Working with Jupyter and BigQuery Python Client
The main use of Jupyter and BigQuery Python is to divide a large or complex processing task into a sequence of smaller, independent processing steps that are connected by intermediate tables. Being able to run each step independently and interactively means you can test and refine each step of your code before moving on to the next step.
This approach allows the user to interact with the BigQuery engine from a Python client instead of using the BigQuery web console. It uses the same underlying API as the BigQuery web console does.
This approach adds advanced scripting possibilities on top of BigQuery. It can be useful for modularizing your code (using tables and columns as variables, and generating a lot of tables with some naming convention).
Note
JupyterLab and Jupyter Notebook can be opened from the Analytics Environment virtual machine desktop.
The diagram below shows the ways that the BigQuery web console and Jupyter Notebook and BigQuery Python client interact with the BigQuery jobs engine.
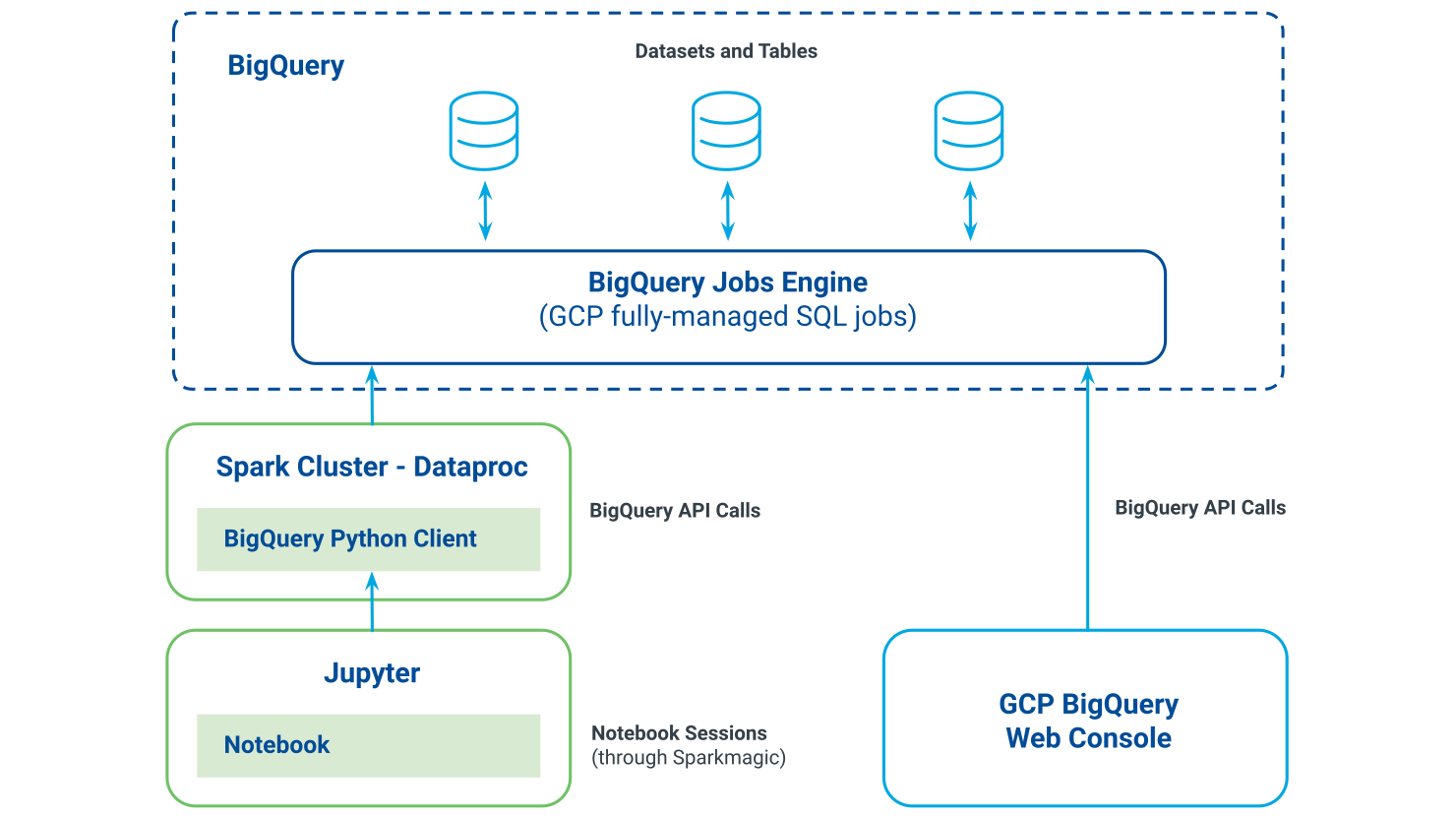
Each sub-task performs two steps:
Building a query
Running and saving the query output as a table
Only the query building part is processed in the cluster.
These applications can also be used for:
Running multi-step (or multi-statement) queries
Building very long queries
Selecting a large number of columns in your query (more than 100)
Modularizing your code (reusable logic)
When dealing with a very large amount of data with the Python client, it is highly recommended to not load these data into the cluster and run end-to-end query/job directly in BigQuery (for example, do not convert data in pandas dataframe).
Sample code for saving query results to a table:
def create_table_as_select(dataset_name, table_name, sqlQuery, param):
try:
#Set named parameters and add to job config
params = bigquery.ScalarQueryParameter('query_param', 'STRING', param)
job_config = bigquery.QueryJobConfig()
job_config.query_parameters = [params]
dataset_ref = bigquery_client.dataset(dataset_name)
table_ref = dataset_ref.table(table_name)
job_config.destination = table_ref
job_config.create_disposition = 'CREATE_IF_NEEDED'
job_config.write_disposition = 'WRITE_APPEND'
job = bigquery_client.query(sqlQuery, job_config=job_config)
job.result()
returnMsg = 'Created table {} .'.format(table_name)
return returnMsg
except Exception as e:
errorStr = 'ERROR (create_table_as_select): ' + str(e)
print(errorStr)
raiseWhen dealing with tables with a lot of columns, having the table metadata, such as column names and data types, helps to build the query programmatically and perform a task such as casting.
Sample code for getting table metadata:
from google.cloud import bigquery
client = bigquery.Client()
bq_project = "your-project-id"
bq_dataset = "your-dataset"
bq_table= "your-table"
query = (
'''SELECT * EXCEPT(is_generated, generation_expression, is_stored, is_updatable)
FROM
`'''+bq_project+'''`.'''+bq_dataset+'''.INFORMATION_SCHEMA.COLUMNS
WHERE
table_name="'''+bq_table+'''"
'''
)
query_job = client.query(query)
# API request - starts the queryfor row in query_job:
# API request - fetches results
# Row values can be accessed by field name or index
for row in query_job:
print(row.name)Loading or extracting data between BigQuery and GCS is very fast with the BigQuery Jobs API (no need to move data into the Dataproc cluster for performing these types of operations).
Sample code for extracting data from BigQuery to GCS:
#Extract data from BigQuery to GCS
from google.cloud import bigquery
client = bigquery.Client()
gcs_path="gs://lranalytics-eu-xxx-yyy-work/tmp/new_tbl/part-*.csv"
dataset_ref = client.dataset("tb_test", project="lranalytics-eu-xxxx")
table_ref = dataset_ref.table("new_tbl")
job_config = bigquery.ExtractJobConfig()
job_config.print_header = False
#Always mind the job/data location
extract_job = client.extract_table(table_ref, gcs_path, job_config=job_config, location="us")Sample code for loading data from GCS to BigQuery:
#Load data from GCS to BigQuery
from google.cloud import bigquery
from google.cloud.bigquery import SchemaField
client = bigquery.Client()
job_config = bigquery.LoadJobConfig()
job_config.write_disposition = bigquery.WriteDisposition.WRITE_TRUNCATE
job_config.source_format = bigquery.SourceFormat.CSV
schem = [
SchemaField('name', 'INTEGER'),
SchemaField('value', 'STRING')
]
job_config.schema = schem
dataset_ref = client.dataset("tb_output_test", project="lranalytics-eu-xxxx")
table_ref = dataset_ref.table("new_tbl_11")
client.load_table_from_uri("gs://lranalytics-eu-xxxx-yyy-work/tmp/new_tbl_out_11/part*", table_ref, job_config=job_config)To save a segment to Customer Profiles, you can use a script to create or replace tables and add the sendtocustomerprofiles and ready labels. The following BigQuery or Python examples can add labels and initiate the Save a Segment to Customer Profiles process. Other scripts might not work as intended.
Example BigQuery script for creating segment tables with labels:
create or replace table `project-id.dataset-name.table-name`
OPTIONS(labels=[("sendtocustomerprofiles","ready")])
as select * from `project-id.dataset-name.table-name-A`Example BigQuery script for creating segment tables with labels:
create table `project-id.dataset-name.table-name`
(
x INT64,
y STRING
)
OPTIONS(
labels=[("sendtocustomerprofiles","ready")]
)Example BigQuery script for updating segment tables with labels:
alter table `project-id.dataset-name.table-name`
SET OPTIONS (labels=[("sendtocustomerprofiles", "ready")]);Example Python script for updating segment tables with labels:
from google.cloud import bigquery
bq_client = bigquery.Client()
table = bq_client.get_table("project-id.dataset-name.table-name")
table.labels['sendtocustomerprofiles'] = 'ready'
bq_client.update_table(table, ['labels'])Split a complex processing task into a sequence of smaller, independent processing steps that are connected by intermediate tables. This allows you to have some checkpoints where you can restart your process in case of issues and will bring more clarity to your code.
Avoid reading a large volume of data locally into your cluster. Instead, use the BigQuery Python client for orchestrating BigQuery Jobs that run entirely in the BigQuery engine. As Python is not distributed, reading a large volume of data would take a long time and eventually crash your cluster. Using Python for building your query and running it on the BigQuery engine would be faster and perform better.
Avoid printing large outputs on your Jupyter Notebook. Jupyter Notebook has some limitations on the number of characters that can be printed on the console (around 1000 characters). That limitation can occur when you dynamically build your SQL queries and want to show it in your notebook. It impacts only Jupyter, not Python itself: you can still manipulate your very long string but without printing it on your Jupyter console.
A BigQuery table column name should not exceed 128 characters. For columns created from a combination of columns, you may assign a short name and maintain a reference table.
When dealing with a very large amount of data, don't use the BigQuery Python client for processing data into your cluster. Use only the BigQuery Python client for building and orchestrating BigQuery jobs with input and output stored in BigQuery. Don't use Pandas or any Python data structure to manipulate data into the cluster