Getting Started with LiveRamp Clean Room for Publishers
LiveRamp Clean Room connects publishers to their data assets, enabling collaboration across the ecosystem:
Interoperable: Collaborate in one place with your brand partners globally, no matter the cloud
Flexible: Supports code-based analytics for technical users and no-code UX for business users to generate insights and reporting
Actionable: Turn insights into action with identity-powered activation to 350+ destinations
LiveRamp Clean Room Overview
A clean room is a secure environment that enables data collaboration across decentralized datasets to help uncover actionable insights and outcomes.
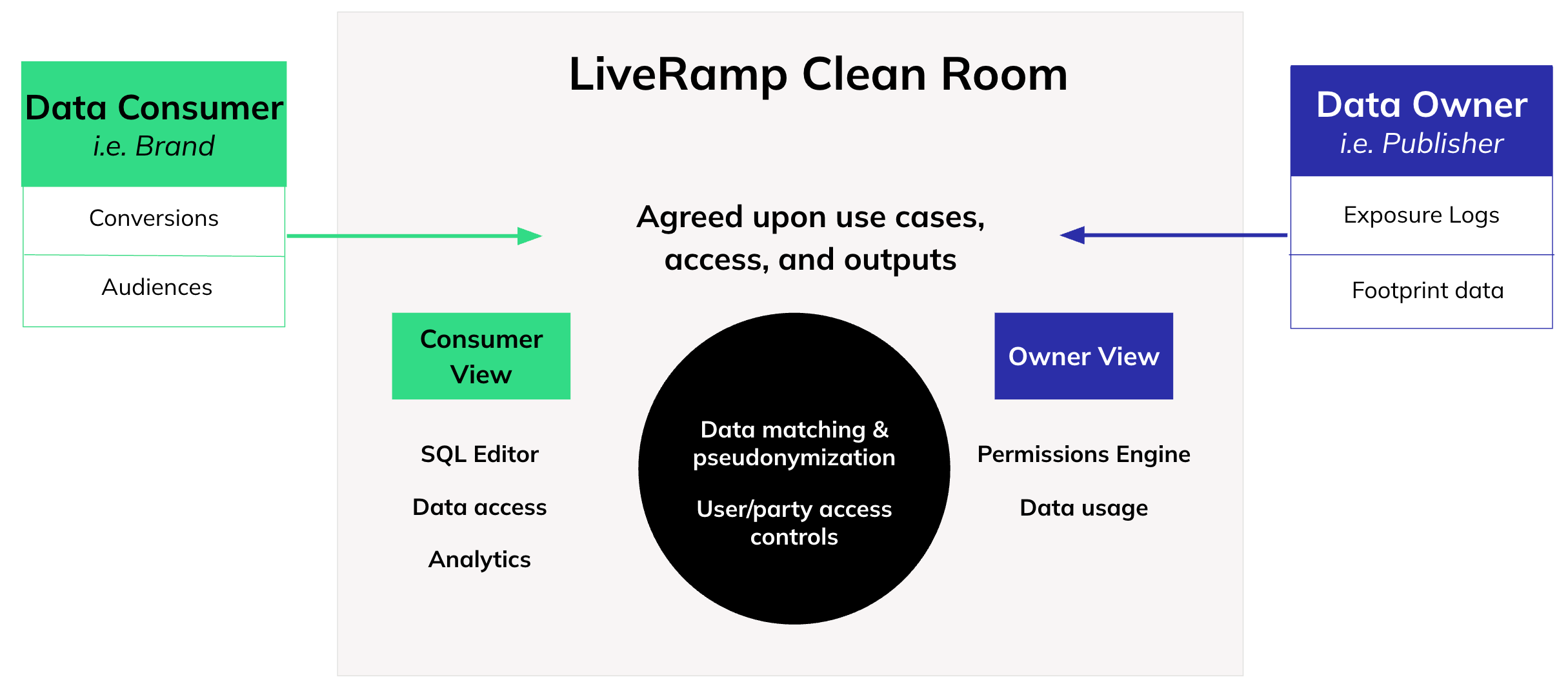
LiveRamp Clean Room enables the creation and ongoing support of clean room collaborations through a user-friendly interface.
Included in LiveRamp Clean Room's architecture are three core layers:
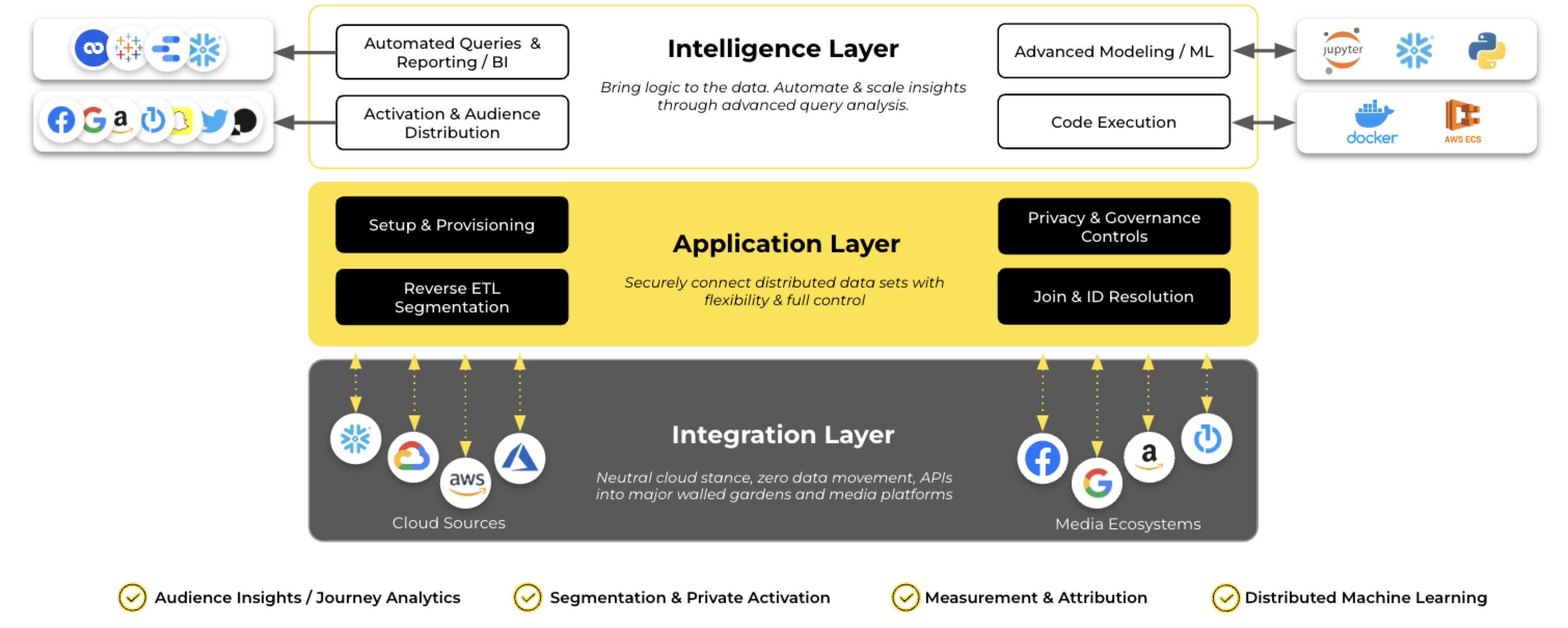
The Integration Layer, where we integrate with cloud and media ecosystems to access data at its source. This layer provides foundational support for use cases ranging from reporting insights to user list creation, complex modeling, and more.
The Application Layer, which enables teams to automate dataset workflows and define and enforce governance rules and privacy controls for multi-party collaborations.
The Intelligence Layer, where analytics and insights can be templatized, visualized, and automated.
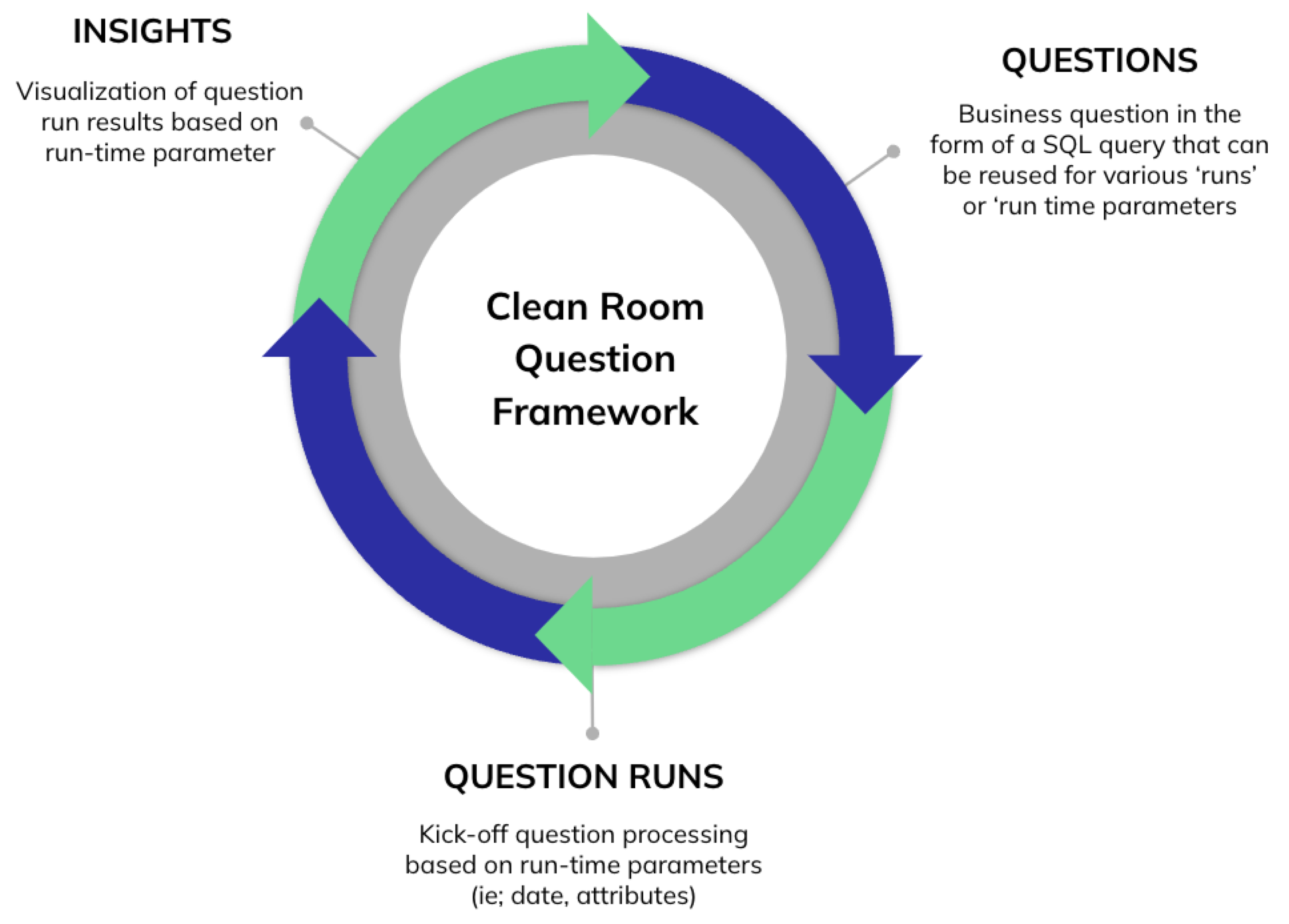
LiveRamp Clean Room's architecture lays the foundation for LiveRamp Clean Room's question framework, which drives insights consumed from clean room outputs.
 |
Key Terminology
The following terminology will help you get up to speed on navigating the LiveRamp Clean Room UI:
Clean room: Secure, protected environment that allows multiple parties to bring data together for joint analysis in a privacy-compliant way.
Data connection: Used to access data at its source to minimize data movement.
Question: A business question in the form of an SQL query that can be reused for various runs or run-time parameters.
Question run: Question processing based on runtime parameters, such as dates and attributes.
Insights: Visualizations of question run results based on runtime parameters.
Roles and Responsibilities
As a partner collaborating in a clean room, there are several important steps required to properly onboard your data, often requiring members of key teams across your organization. Collaborations work best when people are aligned to roles across the clean room partner, clean room owner, and LiveRamp.
To get started, identify people in your organization that align best with the following clean room partner roles shown in the table below.
Roles | Responsibilities | |
|---|---|---|
Clean Room Partner | Account and Organization Admins |
|
IT / Data Team |
| |
Marketing / Marketing Analytics |
| |
Data Scientist / Data Analyst |
| |
LiveRamp | Client Success Manager |
|
Technical Solutions Manager |
|
Overall Implementation Steps
Getting started with LiveRamp Clean Room for publishers typically involves the following overall steps:
You sign the required agreements.
You work with the LiveRamp Clean Room team on making key implementation decisions.
Set up your account and add users.
If desired, test in a sandbox environment with synthetic data.
For more information on performing these overall steps, see the sections below.
Required Agreements
When adopting LiveRamp Clean Room, LiveRamp requires their Clean Room publishers to agree and sign the following contracting documents between the publisher and LiveRamp:
LiveRamp master services agreement (MSA) with clean room partner requirements
LiveRamp Data Processing Addendum (DPA)
LiveRamp statement of work (SOW) with addendum A, which offers a standardized legal framework for collaboration (Quick-Start Insights).
For advanced data collaboration use cases and features, publishers often require their own terms and conditions to be agreed upon with the brands. Those agreements need to be agreed between the parties before the collaboration.
Key Implementation Decisions
After you've signed the required agreements, your LiveRamp representative will work with you on the implementation decisions listed below, based on your situation and business needs.
Choose Clean Room Offerings
Establish your technical integration with LiveRamp Clean Room once to collaborate frictionlessly across the LiveRamp network and use any of our clean room-powered offerings. This includes:
Code-based workflows for data science and technical teams, which connects a brand and an individual partner (such as a publisher, CMN, or data seller) for custom collaboration (sometimes referred to as “1:1 custom collaboration”).
No-code access via LiveRamp’s Intelligence layer, designed for business users with pre-built queries and dashboards to accelerate time to insight. Quick Start offerings, which are part of the Intelligence layer, include:
Media Intelligence: Connects a brand and an individual publisher
Retail Intelligence: Connects a brand and a RMN (plus optional publisher overlay)
Choose Where Data Will Be Hosted
One of the first decisions to make when implementing the LiveRamp Clean Room is identifying where the data will be hosted:
Connecting to data at the source (such as your cloud warehouse)
Connecting to data you’re already sending to LiveRamp
Sending the relevant data to LiveRamp to host
This decision is not mutually exclusive of where identity resolution happens. For some clients, identity resolution may happen in the LiveRamp-hosted environment. However, the data can still be connected at the source. Your account team can assist with tradeoffs between these scenarios.
Option | Details | Benefits |
|---|---|---|
Direct connection to the data source | Data connections can be configured to most cloud-based storage locations, including AWS, GCS, Azure Blob, Snowflake, Google BigQuery, and Databricks. For more information, see "Connect to Cloud-Based Data". | It can provide flexibility, specifically with data updates, deletion of data connections, and troubleshooting. |
LiveRamp hosting | Sending data to LiveRamp can be executed through SFTP or by setting up a connection to your S3 or GCS buckets. For more information about sending data to LiveRamp, see "Getting Your Data Into LiveRamp". | For customers with existing data feeds with LiveRamp, this offers a seamless way to get started with LiveRamp Clean Room. |
If you choose to connect to your data at source, you’ll need to gather the following prerequisite information:
Prerequisite | Notes |
|---|---|
Identify where your data is stored and in what region | LiveRamp Clean Room is interoperable and supports all major clouds, including:
|
Identify the credentials associated with your cloud instance | For example:
|
Identify the region, file format, and file path associated with your configuration | For example:
|
Identify the dataset types you will be bringing into LiveRamp Clean Room | For example:
For information on formatting each dataset type, see the "Data Formatting for Collaboration" section. |
Identify the user identifier used for matching in LiveRamp Clean Room |
Choose How to Incorporate Identity Resolution
Once you’ve determined how to connect your data to power LiveRamp Clean Room collaboration, the next step is configuring your identity resolution workflow so that your data can be mapped to RampIDs, LiveRamp’s universal, pseudonymous identifiers.
Connecting your data in LiveRamp Clean Room with RampIDs as the join key maximizes the value, ensuring the highest fidelity view can be connected across various identifier types across your partners. For more information on RampIDs, see “RampID” and “RampID Methodology”.
Note
All RampIDs are given a “partner encoding” so that they are unique to the partner using them (this encoding is a 4-digit number that appears as part of each RampID’s value). LiveRamp hybrid clean rooms automatically translate between encodings for each collaboration partner to ensure seamless interoperability and reduce the risk of re-identification.
LiveRamp has the following recommended options for identity resolution (depending on your goals) and will guide you through the process of deciding which will work best for you:
Identity Resolution in LiveRamp Clean Room: You connect your universe dataset (keyed off of CIDs) in your cloud provider to LiveRamp Clean Room and LiveRamp then uses the included identifiers for matching to create an additional linked dataset that maps the provided CIDs with their associated RampIDs. This linked dataset is then used in questions to join datasets on RampIDs. For more information, see "Getting Started with Identity Resolution in LiveRamp Clean Room (US Data)".
Embedded Identity Resolution in your Environment: You use LiveRamp's Embedded Identity in Cloud Environements to resolve your data in Snowflake, AWS, or BigQuery to RampIDs. When you connect this data to LiveRamp Clean Room, the associated datasets can then be joined on RampIDs. Contact your account team for more details or see "Embedded Identity in Cloud Environments".
Identity Resolution in LiveRamp Clean Room: You connect your universe dataset (keyed off of CIDs) in your cloud provider to LiveRamp Clean Room and LiveRamp then uses the included identifiers for matching to create an additional linked dataset that maps the provided CIDs with their associated RampIDs. This linked dataset is then used in questions to join datasets on RampIDs. For more information, see "Getting Started with Identity Resolution in LiveRamp Clean Room (US Data)".
Note
If you already have data in your Connect account, work with your Implementation team to determine which of that data you need access to in Clean Room and they'll make that available.
To determine the best data hosting and identity resolution option for your business, you may need to mix and match solutions. For custom needs, including Local Encoder customization, consult your account team.
Choose How to Partition Large Datasets
LiveRamp enables you to indicate partition columns for your data connections in order to optimize query performance. Data partitioning is the process of dividing a large dataset into smaller, more manageable subsets. For partitioned data connections, data processing occurs only on relevant data during question runs which leads to faster processing times.
As a best practice, we recommend you partition the following fields for publisher measurement use cases:
Exposure date or impression date (for exposure or impression data)
Date or timestamp (for transaction or conversion data)
Brand (if applicable)
For more information, see "Partition a Dataset in LiveRamp Clean Rooms".
Set Up Your Account
Account or organization admins can create additional users and assign them roles. Each newly created user will receive a welcome email to log into LiveRamp Clean Room. Their access level will mirror the role you have assigned them.
Note
Adding users to an organization does not mean these users have access to a configured clean room. Adding users to a clean room is a separate step.
Set Up SSO
To enable SAML-based SSO for LiveRamp Clean Room access to your account, follow the instructions in "Enable Single Sign-On for LiveRamp Applications".
Manage User Roles
As part of LiveRamp Clean Room organization configuration, account and organization administrators can manage and add new user roles. Roles are combinations of Clean Room permission sets that can be assigned to individual users within an organization.
Clean Room provides a set of optional default roles that can be used as a starting point when setting up your permission structure. To access default roles, from the Administration area of the navigation menu, select Clean Room Configuration → Clean Room Roles to open the Organization Roles page. Default roles can be edited or deleted.
For more information, see "Managing LiveRamp Clean Room User Roles".
Add Users
Once your account administrator has access to the LiveRamp Clean Room UI, they can create additional users. There is a separate flow for adding users to the UI versus adding users to a clean room.
For more information on general file formatting guidelines, see "Data Connection Requirements and Best Practices".
Test in a Sandbox Environment with Synthetic Data
To help users get real hands on keyboard skills within the Clean Room UI, LiveRamp will provide a sandbox environment to serve as a mock environment for experimentation. This clean room will consist of sample data and sample queries to help guide your team to learn the platform.
Your LiveRamp Client Success Manager will work with you on the testing process.
Format Your Data for Collaboration
LiveRamp recommends specific data schemas for each dataset to be used in clean room collaboration. The fields listed in the schemas below can be used to produce measurement results for the following clean room use cases (these will have pre-written queries for your use):
Audience Analytics
Overlap of brand data against publisher data
Audience Profiles
Media Delivery
Reach / Frequency
Impressions delivered across audiences, channels, platforms, campaigns, etc.
Attribution
Conversion counts
Lift
See the sections below for information on formatting your data, including the recommended schema and format for each dataset type you might need to connect to LiveRamp Clean Room.
While not all fields might be required for your current workflows and collaborations, we recommend you include as many of these additional fields now (with the specified field type) to make it easier for you to expand your collaborations in the future without you (or your IT team) having to perform additional work on your datasets.
The recommended field names shown aren’t mandatory, but using the recommended names can reduce the number of transformations you and your collaborators might need to do during dataset provisioning or query writing.
Note
If it's not practical to prepare your data to match the fields and field types listed in these schemas, you can connect your data and then create a view of those datasets to match the schema requirements. For more information, see "Create a Dataset from a View of Data Connections".
For more information on general file formatting guidelines, see "Format Your Clean Room Data".
If you’re utilizing LiveRamp Embedded Identity in your cloud environment, the formatting guidelines are somewhat different. For more information, see “Embedded Identity in Cloud Environments” in our Identity docs site.
All data files or tables in a data connection job must have the same schema in order to be processed successfully. If you have multiple types of schemas, create a new data connection for each one. The order of the columns should match the schema.
Recommended Dataset Types for Publishers
When preparing data for collaboration, consider the following recommended dataset types:
Universe dataset: This represents your full audience and likely includes all user identifiers (PII touchpoints or online identifiers) that will be used to resolve your data to RampIDs.
Impressions dataset: Includes data on impressions served or other ad events, along with metadata on the impressions or events.
Publisher audience dataset: For publishers, this includes data on user segments in your platform.
All datasets should include a field for a CID (a unique customer identifier you leverage for deduplicating individuals across your datasets):
For PII-based universe datasets, we recommend that plaintext CIDs (not hashed) be sent (if you must hash the CIDs, we ask that you consistently use the same hashing for CIDs in other datasets for interoperability).
For all other datasets (including universe datasets based on online identifiers), if you sent plaintext CIDs in your universe dataset, send MD5-hashed CIDs. If you hashed the CIDs in your universe dataset, use the same hashing type.
Identity Resolution Option | Dataset | Inputs | Identity Resolution Results | Update Cadence |
|---|---|---|---|---|
File uploads | Universe data |
|
This resolved view will be applied to impression data as it comes through | For most publishers, this dataset will need to be refreshed monthly |
Event / Impression data |
|
| If sending data through file uploads, send frequent updates for use in LiveRamp Clean Room | |
Embedded identity (cloud hosted) | Universe data |
|
| For most publishers, this dataset will need to be refreshed monthly |
Event / Impression data |
| N/A, the data can be used in the data connection directly | If connecting to data at source, ensure the data connection will update with new information |
Format a Universe Dataset (US Data)
Before creating the data connection for your US data universe dataset, make sure it’s formatted correctly.
Note
For information on formatting a non-US data universe dataset, see “Format a Universe Dataset (Non-US Data)”.
The universe dataset should represent your full audience and should include all user identifiers (PII touchpoints and/or online identifiers) that will be used during identity resolution to resolve to Known IDs and RampIDs.
Note
Only PII touchpoints (such as name, postal, email, and phone) will be used to resolve to Known IDs. PII touchpoints and online identifiers (such as cookies, MAIDs, and IP addresses) will be used to resolve to RampIDs.
LiveRamp uses this dataset to create a mapping between your CIDs and their associated LiveRamp identifiers (Known IDs or RampIDs). These mappings live in two linked datasets and allow you to use Known IDs (for marketing use cases) or RampIDs (for advertising use cases) as the join key between each partner's datasets in queries.
When formatting your universe dataset, multiple identifier types (including PII, hashed email, and MAIDs) can be included in the same dataset. The examples below can be used for the specific situations listed but you can create a dataset that uses any combination of these identifiers. See the table below for a list of the suggested columns for a universe dataset containing plaintext PII, hashed emails, and MAIDs.
For information on formatting and hashing identifiers, see “Formatting Identifiers”.
Note
When sending PII, it’s important that as many PII touchpoints as possible are provided for LiveRamp’s identity resolution capabilities to yield the best results.
You do not need to include columns for any identifiers that you’re not including in the dataset.
You do not need to include any attribute data columns (or any other non-identifier columns), since these will not be needed for identity resolution and will not be retained in the resulting CID | Known ID and Hashed CID | RampID mapping datasets. Removing attribute columns can help with faster processing times.
Your CRM dataset might also be able to function as a universe dataset.
Datasets that will be used in identity resolution must not contain BOM characters. For more information, see “Removing BOM Characters”.
Field Contents | Recommended Field Name | Field Type | Values Required? | Description/Notes |
|---|---|---|---|---|
A unique user ID | cid | string | Yes |
|
Consumer’s first name |
| string | Yes (if Name and Postal is used as an identifier) |
|
Consumer’s last name |
| string | Yes (if Name and Postal is used as an identifier) |
|
Consumer’s address |
| string | Yes (if Name and Postal is used as an identifier) |
|
Consumer’s additional address information |
| string | No |
|
Consumer’s city |
| string | No |
|
Consumer’s state |
| string | No |
|
Consumer’s ZIP Code or postal code |
| string | Yes (if Name and Postal is used as an identifier) |
|
Consumer’s best email address |
| string | Yes (if email is used as an identifier) |
|
Consumer’s SHA-1-hashed email address |
| string | No |
|
Consumer’s SHA256-hashed email address |
| string | No |
|
Consumer’s MD5-hashed email address |
| string | No |
|
Consumer’s best phone number |
| string | Yes (if phone is used as an identifier) |
|
Consumer's mobile device ID (MAID) |
| string | Yes (if MAIDs are used as identifiers) |
|
Format an Exposures Dataset
An exposures dataset should include data on impressions served or other ad events, along with metadata on the impressions or events.
Note
If you do not have values for any fields in this schema, we recommend that you still include those fields as placeholders.
Field Contents | Recommended Field Name | Field Type | Values Required? | Description/Notes |
|---|---|---|---|---|
A unique user ID | cid | string | Yes |
|
UTC timestamp of the event | event_timestamp | timestamp | Yes |
|
Unique ID for the creative served | creative_id | string | No |
|
Name of the creative | creative_name | string | No | |
Unique ID for the placement, ad group, adSet, or line item ID | placement_id | string | No |
|
Name of the placement, ad group, or line item | placement_name | string | No |
|
Unique ID for the campaign | campaign_id | string | No |
|
Name of the campaign | campaign_name | string | No |
|
Unique ID of the publisher or site where the exposure occurred | property_id | string | No | |
Location on a publisher site, the channel, or media type where the exposure occurred | property_name | string | No | |
Segment ID that the user belonged to at the time of exposure | segment_id | string | No | |
Unique ID for the advertiser account | account_id | string | No |
|
Name of the advertiser account | account_name | string | No |
|
Unique ID for the brand | advertiser_id | string | No | |
Name of the brand | advertiser_name | string | No |
|
Type of placement or line item | placement_type | string | No | |
Type of event | event_type | string | No |
|
Cost of the event to the advertiser | cost | double | No |
|
Unique identifier for the event | event_id | string | No |
|
Format a Publisher Audience Dataset
For publishers, a publisher audience dataset includes data on user segments in your platform.
Field Contents | Recommended Field Name | Field Type | Values Required? | Description/Notes |
|---|---|---|---|---|
A unique user ID | cid | string | Yes |
|
Unique identifier of audience segment used for targeting this impression | segment_id | string | ||
The name of the segment | segment_name | string | ||
The name of the category | segment_category | string |
Connect Your Data
Once you've confirmed that you have the required datasets ready for use, you're ready to connect your data. If you’re going to be hosting your data at its source in a cloud warehouse, you’ll need to connect that data to your Clean Room account.
Note
If you’ve chosen to have LiveRamp host the data, see the information in “Uploading Data”.
Before configuring your data connections in LiveRamp Clean Room, confirm you have the required datasets ready for use in a clean room. Knowing where your datasets live, the credentials and tables required to access those datasets, and having the proper file and table formatting in place will make the remainder of your setup much more seamless.
Connecting your data involves creating a data connection by performing the overall steps listed below. The type of connection to create will depend on your situation and business needs. Your LiveRamp representative will work with you to determine the type(s) of connections to create.
For more information on the steps to perform for your cloud provider and clean room type, see the articles in “Connect to Cloud-Based Data”. Specific instructions for each step will be listed in the appropriate help article for your data connection type.
A data connection needs to be created for each dataset you want to utilize in a clean room.
After you create data connections, these connections appear on the Data Connections page, and you can create and configure clean rooms.
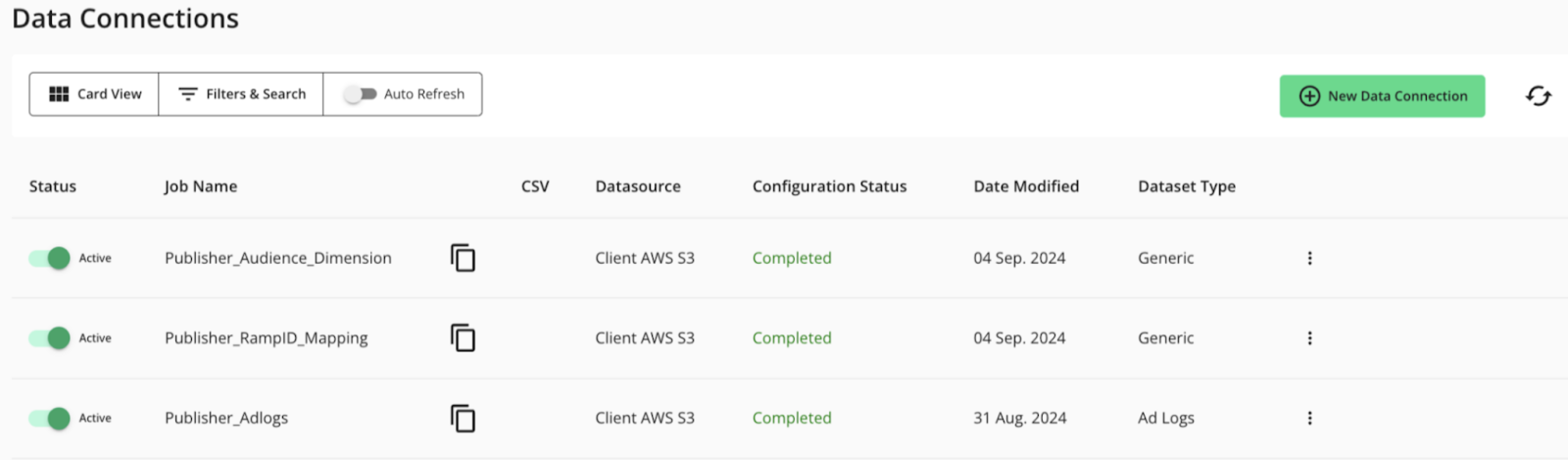
Perform Actions in the Cloud Provider UI
For certain data connections, you’ll have to perform tasks in the cloud provider’s UI. This often involves things like downloading credentials, creating service keys, granting permissions, generating a token, or other similar actions.
Add Credentials
For LiveRamp to be able to access your data at your cloud provider, you’ll need to create a credential within LiveRamp Clean Room for that cloud account. This often involves entering a credential or token you generate from your cloud provider.
Create a Data Connection
Once you've created the appropriate credentials, you can create the data connection itself. During this process, you’ll also specify things like the file path LiveRamp should use to access your data, the file format, the field delimiter, and the data location.
Map the Fields
Once you’ve created the appropriate data connection and LiveRamp has successfully connected to your data, you then map and configure the fields. This includes specifying which fields you want to be queryable, any updates to column labels, which fields contain PII, and which fields should be used as identifiers.
Create and Configure Clean Rooms
After you've connected your data, you're ready to perform any necessary steps to create and configure clean rooms by performing some or all of the overall steps listed below (depending on your situation).
Note
If you're going to be creating multiple clean rooms that will use the same questions, datasets, or other configurations, consider creating a clean room template and then generating clean rooms from that template. You can also generate a template from an existing clean room or add a template's items to an existing clean room. For more information, see "Using Clean Room Templates".
For instructions on performing these steps, see the links above and the following articles:
Invite Clean Room Partners
Facilitating clean room collaborations requires clean room owners to invite partners to a clean room to combine and analyze data sources from multiple parties.
Note
Any partner you want to invite must have already set up their LiveRamp Clean Room account. Send the invitation to a user with Organization Administrator permissions who can then accept the invite on behalf of the partner organization in the clean room.
For instructions, see “Invite a Partner to Your Clean Room”.
Collaborate on Clean Room Questions
Once you and your partners are up and running in the clean room, you're ready to collaborate. See the information in the "Collaboration Guides" section of our documentation site for articles to help you with collaboration activities.