Measurement Enablement Workflow
When you send LiveRamp a file to process via our Measurement Enablement workflow, we transform the input identifiers (such as PII, cookies, mobile device IDs, and CIDs) into their associated RampIDs and return the file to the location you specify. Unlike files that go through our Activation workflow, LiveRamp does not ingest any identifiers (other than for the purpose of transformation into RampIDs) or segment data and does not create segments in a Measurement Enablement workflow. For this reason, you can think of the Measurement Enablement workflow as "file in, file out".
When you send LiveRamp a file to process via our Measurement Enablement workflow, we transform the input identifiers (such as PII, cookies, mobile device IDs, and CIDs) into their associated RampIDs and return the file to the location you specify. Unlike files that go through our Activation workflow, LiveRamp does not ingest any identifiers (other than for the purpose of transformation into RampIDs) or segment data and does not create segments in a Measurement Enablement workflow. For this reason, you can think of the Measurement Enablement workflow as "file in, file out".
Note
Measurement Enablement was formerly known as "File-Based Recognition".
Any PII is removed before files are returned to reduce the risk of re-identification.
Depending on the data you’re sending, to meet our privacy requirements and to reduce the risk of re-identification, some fields might be required to be hashed in order to pass them through. For more information, see the “Specifying the Hashing Mechanism” section below.
The Measurement Enablement workflow can also be used to translate RampIDs. For more information, see "Transcode RampIDs Using a Measurement Enablement Workflow".
Depending on your workflow, you can choose to configure the files to include one or all RampIDs and to either include or remove any rows that do not match to a RampID. See the sections below for more information.
You can view the recognition rate (the percentage of rows from your file we matched to) in the Connect UI (see the "View Measurement Enablement File Info" section below). The recognition rate for a file is calculated by dividing the number of matched rows by the total number of rows.
Once your file contains RampIDs, you can then tie the original dataset to any other source you have linked to RampID. General use cases for this workflow include measurement, targeting, exposure, conversion, and more.
Tip
Customers considering using a Measurement Enablement workflow for measurement might be interested in the Measurement courses in the LiveRamp University section of LiveRamp Community.
To start utilizing a Measurement Enablement workflow, contact your LiveRamp representative.
Note
When you first use a Measurement Enablement workflow, the LiveRamp Implementation team will work with you to set everything up. If you need to add an additional data feed for a new set of files after your initial implementation, follow the instructions in "Set Up a New Measurement Enablement Data Feed."
Measurement Enablement Workflow Example
Let’s say you send us a file that contains email addresses and segment data for a Measurement Enablement workflow.
 |
We perform automated privacy checks, match each line to a corresponding RampID, remove the email address field and randomize the row order.
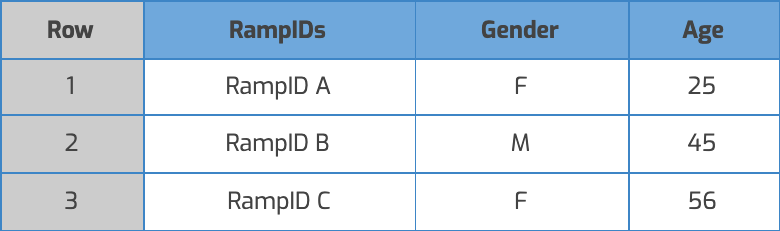 |
Options for Measurement Enablement Output Files
See the sections below for some of the available options for your Measurement Enablement output files.
RampID Options for Measurement Enablement Output Files
There are two output options available for Measurement Enablement files:
One RampID per record
All available RampIDs per record
Note
The output option you choose is applied at the LiveRamp audience level, so that all files going through a given audience will have the same type of output (one RampID or all RampIDs).
In many situations, receiving all available RampIDs is preferable. However, there are some situations (like attribution use cases, where accuracy and precision are the biggest concerns) where you might prefer to receive one RampID per record.
For customers who choose to receive one RampID per record, when there are multiple maintained RampIDs associated with the record, one is selected at random and used consistently.
If your use case emphasizes reach and frequency, you might prefer to receive all available RampIDs for each record. With this option, LiveRamp generates a grouping indicator for each input row and adds that to each row in the output file that contains an associated RampID (see “Receiving All RampIDs Per Record” for more information).
In most workflows, it's best to receive all RampIDs per record, to make sure your data can overlap with other data sets at the highest rate possible.
For more information on the types of RampIDs you might receive, see the sections below.
RampID Versions You Might Receive in Files
Whether you choose to receive one or all RampIDs per record, there are two versions of RampIDs you might receive: maintained RampIDs and derived RampIDs.
Maintained RampIDs
If we have a maintained record for the input data in our Identity Graph, we'll return a maintained RampID. A maintained RampID represents a person that LiveRamp can fully recognize. Multiple devices can usually be associated with a given maintained RampID. Maintained RampIDs are 49 characters long and start with "XY."
Derived RampIDs
If we do not yet have a maintained record for the input data in our Identity Graph, we'll generate derived RampIDs for each PII touchpoint (name and postal address, email address, phone number) for that input record. In addition, even for records where we have a maintained RampID there might be certain PII touchpoints that we haven’t yet confidently tied to that record, so we’ll generate derived RampIDs for those touchpoints as well.
Why Records Might Have Multiple RampIDs
In an ideal marketing world, LiveRamp would always have all PII touchpoints merged into a single individual. In reality, LiveRamp often manages multiple RampIDs for an individual.
This is because people are dynamic: they move houses, change jobs, switch phones, share computers, and upgrade their tech. In the U.S., in 2018 alone, there were 36 M residential moves, 4 M births, 2.2 M marriages, and almost 800 K divorces. Each of these events might create a new PII touchpoint. When we observe a new piece of PII, we create a RampID for that touchpoint.
Over time, each of these events builds a more complete picture of that person’s identity. But until we are able to confidently recognize and prove that these new PII touchpoints are tied to that one individual, we might associate multiple RampIDs with that individual’s data. Once we have a high degree of confidence that the new touchpoints are tied to that individual, we merge those RampIDs into a single maintained RampID.
Thanks to our massive online and offline footprint, we are able to successfully do this more accurately and faster than any alternative.
Multiple RampID Example
For example, say you’re targeting men in Boulder, CO with an email campaign. Email addresses for Bill Jenkins, Billy Jenkins, and William Jenkins appear separately in your targeting file.
Within our graph, each email address has its own RampID (example: XY123, XY456, Xi789). As we observe some common linkages across the three RampIDs (e.g., name and postal address, phone), over time, LiveRamp will learn that Bill, Billy, and William are the same person.
Receiving One RampID Per Record
In some cases, like attribution, where accuracy and precision are the biggest concerns, it might be preferable to choose to receive one RampID per record.
For this option, LiveRamp auto-selects one consistent RampID per individual from our Identity Graph. When available, the maintained RampID is selected.
When there are multiple maintained RampIDs associated with the record, one is selected at random and used consistently.
If there are no maintained RampIDs associated with the record, the derived RampID is selected. When no maintained RampID is available and there are multiple derived RampIDs associated with the record, we select one of them in a consistent and repeatable way.
Receiving All RampIDs Per Record
Having multiple RampIDs per record creates a more accurate view of the digital world and the consumer. This is because devices can be shared, and many people have multiple email addresses, home addresses, and workplace addresses. Today, clients need to link multiple data sets across the offline and online worlds, and receiving multiple RampIDs increases overlap rates across data sets.
Reach is a critical marketing metric - brands, agencies, publishers, and platforms need to be able to measure and prove reach delivery. Multiple RampIDs help clients meet their reach and frequency measurement requirements without a major degradation in accuracy.
Note
Work with your LiveRamp technical support team to ensure smooth delivery of multiple RampID files.
Discuss pricing implications with your LiveRamp Account Director.
Choosing a Grouping Indicator for Multiple RampID Files
Once we match your records to all the RampIDs we associate with each particular record in your file, we create one row per associated RampID and randomize the row order. To enable you or your measurement partner to tie together all the RampIDs associated with each input record, you need a way to group those associated rows.
Our preferred method to accomplish this is through a LiveRamp grouping indicator that we generate and add to the file. The LiveRamp grouping indicator is a hashed number that corresponds to an input row. For privacy reasons, it cannot be tied back to the actual input row number, but it allows you or your measurement partner to be able to group the RampIDs by input row. Here’s an example of what the output file would look like when using a LiveRamp grouping indicator.
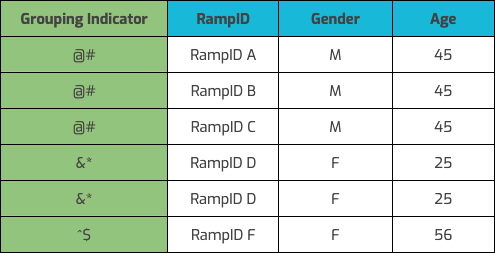
Note
It is not recommended, but if you prefer, you can also provide your own unique input column (for instance a client ID or transaction ID) in the input file, which we will use as a grouping indicator and then hash before returning. Talk to your LiveRamp representative if you want to provide your own grouping indicator.
Excluding Unmatched Rows
By default, the Measurement Enablement output file will include all input rows, including those rows that did not match to a RampID. If desired, you can specify that unmatched rows be excluded from your output files.
You might want to exclude unmatched rows for one of the following reasons:
You don't get use out of unmatched records
You want to reduce delivery volume
You want to deliver data to an API and remove unnecessary traffic
Note
Excluding unmatched records from the output file will not have an impact on Measurement Enablement billing as that is based on the number of input rows.
When you set up a new Measurement Enablement feed, you can specify that you want unmatched rows excluded. To exclude unmatched rows from an existing workflow, create a support case.
Specifying the Hashing Mechanism
Your workflow might make it necessary that some of the columns in your file are MD5-hashed before we return them. You can also specify the hashing mechanism from one of the following options:
Use the universal salt: This is ideal for existing workflows that are already using the hashing functionality. This is the default hash setting.
Note
We will not share the universal salt externally.
Configure a custom salt: To make your data more secure, you can select your own salt value so that the hashing mechanism is unique to your workflow. This also allows you to recreate the hashing in your own environments.
Configure no salt: This applies a standard MD5 hash with no salt.
Warning
Customers receiving hashed columns are prohibited from maintaining a mapping of unhashed data to hashed data output from Measurement Enablement. Customers are also prohibited from using Measurement Enablement to merge PII with RampIDs, re-identify online data (such as online browsing data, exposure logs, cookies, mobile IDs, or RampIDs), and/or map pseudonymous data to offline identities (such as PII or offline custom identifiers).
Measurement Enablement File Delivery Options
After 1-3 business days, the output file will be available for pickup. Typically, LiveRamp drops the output files into an SFTP we set up for you. We do have other options available for delivery, including AWS S3, your operated SFTP, GCS, and Microsoft Azure Blobs. See “Set Up LiveRamp File Deliveries” for more information. Work with your LiveRamp representative to set up your preferred delivery location.
Now that your file contains RampIDs, you can now tie the original dataset to any other source you have linked to RampID. General use cases for this workflow include measurement, targeting, exposure, conversion, and more.
Send your Measurement Enablement Data to LiveRamp
Create Files
Make sure to properly format your files so that we can process them quickly. It’s especially important to keep the following key guidelines in mind:
Ensure your file contains identifiers that LiveRamp can recognize. A list of these identifiers can be found in our content on known identifiers and pseudonymous identifiers.
Once you decide on a format for your initial files, the column headers for the identifier columns that we use for matching must stay exactly consistent in subsequent files.
If you’ll be sending files with different identifier types (for example, if you’ll be sending both files with PII and files with mobile device IDs), let your LiveRamp Implementation Manager know. Otherwise, we will assume that all files contain the same type of identifiers.
LiveRamp's file limits.
For files containing PII, do not include unique values (a value that appears in only one row) in a segment data column. If a unique segment value is found in a row in a PII file, LiveRamp will not be able to provide the unique value next to RampIDs to maintain the pseudonymousness of the RampIDs. In certain cases where unique values must be included in the output file, work with your LiveRamp representative to obtain a privacy approval from our team.
Note
New Customers: Let your Implementation Manager know how many distinct file formats you’ll be sending (formats with different column headers and different identifier data fields).
Send Files to LiveRamp
Once you’ve decided on your distinct file format, you can send your data to us in a number of ways. In general, we recommend that you either upload your data via SFTP or have us retrieve it from an AWS S3 bucket.
Note
New Customers: Let your Implementation Manager know which file delivery method you’d like to use.
After you've uploaded your file or files, you'll need to wait 1-3 days for us to process the data before the output file will be available for pickup.
Note
If you don't see the file after 3 days, use the Troubleshoot File Delivery / Output for Existing Measurement Enablement Workflow quick case to create a support case.
View Measurement Enablement File Info
For each Measurement Enablement file we process, you can view the following info on the Files page in Connect:

The date the file was received
The status of the file
The number of rows in the input file
The recognition rate (the percentage of valid rows in the file that were matched to a maintained RampID)
To navigate to the Files page, select Data In → Files in the navigation menu and then select your Measurement Enablement audience from the Audience dropdown.
You can also open a details panel that displays additional information. See "Check the Status of an Uploaded File" for more information.
Note
Since LiveRamp does not store any segment data for this workflow, there is no data manipulation within the Connect UI.
Tying Multiple Files Together
In order to tie disparate datasets together, use the RampIDs column.
Note
If you opted for the LiveRamp-provided grouping indicator column, we cannot guarantee that the order of the grouping indicator will be the same across different files even if the input identifier is the same. This is because we randomly shuffle the output row order for privacy reasons. Also, to comply with privacy and data ethics requirements, a different hash will be used for the grouping indicators in each file.
Set Up a New Measurement Enablement Data Feed
A "data feed" is a set of files you send through a Measurement Enablement workflow. If you want to set up an additional data feed through a Measurement Enablement workflow after your initial implementation, follow the steps below to create a case in the LiveRamp Community portal with the required information.
A "data feed" is a set of files you send through a Measurement Enablement workflow. If you want to set up an additional data feed through a Measurement Enablement workflow after your initial implementation, follow the steps below to create a case in the LiveRamp Community portal with the required information.
Using the info you provide, the Technical Operations Manager working on your ticket will determine if the new data feed requires a new audience.
Use the Set Up a New Measurement Enablement Workflow quick case to create a support case that includes the following information:
Identifiers: Specify the type of identifiers your data uses (select one type per feed):
Offline Identifiers: Email, Name and Postal, Phone
Online Identifiers: Cookies, Mobile IDs, IP Addresses, Custom Platform IDs from <insert platform>"
RampIDs
Output option: Specify the type of output you would like for your Measurement Enablement file: Multiple RampID or Single RampID (see "RampID Options for Measurement Enablement Output Files" for more information).
Grouping indicator: For workflows that use the Multiple RampID option, specify whether you want us to include a grouping indicator or whether you want to provide your own unique input column to use as a grouping indicator.
Column configurations: Specify whether you want us to transform any column data. Options include MD5 hashing, salting with one of the available methods, encrypting, or dropping or truncating column values.
Unmatched rows option: Specify whether you want us to include rows that did not match to a RampID (the default) or exclude those unmatched rows.
Provider: Specify the entity that will be providing the files to LiveRamp for this workflow (Your company, your partner, etc.).
Upload method: Specify which method the provider will use to send us files for the new feed (see "Getting Your Data Into LiveRamp" for a full list of LiveRamp's upload options).
Note
Files for Measurement Enablement workflows cannot be uploaded via Connect.
Upload path: Specify the full path on the server that the files are going to be uploaded to (i.e., "s3://liveramp/imports/File Based Recognition files" or "/uploads/new_file_based_recognition_data_feed/").
File name: Specify the expected file name(s) for the first file.
Recipient: Specify the entity that LiveRamp should send the Measurement Enablement output files to.
Delivery method: Specify which delivery method LiveRamp should use for sending the output files to the recipient (see "Set Up LiveRamp File Deliveries" for a list of LiveRamp's delivery options).
Delivery path: Specify the full path on the server that the files will be delivered to (i.e., "s3://liveramp/imports/Measurement Enablementfiles" or "/uploads/Measurement Enablementfiles/").
Notification email addresses: Specify the email address(es) you would like us to use for the email notifications that Measurement Enablement files have been delivered.
CC list: Specify the email addresses for any additional people you would like to have CC’d on this support ticket.
Additional info: Include any additional info that will help us understand the context of your request.
See the description below for an example of what a populated description might look like:
1. Identifiers: Offline - Email Addresses
2. Output option: Multiple RampID
3. Grouping indicator: Use LiveRamp grouping indicator
4. Column configurations:
5. Unmatched rows option: Exclude unmatched rows
6. Provider: Company A
7. Upload method: LiveRamp SFTP
8. Upload path: /uploads/Measurement Enablementfiles/
9. File name: /uploads/Measurement Enablementfiles/firstMeasurement Enablementfile.csv
10. Recipient: Company B
11. Delivery method: S3 Bucket
12. Delivery path: s3://liveramp/imports/Measurement EnablementFiles
13. Notification email addresses: Example@example.com, Measurement Enablement@example.com, Lead@example.com
14. CC list: No thanks!
15. Additional info: We are trying to have this setup by Monday (5 days away) Please let me know if you need any additional info to get this new started. Thank you for your help!Once we've aligned with you on the required information, your new data feed will be set up in 3-5 days. After set up, new files for this feed will be processed in 1-3 days.
FAQs
Due to the complexity of the ecosystem and the multiplicity of touchpoints for a single person, it is often hard to resolve all person-level and device-level touchpoints to a single RampID with certainty. Therefore, the Identity Graph contains more than one RampID for a person until such time as we can consolidate with a high degree of confidence.
When we observe a new piece of PII, we create a RampID for that touchpoint.
LiveRamp’s foundational system for resolving offline Identities, AbiliTec, performs the role of determining which pieces of personally identifiable information (PII) represent a “person.” Thus there are times when a client's CRM data considers multiple pieces of PII to be the same when AbiliTec does not yet see sufficient evidence to merge them. This will allow us to maintain our verification standards, while delivering higher match rates within a client's CRM data, maximizing reach.
In addition, our Online Identity Graph might contain several derived RampIDs for a given email touchpoint because we typically have a different derived RampID for each of the three email address hash types in our graph.
One offline identifier (i.e., an email address) can be tied to more than one RampID because email addresses can be shared and therefore could be associated with several names and postal addresses (NAP). For instance, a family email address could be associated with the NAP of the parents and the NAP of the son who moved out to go to college.
One online identifier (i.e., a cookie) can be tied to more than one RampID because we have shared devices. For instance, if a computer is shared by multiple people and they use different emails and PII but might still keep sessions open, cookies can be associated with more than one piece of an identifier and therefore more than one RampID.
People are dynamic: They move houses, they change jobs, they switch phones, they share computers, they upgrade their tech, and they are exposed to marketing on the move across multiple channels.
The marketing ecosystem is dynamic: The multiplicity of marketing touchpoints - creatives/ impressions/channels/media - across multiple devices for every single person is complicated to disentangle and connect back to individuals.
It takes time to build a consolidated, complete view of an individual as LiveRamp/AbiliTec starts to recognize and prove the different PII touchpoints are accurately tied to one person. This is not instantaneous.
Merging (reducing the number of RampID s per individual) happens only when there is a high degree of confidence that separate identifiers are tied to one person.
When AbiliTec sees the necessary validation to confidently tie new information to an existing offline profile, this information is updated and merged to the existing individual’s LiveRamp RampID .
Receive all RampIDs associated with a given touchpoint, such as a unique creative, message, email, call center contact, or sales transaction.
Increased overlap rates across data sets
Better visibility across the customer journey
Alignment with Activation process, which already outputs multiple RampIDs
Greater consistency across LiveRamp use cases
...while maintaining confidence and accuracy within each RampID
If you're seeing a low recognition rate for you file, there are a number of possible reasons:
The input identifiers are poorly formatted. Examples of this include zip codes with 6 digits or email addresses with no "@" sign. For CIDs, this might be sending a 20-character CID value when LiveRamp is expecting a 16-character value.
The input identifiers are invalid because they contain entries such as "null", "n/a", "0", or ",".
There's a low overlap between your source data pool and LiveRamp's identity space (if you have an identity space that we don't have data for).
There was a change in identity space on your side or the LiveRamp side (this is more likely if there was a sudden drop in recognition rates). For example, this change might occur if you change the way you refresh your identity.
Many LiveRamp customers (as well as many AdTech companies in general) have been seeing a decrease in their MAID (mobile device ID) recognition rates. While LiveRamp continuously works to improve the MAID data in our Identity Graph, we think that this decrease is mostly due to a number of industry changes, including:
Apple’s Application Tracking Transparency framework
Greater consumer access to managing the mobile advertising ID on their devices
New regulations and privacy laws
For more information on each of these issues, see the sections below.
These changes, along with the normal consumer behavior of upgrading devices, mean that we are observing the average lifetime of MAIDs decrease. We expect that there will continue to be more consumer choice in consenting to collect these signals.
For LiveRamp’s match data sources (that we use to build our MAID graph), this means that we have to cast a wider net as we need more data to get the same amount of valid linkages that we had before these frameworks were put in place. We also see a decrease in the longevity of MAIDs as once valid MAIDs are become invalidated through these frameworks. We have been updating our sourcing strategy to counteract these changes.
We also continue to recommend ATS (Authenticated Traffic Solution) as a more forward-looking alternative. For more information, see "Authenticated Traffic Solution".
Apple’s Application Tracking Transparency Framework
Much of this change started when Apple implemented Application Tracking Transparency (ATT), in which a consumer must consent to the tracking of personal information for each application. For many application owners, this resulted in a drastic decrease in the ability to collect and tie a MAID to other pieces of personal information of the consumer (such as email).
The impact doesn’t seem to be as significant if the application is well trusted and respected. In those cases, consumers seem to be willing to opt-in to targeted advertising at a higher rate than an application that is not as well known. However, even for trusted applications the ability to collect this data is still well below what we were observing before ATT was released.
Greater Consumer Access to Managing Mobile Advertising IDs
In addition to ATT’s per-application opt-in, consumers now have much more access to their advertising ID on phones than before. In Android 12 and beyond (which does not employ the same framework as Apple on app opt-in), Google allows users to delete their Advertising ID more easily through their privacy settings, whereas, in the past, this was not easy to do.
New Regulations and Privacy Laws
State regulations and privacy laws are also contributing to the decrease. In Virginia for instance, precise geolocation is now classified as “sensitive data”, which requires special obligations to collect and sell for applications. All of this puts pressure on application owners who provide this type of data.
In some cases, like attribution, it makes sense to choose a single ID. For instance, Google (through the Google Store Transaction product) requires a single ID to be returned to them.
Another reason is that some clients use RampIDs as database keys and do not necessarily need identity resolution.
Also migration to multiple RampIDs may be difficult or impossible for some clients to switch to, so we are maintaining both options.
When you run files through Measurement Enablement and receive one RampID per record, you received a file with the same number of rows as the input rows, and one RampID per row. If you choose the option to have all RampIDs returned, you will receive an output file that still has one RampID per row, but where rows are duplicated if more than one RampID was found. You can optionally add a column to indicate how RampIDs should be grouped together. This grouping is based on which row the RampIDs came from. For privacy reasons, you will however not be able to tell which of the input row each grouping of RampIDs corresponds to, as we shuffle the row order.
In order to tie disparate datasets together, use the RampID column.
If you opted for the LiveRamp-provided grouping indicator column, we cannot guarantee that the order of the grouping indicator will be the same across different files even if the input identifier is the same. This is because we randomly shuffle the output row order for privacy reasons.
Also, to comply with privacy requirements and data ethics considerations, a different hash will be used for every file.
Upon completion of LiveRamp processing, the final step of data aggregation, joining RampID s to individuals, will need to be performed.