Analytics Environment Resources
In the Analytics Environment, there are two types of data storage resources available:
Cloud data warehouse databases (BigQuery datasets)
Cloud object storage buckets (GCS buckets)
BigQuery Datasets
Your BigQuery instance comes with predefined datasets (within the Resources area on the left) that can be used to store different types of data, depending on your user persona:
Note
In your BigQuery instance, the names for these datasets start with your account name and end with the suffixes shown below (for example, "<organization_name>_wh").
Suffix | Access Type | Description | Data Scientists | Data Analysts |
|---|---|---|---|---|
_ai | Read, write | Holds input and output tables used in machine learning (ML) models (analytics insights) | Yes | No |
_pub | Read, write | Holds tables that need to be published to Tableau (if "< | Yes | No |
_pub_gcs | Read, write | If enabled, holds tables that need to be published to the GCS bucket. Contact your LiveRamp administrator to enable this dataset. | Yes | No |
_pub_rp | Read, write | If enabled, holds tables that need to be published to Tableau. Contact your LiveRamp administrator to enable this dataset. | Yes | No |
_rdm | Read-only | For tenants with retail data, holds sales transaction data (retail data model) | Yes | No |
_rp | Read-only | Holds tables to use for creating Tableau reports | No | Yes |
_sg | Read, write | Holds segment tables to send to Customer Profiles for Data Collaboration or directly to a destination | Yes | No |
_sub | Read-only | Holds permissioned views from a primary tenant to a partner tenant (subtenant) | Yes | No |
_wh | Read-only | Holds warehouse tables that store your ingested data | Yes | No |
_work | Read, write | Holds tables as a workspace for use by your organization (not shared with other tenants) By default, there is no expiration policy for tables in this dataset. | Yes | No |
Customer Profiles Segment Data
The following tables in the _wh (warehouse) dataset store your ingested data:
customer_profiles_segments: Contains the segment data (members) that were sent to Analytics Environment from Customer Profiles for Data Collaboration. Use this table to perform campaign measurements and develop insights.
customer_profiles_segment_reference: Contains metadata from distributed segments that are automatically sent to Analytics Environment, including name, counts, destinations distributed, and timestamps.
customer_profiles_segments table:
Column Name | Data Type | Description |
|---|---|---|
distributed_timestamp | timestamp | The distribution date, which depends on the mode:
For information about these modes, see "Distribute to Analytics Environment." |
segment_name | string | The name of the segment |
test_flag | Boolean | Indicates whether a RampID is in the segment's test group (True) or its control group (False) |
user_id | string | The RampID associated with the record in the segment |
customer_profiles_segment_reference table:
Column name | Data Type | Description |
|---|---|---|
alwayson_enabled | Boolean |
|
append_mode | integer |
|
count | integer | The count of the segment RampIDs |
destination_name | string | The destination name. If there are multiple destinations in the distribution, multiple records are created. |
distributed_timestamp | timestamp | The distribution date |
segment_id | string | The unique ID of the segment |
segment_name | string | The name of the segment |
Destination Tables
If your Analytics Environment tenant has been configured to support delivering simple segment tables directly to a destination platform, the following tables will be available in your _wh (warehouse) dataset in BigQuery.
The following tables in the _wh (warehouse) dataset store data about your destination accounts and distributions:
da_reference: This table includes your allow list of destination accounts that have been implemented in Customer Profiles. For information, see The Destinations Page.
syndicate_destination_result: This table stores the status of any distributions to a destination platform. If it does not yet exist, it will be created once your first distribution directly from Analytics Environment is complete. You can query the data in this table if you want to check the status of your distribution.
da_reference table:
Column Name | Data Type | Description |
|---|---|---|
da_id | integer | The unique ID of the destination account Example: 3557 |
da_name | string | The value of the destination account's "Destination Name" Example: TTD |
syndicate_destination_result table:
Column Name | Data Type | Description |
|---|---|---|
da_id | integer | The unique ID of the destination account Example: 3557 |
da_name | string | The value of the destination account's "Destination Name" Example: TTD |
end_time | timestamp | The end date set for the distribution Example: 2023-12-07 17:31:00 |
start_time | timestamp | The start date set for the distribution Example: 2023-09-07 15:26:21 |
status | string | The status of the distribution (currently, only "SUCCESS" will display) |
Table_Name | string | The name of the simple segment table that was sent to the distribution account Example: cereal_campaign_converter |
GCS Buckets
In addition to BigQuery datasets, data scientists can also use the following GCS buckets for storing data and code:
Note
Effective February 11, 2026, the default expiration policies for new Google Cloud Storage (GCS) buckets in Analytics Environment (AE) are as follows:
GCS “
-coderepo” and “-work” buckets: 365 daysGCS custom buckets: 30 days
For “-coderepo”, “-work”, and custom buckets created prior to this date, LiveRamp administrators will communicate with existing tenants regarding the implementation of the expiration policy as needed.
GCS “
-coderepo” bucket (read, write): Store code artifacts for submitting a non-interactive job to the Analytics Environment Spark cluster. The default expiration policy is 365 days.GCS “
-work” bucket (read, write): Store files processed by the Spark cluster (a sandbox). The default expiration policy is 365 days.Custom GCS buckets (read, write): Your organization might also have custom GCS buckets configured by LiveRamp. The default expiration policy for custom buckets is 30 days. For more information, contact your LiveRamp administrator.
Use Logs Explorer in the Google Cloud Console
Users with the "LSH Data Scientist" persona can use the logs explorer in the Google Cloud console to view log details for their Google Cloud Platform (GCP) resources, including:
BigQuery
Google Cloud Storage (GCS) buckets
Cloud Dataproc Clusters
Note
Currently, you can only view the logs. Some features are not yet available, for example, create metric and create alert.
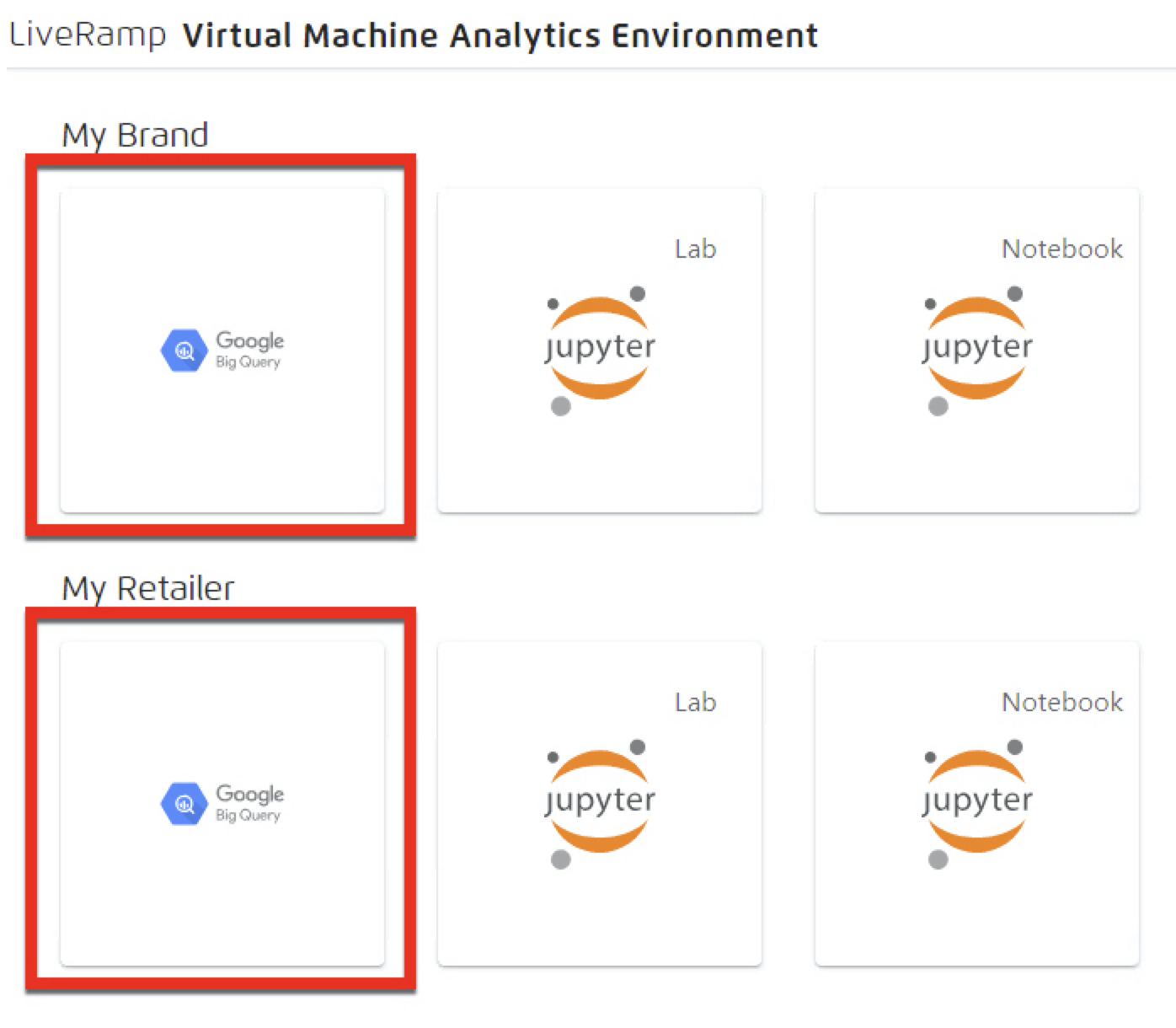
From the Analytics Environment virtual machine desktop landing page, click the Google BigQuery tile.
Tip
If your account has access to more than one tenant, choose the tile for the desired tenant account.
From the BigQuery console, open the Project dropdown list and select the appropriate organization and project.
Search for "logs explorer" and then click .

Tip
Pin this menu for future reference.
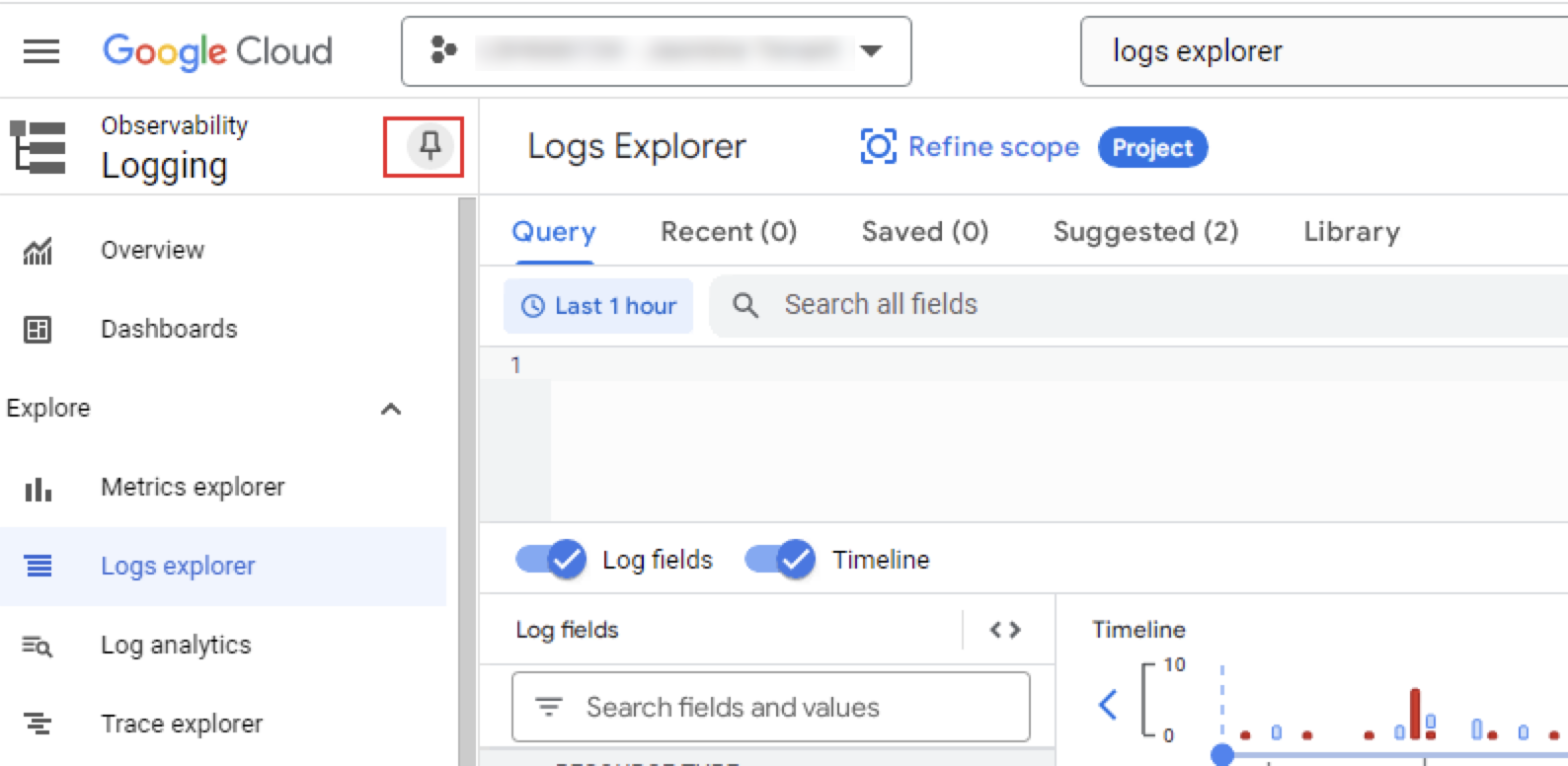
Filter Logs
You can filter the logs by using the Logs Explorer Query tab. For example, you could troubleshoot a failed BigQuery job:
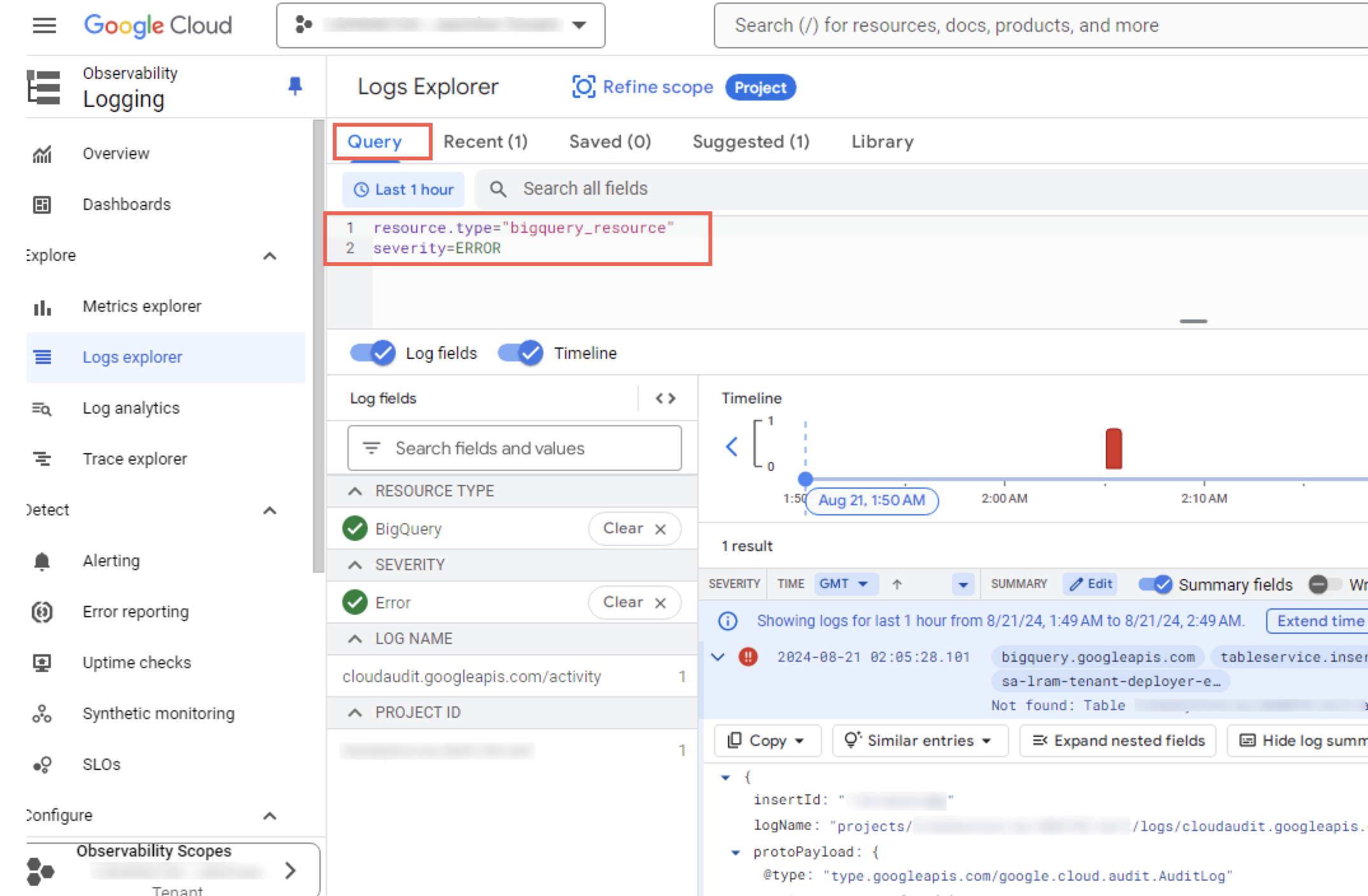
View Dashboard List
You can view the list of log dashboards provided by Google to gain further insights.