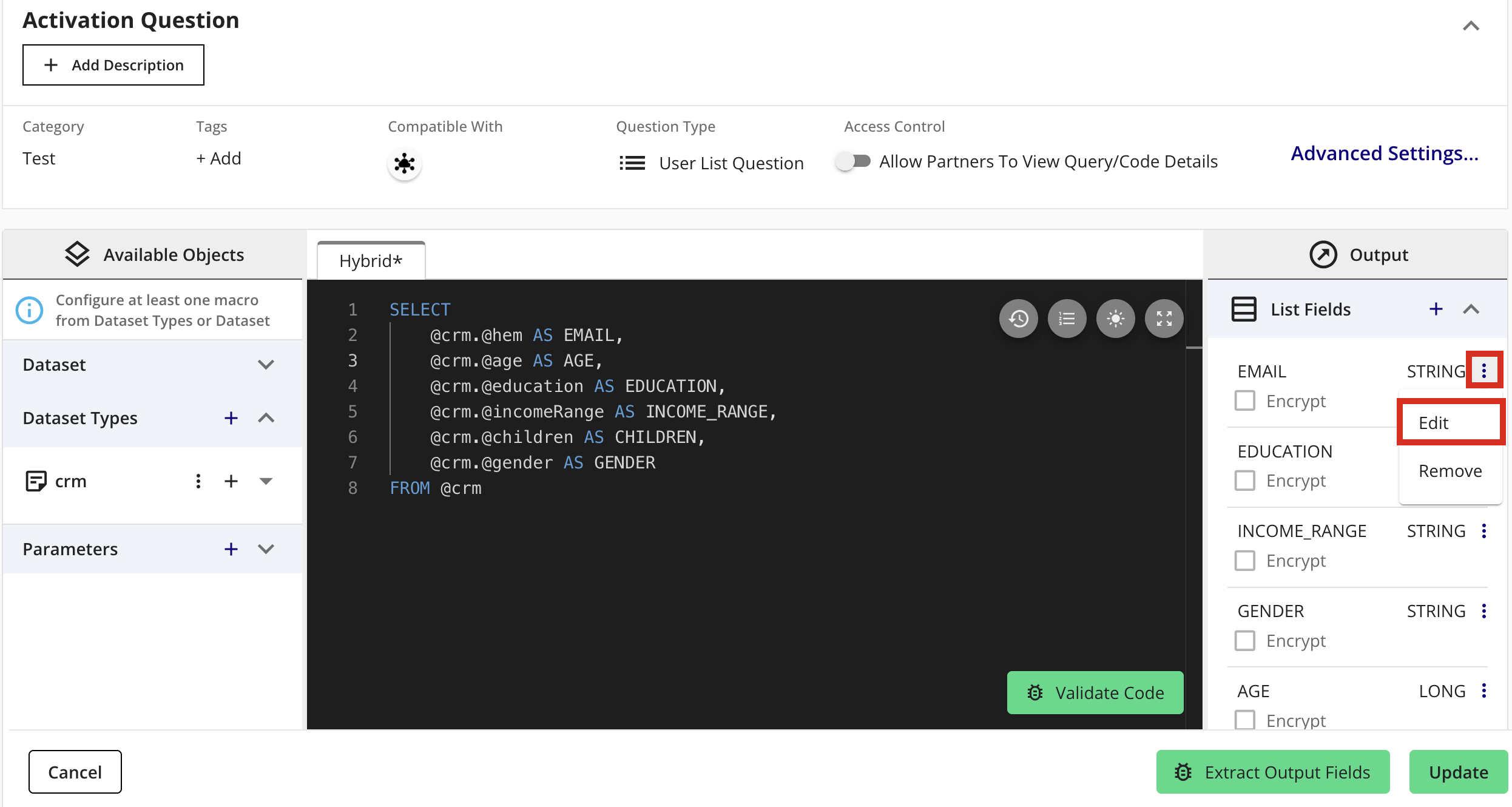
Select Encrypt and then click .
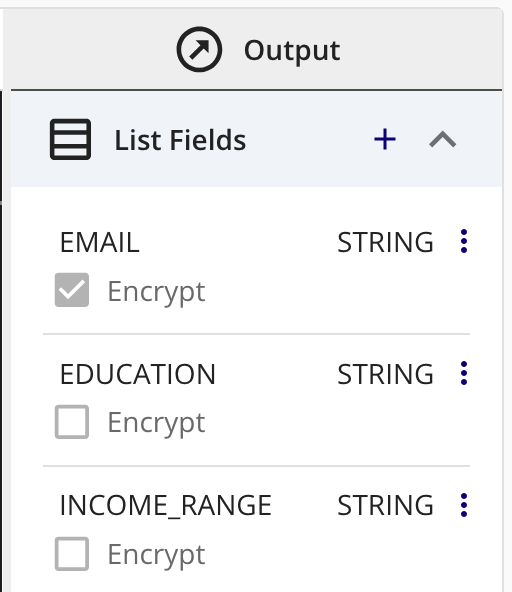
The field indicates that Encrypt is selected.
SQL Guidelines
Note
LiveRamp is committed to maintaining the integrity of its clean room architecture, so certain SQL statements and Python packages are not yet supported. To request a security evaluation for specific clauses or packages, contact your LiveRamp representative.
Depending on the types of clean room you are using, Question Builder supports certain SQL dialects:
AWS supports a limited set of SQL functions. For information, see "Overview of SQL in AWS Clean Rooms".
Azure confidential computing supports Apache Spark SQL. For information, see "Spark SQL".
BigQuery supports the GoogleSQL dialect. For information, see "Introduction to SQL in BigQuery".
Databricks supports ANSI-compliant SQL and Python. For information, see "ANSI compliance in Databricks Runtime" and "Databricks SQL Connector for Python".
Hybrid clean rooms support Spark SQL. Hybrid clean rooms with Clean Compute also support PySpark. For information, see "PySpark Overview".
Snowflake supports Snowflake SQL and Python via Snowpark. For information, see "Query Data in Snowflake" and "Snowpark Developer Guide for Python".
Using a UNION (or UNION ALL) in the Main Select Statement
The main SELECT statement cannot have a UNION set operator. Remove UNION queries that are not within a subquery.
As an alternative, create a common table expression (CTE) where the UNION is followed by using the CTE in the main SELECT statement.
Filtering Joins to Determine CID-to-RampID Mapping
You can use a join operation to combine rows based on a related column from two or more tables to create a combined row that is used in the query. This can help determine CID-to-RampID recognition rates if you filter out rows with inapplicable values, such as the following:
Deleted: Deleted records typically appear as
0ordel%, depending on when the deletion occurred.No identifier: Records that lack an identifier typically appear as
NULLorUNMATCHED, depending on where the data originated.
Example of two tables joined on their CID columns:
COUNT (DISTINCT CID) AS recognized_CIDs
FROM client_table t1
INNER JOIN mapping_table t2
on t1.CID = t2.CID
WHERE t2.rampid LIKE 'X%'
OR t2.rampid LIKE 'h%'Where:
client_tableincludes a CID column but lacks a RampID column.mapping_tableincludes a CID column and a RampID column to establish the relationship between these identifiers on each row.X%refers to various prefixes for RampID types that begin with X.h%refers to the prefix for household RampIDs.
For information about RampIDs, see "RampID".
Caution
When performing RampID-to-RampID joins where transcoding is enabled, you should not include additional filtering. Transcoding includes data transformations that would render an incorrect result if filtering is applied.
Cache Tables
Questions used in hybrid clean rooms with Clean Compute (HCC) support cache tables, which store tables or query results in memory for repeated use within your query. Minimizing disk I/O operations reduces the computation time for subsequent queries and provides performance advantages compared to using common table expressions (CTEs), which are recomputed each time they are referenced in a query.
You can include cache tables in your queries to improve the performance of machine learning algorithms and iterative computations that repeatedly access the same datasets.
Example cache table:
CACHE TABLE cached_table OPTIONS ('storageLevel' 'MEMORY_AND_DISK') AS SELECT COUNT(@ads.CAR_MAKE) AS field FROM @ads
SELECT field FROM cached_tableWhere:
cached_tableis a descriptive name of the new cached table you are creating and then referencing in your query.MEMORY_AND_DISKspecifies the storage level for the cached data. Other options includeMEMORY_ONLYorDISK_ONLY.@adsis a macro that refers to the dataset you want to use. Replace this with the actual dataset to be queried.@ads.CAR_MAKEis a macro that refers to the column within the @ads dataset. Replace this with the specific column you want to count.
Overall Steps and Example Code
Cache intermediate results:
CACHE TABLE monthly_aggregates AS SELECT customer_id, DATE_TRUNC('month', order_date) AS month, SUM(amount) AS monthly_total, COUNT(*) AS order_count FROM orders WHERE order_date >= '2025-01-01' GROUP BY customer_id, DATE_TRUNC('month', order_date);Use your cached table in a query:
SELECT customer_id, AVG(monthly_total) AS avg_monthly_spend FROM monthly_aggregates GROUP BY customer_id;
Use your cached table in another query:
SELECT month, COUNT(DISTINCT customer_id) AS active_customers FROM monthly_aggregates GROUP BY month ORDER BY month;
(Optional) Uncache your table when done:
UNCACHE TABLE monthly_aggregates;
Cleaning up is not necessary, because the question is executed in a single Spark session.
Warning
Only use semicolons as the delimiter between statements in multi-statement SQL queries (for example, to separate CACHE or UNCACHE statements from SELECT statements). Do not use semicolons for other purposes, such as in comments, even if it is valid SQL code, because the validator used for question runs considers semicolons to indicate the end of a SQL statement.
Aggregation Thresholds
Dataset owners can create dataset analysis rules to specify a minimum aggregation threshold to preserve privacy based on their organization's risk tolerance. The data owner can set the aggregation threshold for any field considered to be a user identifier field, such as a customer ID, RampID, or loyalty ID.
When you create your query, you can specify a numeric value with an aggregation clause. It is typically recommended that you use the AGG_THRESHOLD macro, which serves as a placeholder for whatever aggregation threshold is specified for the dataset. Omitting an aggregation threshold risks failing validation.
For example, assume you want the SUM of a sales figure each day in transaction data from a partner, and your partner has enforced an aggregation threshold of 75 on their loyalty_id field. Without the aggregation threshold rule, you might attempt to run a query such as the following:
SELECT @transaction_table.@transaction_date AS txn_date, SUM(@transaction_table.@sales_amount) AS total_sales FROM @transaction_table WHERE txn_date BETWEEN '2025-01-01' AND '2025-01-31' GROUP BY txn_date ;
This query will fail validation if an aggregation threshold analysis rule is in place. You could include an aggregation of at least 75 on loyalty_id as follows:
SELECT @transaction_table.@transaction_date AS txn_date, SUM(@transaction_table.@sales_amount) AS total_sales FROM @transaction_table WHERE txn_date BETWEEN '2025-01-01' AND '2025-01-31' AND GROUP BY txn_date HAVING COUNT(DISTINCT @transaction_table.@loyalty_id) >= 75 ;
Note
Aggregation threshold enforcement is required for any identifier field where an aggregation threshold analysis rule has been explicitly applied. If rules are applied to multiple identifiers (e.g., a RampID field and a household CID field), they are combined using AND logic, meaning the query must satisfy the thresholds for all restricted identifiers. For example:
HAVING COUNT(DISTINCT rampid) >= 50 AND COUNT(DISTINCT hcid) >= 50
This approach will pass the analysis rules validation. However, you may not always know if your partners' datasets have aggregation threshold rules in place and what their threshold values are. In such cases, the best practice is to use our alternative option for dynamically allowing a query to enforce an aggregation threshold without needing knowledge of what the threshold value should be. This uses the appended _AGG_THRESHOLD macro in place of a hard-coded integer using the following syntax:
@table_name.@field_name_AGG_THRESHOLD
Where: You replace table_name with your dataset macro and field_name with your field macro and append _AGG_THRESHOLD.
The above query would be rewritten to support this as follows:
SELECT @transaction_table.@transaction_date AS txn_date, SUM(@transaction_table.@sales_amount) AS total_sales FROM @transaction_table WHERE txn_date BETWEEN '2025-01-01' AND '2025-01-31' AND GROUP BY txn_date HAVING COUNT(DISTINCT @transaction_table.@loyalty_id) >= @transaction_table.@loyalty_id_AGG_THRESHOLD ;
When the _AGG_THRESHOLD macro is used, LiveRamp will check whether an aggregation threshold rule is applied to the referenced dataset. If not, we will dynamically replace this value in your query with 0, and if so, we will replace it with the value for the specified aggregation threshold. It is best practice to use the _AGG_THRESHOLD macro in all cases, so you can reuse questions across collaborations and develop questions for multiple partners who may have varying aggregation thresholds depending on their organizations' privacy policies.
Note
The aggregation threshold that the data owner specifies in their dataset analysis rules is different than the Crowd Size option that can be set when editing a clean room. Crowd Size applies a k-min value selected at the clean room level by the clean room's owner to the output values of selected measures. For more information, see "K-min Results Output Enforcement".
By comparison, the aggregation threshold set by the dataset owner requires validation that your query adequately enforces the threshold rule on input. If a dataset's analysis rules include an aggregation threshold, the query must consider this rule by including the appropriate HAVING or WHERE clause at each point of aggregation.
Managing GROUP BY Statements
When aggregation threshold rules are in place, you may run into challenges with GROUP BY statements in intermediary CTEs, which group records based on fields with relative uniqueness in value options.
For example:
WITH txns AS ( @transaction_table.@transaction_date AS txn_date, @transaction_table.@loyalty_id AS loyalty_id, SUM(@transaction_table.@sales_amount) AS total_sales FROM @transaction_table WHERE txn_date BETWEEN '2025-01-01' AND '2025-01-31' AND GROUP BY txn_date, loyalty_id ), -- rest of query...
The CTE groups records by txn_date and loyalty_id to maintain the integrity of each row. Constructions like this are also often used to filter datasets to relevant subsets for query optimization or perform deduplication, and are valid conditions for the query. The problem here is that we want to enforce that at least 75 unique loyalty_id values are included in the generation of this CTE, but the group by txn_date, loyalty_id and total_sales for each combination means that we will have a limited number of records in each group by (assuming a single individual is not making more than 75 transactions in one day). This will fail the analysis rule if there is no HAVING clause, but it will result in no output if the HAVING clause is there.
The analysis rule validator will always look for thresholding at the point of aggregation, so the solution to this problem is to maintain the group by and ensure you are carrying the loyalty_id field through every subsequent CTE until you perform the final aggregation, in which it is no longer referenced.
It is acceptable not to perform the aggregation threshold check in a CTE if:
You keep the identifier field in every step (SELECT it in every CTE).
You then apply the aggregation threshold (via HAVING) in the final aggregation. The identifier field must be used in an aggregation at some point in the chain if it has been projected in a CTE, even if that particular aggregation is not needed for the final output. This ensures the data owner's policy is enforced.
This means your question is saying:
"I’ll carry the identifier with me through the whole query journey, and only do the privacy check near the end."
This is illustrated in the following example:
WITH txns AS ( @transaction_table.@transaction_date AS txn_date, @transaction_table.@loyalty_id AS loyalty_id, SUM(@transaction_table.@sales_amount) AS total_sales FROM @transaction_table WHERE txn_date BETWEEN '2025-01-01' AND '2025-01-31' AND GROUP BY txn_date, loyalty_id ), customer_segmentation AS ( @segment_table.@segments AS segments, @segment_table.@loyalty_id AS loyalty_id FROM @segment_table GROUP BY segments, loyalty_id ) SELECT SUM(txns.total_sales), customer_segmentation.segments AS segments, FROM txns JOIN customer_segmentation ON txns.loyalty_id = customer_segmentation.loyalty_id GROUP BY segments HAVING COUNT(DISTINCT txns.loyalty_id) >= @transaction_table.@loyalty_id_AGG_THRESHOLD AND COUNT(DISTINCT customer_segmentation.loyalty_id) >= @segment_table.@loyalty_id_AGG_THRESHOLD ;
Analytical Functions
When creating an analytical rule for a dataset, data owners can specify the following aggregate SQL functions that can be run against the dataset for certain fields:
AVG: Calculates the average value of a numeric column
COUNT: Returns the total number of rows matching specified criteria
COUNT DISTINCT: Returns the number of unique values in a specified column
SUM: Calculates the total sum of values in a column
SUM DISTINCT: Calculates the sum of distinct values in a specified column
STDDEV: Returns the biased standard deviation (division by n) of a set of numbers
For example, a dataset owner could create a dataset analysis rule that only allows a query to run if Count Distinct is applied to the specified field. In that case, your query must use Count Distinct on the specified field at least once. Otherwise, the query cannot be run. This is an added privacy protection policy that many data owners put in place to limit the risk of leaking privacy for individuals whose data is included in the dataset.
If the dataset owner limits the functions you can use, you will receive an error if these functions are not applied to the specified field when generating aggregates. The failure notice will indicate the needed query modifications. To avoid such errors, communicate with the dataset owner to know what is allowed.
For information about dataset analysis rules, see "Definition of Analytical Rules".
Report Configuration
Updating a Query Erases the Previous Report Runs
When you update and save a query, the previous runs will disappear. As a best practice, if you would like to keep earlier runs of the question, you can clone the query. If question versioning is enabled for your organization, prior runs are retained. For information, see "View Question History and Switch Versions".
Questions can be updated only when the status is "stage". Once published, questions cannot be edited. For every update, the stage versions will change from Stage v1 to Stage v2, Stage 3, and so on. Clone is the only available option once a question's status is "published".
Changing Components in Question Builder or Report Configuration
If you change the chart type or anything in the existing charts on the Report Configuration page, the dataset does not need to be reconnected and approved.
Similarly, if you change any component in the Question Configuration window other than the SQL itself or the Parameters, the datasets do not need to be reconfigured.
Report Filters
When you add a filter to a dimension on the Report Configuration page, after selecting either Single Select or Multi Select, you cannot unselect the option. If you enable filtering, you must select a Filter Type. To remove the filter, deselect the Filter toggle.
If you have a function such as distinct count or average, and your filter is at a lower level of granularity than your measure, your calculations may not appear or work correctly.
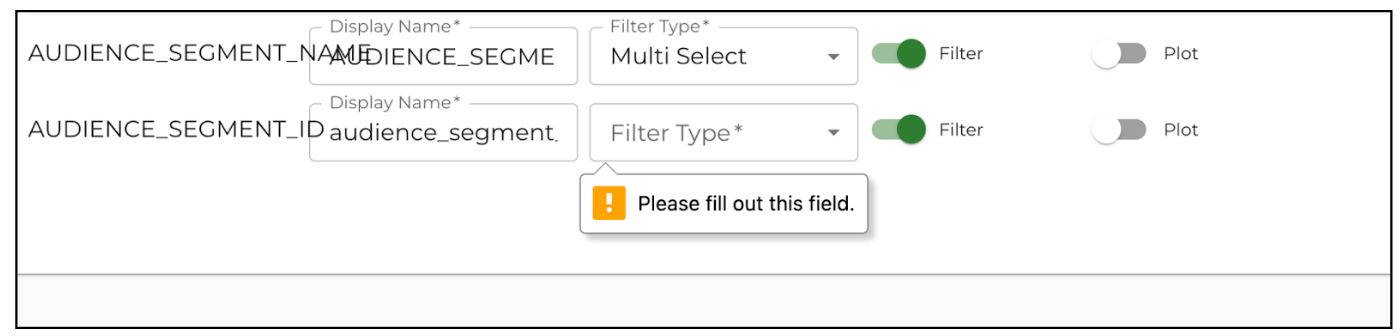 |
Selecting the Y-Axis Position When Configuring Reports
Once the y-axis position is selected, you cannot unselect the value in that list. This will be updated in a future release so that the y-axis position can be unselected.
Question and Query FAQs
See the FAQs below for common questions about Question Builder and Query Builder.
What can I do to improve the performance of my question runs?
Perform data validation in your own environment before connecting your data source to LiveRamp Clean Room. The key areas to consider include making sure that you’re seeing the expected row counts and fill rates for key fields.
The fields listed in LiveRamp's sample schemas can be used to prepare your data for your clean room collaboration use cases. Pay close attention to column names, data types, any required hashing for PII, and so on. Having the proper file formatting in place will make the remainder of your setup much more seamless. Validating it with QA queries in your own environment can reduce costs and save time once you've connected your data to LiveRamp.
Enable partitioning for date columns and key string columns for the datasets assigned to the question, and use partitioning so that only the relevant data is used during execution, not the entire dataset. Data partitioning significantly enhances query performance, reduces data egress, and thus optimizes cost. For information, see "Partition a Dataset in LiveRamp Clean Rooms".
Optimize your queries based on the cloud environment of your clean room type.
Different clean room types use different execution engines, which can impact the performance of question runs. Your Clean Room partners' chosen cloud platform and region also impact the performance of your shared question runs. If you and your partner use the same clean room type, your query will make use of the same SQL engine. While LiveRamp Clean Room is designed to be cloud-agnostic and enable connections to data stored in major cloud providers, the underlying cloud platforms and regions of you and your partners can affect the collaboration and data processing.
What SQL engine should I optimize for?
The SQL engine you should optimize for depends on the specific type of clean room you are using, because different clean room types may support different SQL dialects:
Hybrid and Hybrid Confidential Computing (HCC) clean rooms use Apache Spark SQL because of its support for distributed processing of large datasets. For information, see "Clean Compute on Apache Spark".
Google BigQuery clean rooms use GoogleSQL.
Snowflake clean rooms support standard SQL.
What is LiveRamp's default warehouse size for a question run?
Question Builder's "Advanced Question Settings" include various options for the "Processing capacity needed to run the question". If a question is taking 8 hours to execute or longer, we recommend bumping up the warehouse size.
The available warehouse sizes may be used to select the level of compute required to process your question successfully.
Warehouse Size | When to use |
Default | Default processing capacity is appropriate for the vast majority of queries and datasets. |
Medium | Medium capacity is only required for Questions that are not satisfied by the default setting or for complex queries. |
Large | Large capacity is only required for Questions that are not satisfied by the default setting / exceptionally complex queries and large record counts (1+ billion). |
Extra Large | Extra large capacity is only required for Questions that are not satisfied by the Large setting / exceptionally complex queries and very large record counts (10+ billion). |
2X Large | Intended for extremely complex questions and very large datasets. Use only when Extra Large capacity is insufficient. |
3X Large | Designed for exceptionally high-complexity questions and massive-scale datasets. Requires pre-approval from LiveRamp due to significant resource consumption. |
Why are queries that work in my cloud data warehouse failing in LiveRamp Clean Rooms?
LiveRamp's Hybrid and Hybrid Confidential Compute (HCC) clean rooms use Apache Spark as the underlying engine for executing queries. This leverages distributed computing, which does not auto-scale (and increase cost) to meet the demands of a query. Cloud data warehouses use centralized computing, which is set up to provide greater resources (and increase cost) as the query requires more compute consumption.
Spark is designed for the distributed processing of large datasets, where each query execution is allocated a fixed amount of compute resources. LiveRamp is continually optimizing how these resources are allocated, but due to the fixed nature of each execution job, you may need to test and learn to determine which warehouse size is appropriate for your question. Optimizing queries for Spark involves considering how data is partitioned and processed across nodes. Inefficient queries in this distributed environment can lead to performance bottlenecks, high memory consumption, and potential failures.
Ways to mitigate this risk are to:
Leverage data connection partitioning to ensure only relevant data is processed during query execution
Optimize your code for Spark SQL execution. Not sure how to optimize for this query engine? See LiveRamp's AI SQL Optimization helper.
Leverage the CACHE TABLE function for storing CTEs for repeated use.
What could be leading to memory issues with clean rooms, such as functions failing after 3 hours?
Failures after a long duration, such as 3 hours, are often linked to memory issues that arise during question runs due to how the query is structured. It is not likely caused by functions alone but also by other aspects of the query, such as cross-joins on large datasets or multiple common table expressions (CTEs) reused throughout the query. Failures can also occur for a variety of other reasons, such as within custom Python code, insufficient processing capacity for the warehouse size, transient interruptions, or timeouts.
If troubleshooting steps, such as query optimization and adjusting warehouse size, do not resolve the issue, contact your LiveRamp representative to explore additional options.
Why are my runs queuing for so long?
Long queuing times for question runs can be related to the performance and resource availability within the Clean Room execution environment. If many complex or large queries are submitted simultaneously, there might be insufficient compute resources immediately available, leading to a queue. Problems with the data itself (such as missing data or problematic formatting) could delay the start of a question run if the system encounters problems accessing the necessary data from its source connections. Queueing is not a sign of issues within the system.
What is a Data Plane?
The "data plane" refers to the physical or logical environment where queries are executed and data is processed. It operates within your chosen cloud environment and within a private virtual network in a specific region to ensure data remains localized and secure. This also minimizes data movement and egress costs.
Multiple data planes can participate in question runs, including multiple partners' datasets. LiveRamp Clean Room is built on a multi-plane architecture, with a single control plane coordinating operations across multiple data planes. This design enables scalability and multi-cloud compatibility for secure data collaboration across a global footprint, including the U.S., EU, APAC, and LATAM regions. Each data plane is fully isolated, ensuring secure collaboration and processing data locally to comply with data sovereignty regulations and minimize latency.
How can I resolve a failed question run due to a dataset issue?
If you receive an error message that includes something similar to "Error Message: Failed to read data for dataset=<dataset_name>_pqt", this is likely due to a change at your source data location, such as a deleted source file or a change in permissions.
After a data connection is first created, the Question Run process does not check whether a file still exists or if the data are correct. So, if somebody changes or deletes that file at the source, the question run may fail at a later time.
Recommendations include:
Use consistent field types for the same field within all files and data.
Recast any fields that are inconsistent as "STRING".
Before adding files with recent updates, verify that they use the same format as the reference schema that was previously sent.