View File Stats
File stats provide information on each file you’ve uploaded to LiveRamp, such as number of rows, unique records, and columns in the file. These stats are displayed on the Files page and typically take 1-3 days to populate after file uploading. File stats are calculated during processing based directly on the data in the file.
To navigate to the Files page, select Data In → Files in the navigation menu and then select the desired audience:
The stats displayed in both the table and in the details panel varies depending on whether the audience is an Activation workflow audience or a Measurement Enablement workflow audience. See the sections below for more information.
For additional information on the data displayed on the Files page, see "Check the Status of an Uploaded File".
View Activation File Stats
Activation file stats provide information on each Activation-workflow file you’ve uploaded to LiveRamp, such as number of rows, unique records, and columns in the file.
You can use these stats to evaluate file metadata and can also be used for direct file comparisons. These stats can also help you avoid going over our recommended file limits for Activation workflow files.
Note
If you're seeing unexpectedly low or high match rates, either in Connect or at the destination platform, first be sure to check the information in these articles:
If you still have questions about a match rate that seems unexpectedly low or high at the destination platform, first check with the platform to see if it's an issue on their end. If nothing is found, or if the issue is solely with stats within Connect, use either the High/Low Match Rate Investigation (Activation) quick case or the High/Low Match Rate Investigation (Measurement Enablement) quick case to create a support case to investigate the issue.
The Activation file stats displayed include:
Total Rows: The total number of rows in the file.
Unique Records: The number of unique records in that file, after deduplication. For example, John Doe, the cat lover and pasta eater, is a single record. However, John Doe also appears a few rows down in your file. If we determine that both instances of John Doe are the same person, we’ll merge those two records into one and count that as one unique record.
Note
"unavailable" indicates that your stats are being calculated.
Columns: The number of columns (or fields) in that file, including identifier fields and segment data fields.
Caution
To minimize delays and ensure maximum performance, keep our recommended file limits for Activation workflow files in mind:
Total rows: Minimum of 25 and maximum of 500,000,000 per file (maximum of 100,000,000 for UK data files and 30,000,000 for French data files)
Columns (segment data fields): Maximum 500 per file
View Measurement File Stats
Measurement file stats provide information on each Measurement Enablement workflow file you’ve uploaded to LiveRamp, such as number of rows, the recognition rate, the number of invalid rows, and more.
You can use these stats to evaluate the quality of your data, see how much of your data matches to unique individuals, and to see how much of your data LiveRamp can recognize.
Note
If you still have questions about a recognition rate that seems unexpectedly low or high, use the High/Low Match Rate Investigation (Measurement Enablement) quick case to create a support case to investigate the issue.
Stats Displayed in the Table
The Measurement file stats displayed in the table include:
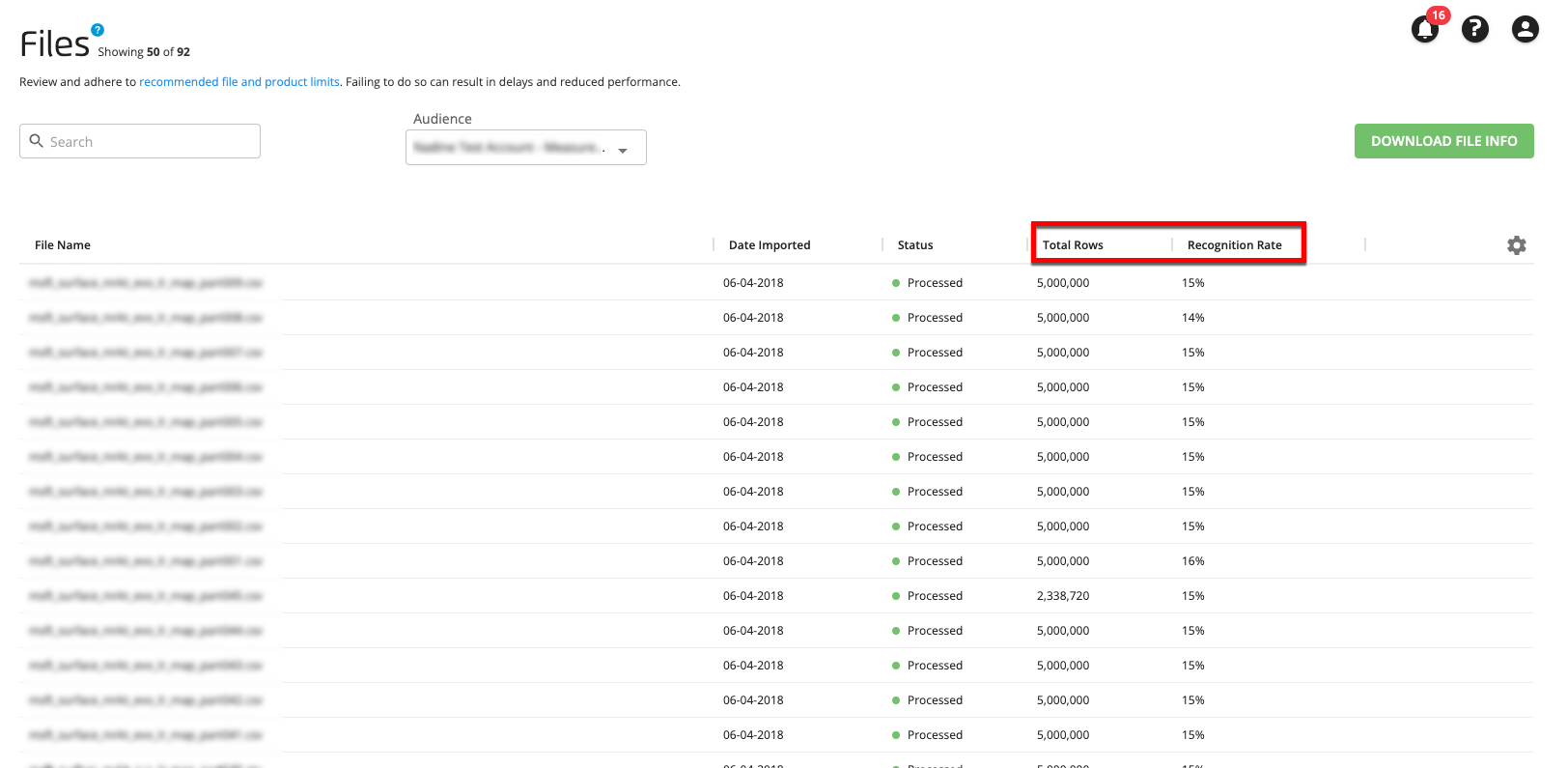
Total Rows: The total number of rows in the file.
Recognition Rate: The percentage of valid rows in the file that were matched to a maintained RampID.
Caution
To minimize delays and ensure maximum performance, keep our recommended file limits for Measurement Enablement workflow files in mind:
Total rows: Minimum of 25 and maximum of 500,000,000 per file (maximum of 100,000,000 for UK data files and 30,000,000 for French data files)
Columns (segment data fields): Maximum 400 per file
Stats Displayed in the Details Panel
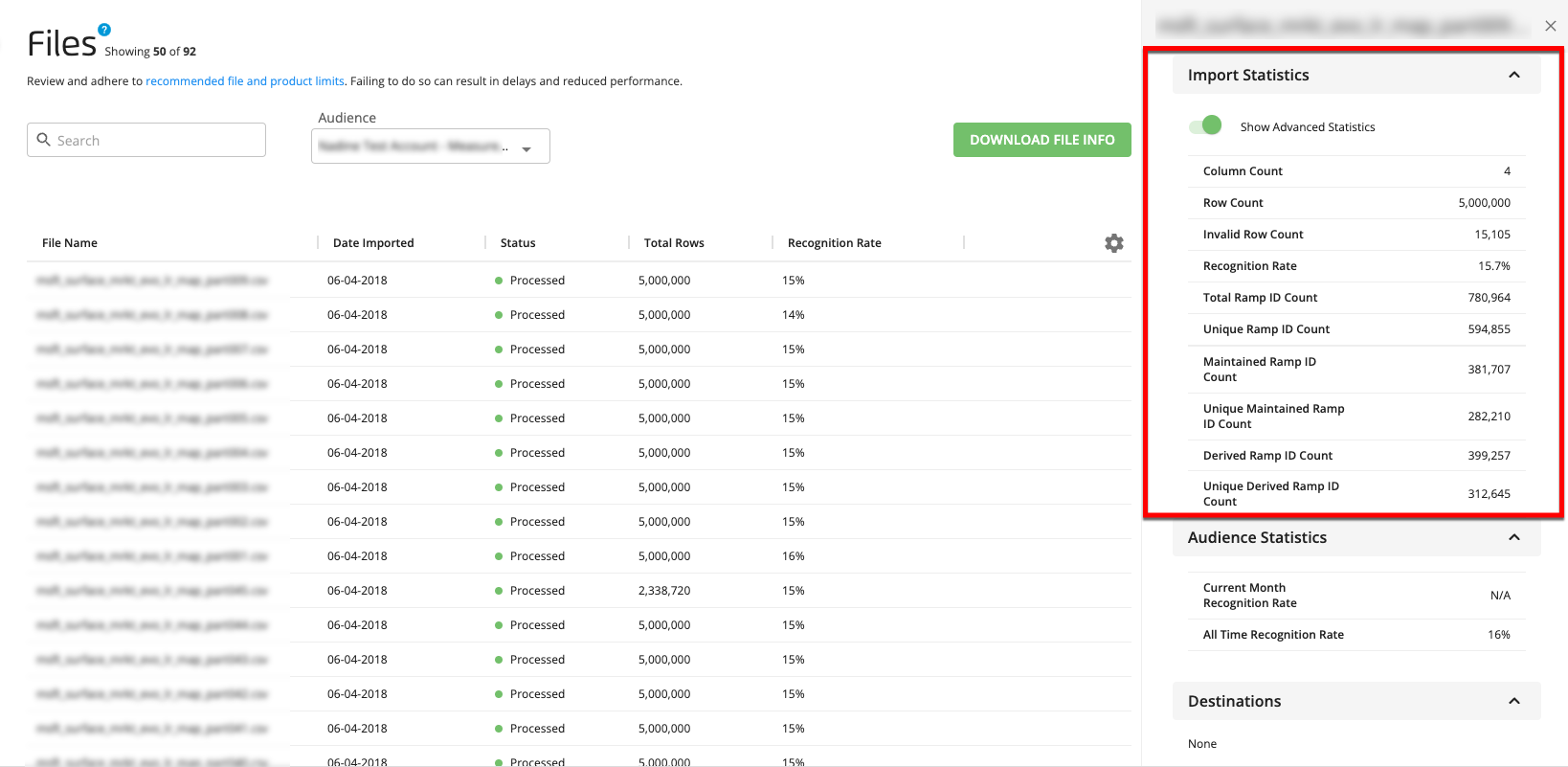
To view additional stats for a file, click on that file's row to open the details panel and display the following stats in the Import Statistics area:
Note
Stats on the recognition rate for Measurement Enablement workflow audiences are also displayed on the Files page, in the details panel. See “Check the Status of an Uploaded File” for more information.
Column count: The number of columns in the file.
Row count: The number of rows in the file.
Invalid row count: The number of rows that contain unmatchable identifier data. For PII files, we check the validity of the identifiers by looking for blanks, bad format, or known invalid email domains, for instance. For files containing devices, we check that the device is not a ‘0’, blank, or a permutation of N/A, nil and null.
Recognition rate: The percentage of valid rows in the file that were matched to a maintained RampID,
Total RampID count: The total number of RampIDs that the rows in the file matched to.
Unique RampID count: The number of unique RampIDs that the rows in the file matched to.
Maintained RampID count: The total number of maintained RampIDs that the rows in the file matched to (displayed when Show Advanced Statistics is toggled on).
Unique maintained RampID count: The number of unique maintained RampIDs that the rows in the file matched to (displayed when Show Advanced Statistics is toggled on).
Derived RampID count: The total number of derived RampIDs that the rows in the file matched to (displayed when Show Advanced Statistics is toggled on).
Unique derived RampID count: The number of unique derived RampIDs that the rows in the file matched to (displayed when Show Advanced Statistics is toggled on).
Measurement File Stats FAQs
Why can’t I see the recognition rate column for all of my audiences?
This feature is only available for Measurement Enablement workflow audiences at this time.
What is a RampID?
A RampID is a pseudonymous representation of an aggregation of touchpoints, representing a person.
How do you determine what is invalid data?
Invalid data are data that we deem unmatchable. For PII files, we check the validity of the identifiers by looking for blanks, bad format, or known invalid email domains, for instance. For files containing devices, we check that the device is not a ‘0’, blank, or a permutation of N/A, nil and null.
Can you point me to which line of data is invalid?
We do not retain this information in the system and we shuffle rows for each file to comply with privacy requirements. It is therefore not possible to point out specific rows that were considered invalid.
How can I prevent my data from being invalid?
For first-party data, make sure that all of the fields are filled, that the identifiers look correct (for instance, you can use an email regex to ensure basic email correctness), and that there are no obvious invalid data points, such as noname@nodomain.com. For third-party data, you can work with your DSP and/or agency to ensure that they do not include blank or ‘0’ devices in their exposure files.
Is anything changing in my file output?
No, this feature is entirely separated from any matching or formatting processes. It is solely a statistics feature and we have not changed the way we process and match files.
What is the difference between recognition rate and match rate?
Almost none. The name "recognition rate" better captures our matching process and our ability to recognize touchpoints by excluding invalid data.
Many LiveRamp customers (as well as many AdTech companies in general) have been seeing a decrease in their MAID (mobile device ID) recognition rates. While LiveRamp continuously works to improve the MAID data in our Identity Graph, we think that this decrease is mostly due to a number of industry changes, including:
Apple’s Application Tracking Transparency framework
Greater consumer access to managing the mobile advertising ID on their devices
New regulations and privacy laws
For more information on each of these issues, see the sections below.
These changes, along with the normal consumer behavior of upgrading devices, mean that we are observing the average lifetime of MAIDs decrease. We expect that there will continue to be more consumer choice in consenting to collect these signals.
For LiveRamp’s match data sources (that we use to build our MAID graph), this means that we have to cast a wider net as we need more data to get the same amount of valid linkages that we had before these frameworks were put in place. We also see a decrease in the longevity of MAIDs as once valid MAIDs are become invalidated through these frameworks. We have been updating our sourcing strategy to counteract these changes.
We also continue to recommend ATS (Authenticated Traffic Solution) as a more forward-looking alternative. For more information, see "Authenticated Traffic Solution".
Apple’s Application Tracking Transparency Framework
Much of this change started when Apple implemented Application Tracking Transparency (ATT), in which a consumer must consent to the tracking of personal information for each application. For many application owners, this resulted in a drastic decrease in the ability to collect and tie a MAID to other pieces of personal information of the consumer (such as email).
The impact doesn’t seem to be as significant if the application is well trusted and respected. In those cases, consumers seem to be willing to opt-in to targeted advertising at a higher rate than an application that is not as well known. However, even for trusted applications the ability to collect this data is still well below what we were observing before ATT was released.
Greater Consumer Access to Managing Mobile Advertising IDs
In addition to ATT’s per-application opt-in, consumers now have much more access to their advertising ID on phones than before. In Android 12 and beyond (which does not employ the same framework as Apple on app opt-in), Google allows users to delete their Advertising ID more easily through their privacy settings, whereas, in the past, this was not easy to do.
New Regulations and Privacy Laws
State regulations and privacy laws are also contributing to the decrease. In Virginia for instance, precise geolocation is now classified as “sensitive data”, which requires special obligations to collect and sell for applications. All of this puts pressure on application owners who provide this type of data.