Onboarding Terms and Concepts
To help make your use of LiveRamp as simple as possible, here’s an overview of the key terms you’ll encounter.
Tip
For fuller descriptions of some Onboarding terms, see the other articles in this section. For a complete list of LiveRamp terms, see our Glossary of All Terms.
Connect
Connect is the cloud-based software application you can use to upload, manage, and distribute your data. Your account manager, or the admin user at your company, will provide you with login credentials. There are many help articles and training videos to help you get started using Connect quickly and easily.
How to Think About the Data You Send Us
There are two basic types of data you can include in files you upload to us:
Identifier data is data that we use to match your records to other identifiers in our Identity Graph.
Segment data is any data that we use to group your records into fields and segments based on certain attributes.
Audience
In LiveRamp Connect, files and segments are stored in "audiences." Audiences are basically just a container for your data, a way to separate and organize different data sets. You will generally have one audience for each workflow, just to keep things organized.
Note
Outside of LiveRamp Connect, "audience" has a different meaning. See the explanation of "Segment" for more information.
All files uploaded to a particular audience must have the same identifier data type, such as PII, cookies, mobile device ID, RampID, and so on.
Note
You might need additional audiences based on your data management needs and based on the types of identifiers (PII-based identifiers vs. device-based identifiers) and audience keys used in the audience data. See "Determining the Number of Audiences to Create" for more information.
For a given audience, all files must have the exact same column headers for the identifier data. This means that, for the columns, we're using for matching (in most cases, the columns containing PII), those columns’ headers must be identical each time.
Caution
Make sure to also take our recommended audience limits into account.
Audience Key
An audience key is a column in your files that acts as a unique ID for all of the records in a given LiveRamp audience. A typical audience key might be client customer IDs, email addresses, or phone numbers. The audience key is used to consolidate duplicate rows in an audience.
Therefore, there are two main criteria for choosing a good audience key:
The key has a high fill rate within records of the audience, preferably as close to 100% as possible.
Caution
If the audience key in an uploaded file does not have a high fill rate, ingestion processing might pause or fail.
Each record within an audience shares its key with as few other records as possible (ideally, the key is unique).
All files must have an audience key, and all files within the same audience must use the same audience key.
If you aren't able to provide a client customer ID (CCID) for your offline data records, we will choose the PII identifier that has the largest fill rate (percentage of records with a value), and that identifier will be used as the audience key for all files in that audience.
If your file includes a name and postal address (NAP) for each record, the audience key will be the combination of the First Name, Last Name, Street Address, City, State, and Zip Code fields.
If your file includes only email addresses (or hashed email addresses) for each record, the audience key will be the email address (or hashed email address).
Caution
Multiple Identifiers Within an Audience: If you send multiple files and use different offline identifiers in each (for example, one file keyed by email and another by NAP), you must provide a CCID as the audience key to link the files. Otherwise, they will need to be processed into separate audiences.
How We Treat Rows with No Audience Key Values
When a row in a file you upload has no value in the field or fields that have been selected as the audience key, we create a placeholder audience key value. This allows us to use the data in that row but impacts our ability to deduplicate rows.
A missing audience key also prevents us from being able to update identifier or segment data on subsequent file uploads (unless the audience uses the "full refresh" option), as the placeholder values we generate are not persistent.
Because of the impacts on our ability to deduplicate rows, having rows with no audience key values might increase your usage.
Field
Within Connect, a field is a set of segment data that holds a specific category of different values. For example, you might have a field called "Car_Owned" that contains segments of specific field/value pairings, such as “Car_Owned:Ford” and “Car_Owned:Tesla”. You can also think of a “field” as the key in a standard key-value pair or as the column heading for a column of segment data.
In general, after you upload a file, LiveRamp creates fields from the columns of segment data in that file.
Within Connect, a field is a set of segment data that holds a specific category of values, such as "Car_Owned."
For example, after LiveRamp ingests a file you upload, the columns in a column-based file become fields that you can manage in Connect (within the audience the file was uploaded to).
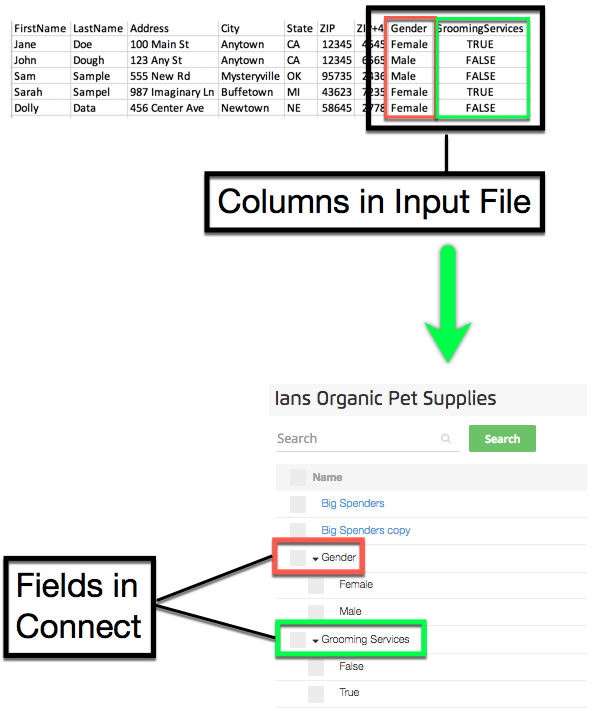
Within a given field, a set of distinct field/value pairings (such as "Car_Owned=BMW") creates a segment.
Caution
A field in a given file that has more than 250 distinct field/value pairings is considered a "raw field" and segments in those fields cannot be enumerated in Connect or distributed to most destinations. Raw fields can often only be distributed by creating derived segments from them in Connect.
Segment
Within Connect, a segment is a group of your records that are defined by a specific attribute, For example, for a field in your file called "Car_Owned", you might have 500 records that have a value of “Ford”. So the segment “Car_Owned:Ford” would contain all the records that have the field/value pairing “Car_Owned:Ford”.
Note
Isn't a segment really an audience? What is referred to within LiveRamp as a segment is often referred to outside of LiveRamp as an "audience." Within LiveRamp Connect, "audience" has a different meaning.
See the following articles for more information:
Value
A specific value for a given field. Think of this as the value in a standard key-value pair or as the column entries for a column of segment data.
Distinct Value
A value or set of values that are distinct from all other values for a given field in a data file.
A field with 250 or less distinct values is considered an "enumerated field", and those distinct values are enumerated (separated out) as segments so that they can be managed individually in Connect (for more information, see "Enumerated Field").
A field with more than 250 distinct values is considered a "raw field", and those distinct values will not be enumerated as segments in Connect (for more information, see "Raw Field").
PII
For many onboarding customers, the primary type of identifier data you’re going to upload is PII, or personally-identifiable information. This refers to a number of possible consumer touchpoints, such as name and postal address, email address, or phone number. PII can be used to identify an individual, either on its own or when combined with some other data.
Note
For EU and UK customers, "personally-identifiable information" (or PII) is called “directly identifiable personal data”.
When this type of data is used as an identifier in a file, it is usually referred to as a "PII identifier." LiveRamp uses PII identifiers to match records in your files to the data in its Identity Graph.
Note
PII-based files are often referred to as "offline data" files, because that data is often (but not always) collected in the offline world. This type of data can be used to directly identify an individual so it is categorized as "known" data.
Online Data
Some customers might send “online data” such as cookies, mobile device IDs, or their custom IDs. Because this type of data can’t be used to directly identify an individual on its own, these data are categorized as "pseudonymous" data.
Destination Account
A destination account at LiveRamp is a set of configurations that allow you to distribute data to a particular seat (or account) at a destination.
Distribution
When you select segments to distribute to a destination account, that creates a “distribution”. LiveRamp then delivers the data to the destination, and then refreshes that data periodically. See “How LiveRamp Refreshes Distributed Data” for more information.
First-Party/Second-Party/Third-Party Data
When we use these terms, we mean:
First-party data is data that you’ve collected yourself
Second-party data is data that a partner has shared with you
Third-party data is data that you’ve purchased from a third party